有几个误区是要先澄清的。
一,HFT不一定是套利算法。事实上HFT做的最多的业务是做市(market making),可以是把商品从一个交易所倒卖到另一个交易所,也可以是在同一个交易所内部提供某种商品的流动性。这两种方式的共同点都是让人们可以特定地点买到本来买不到的商品,所以本身就是有价值的,收服务费就可以盈利。参见我在什么是高频交易系统?这个问题下的回答。
二,延迟和流量是不同的概念。低延迟不等于高数据量,事实上大部分时间交易数据流量并不大,一个market一天最多也就几个GB。但HFT系统需要在流量高峰时也能快速响应,所以更看重延迟。这也是HFT系统和互联网系统最大的区别所在,HFT系统的精髓在于把单机的软硬件系统的性能发挥到极致,而不是像互联网那样强调高负载和延展性,动辄用几千台机器搭集群的做法在这里是不适用的。用互联网系统的性能指标来认知HFT系统也是没有意义的,像淘宝这样的应用需要保证交易的正确和一致性,包括从终端用户的浏览器到淘宝后台到银行接口之间一系列复杂的事务性数据操作,这个场景和HFT直接对接交易所走高速线路收发交易指令有天壤之别,不能用同样的思维去理解。
三,一个HFT业务包括从主机到交易所的整条通信线路,在这条线路上有很多段不同的延迟,是需要分开讨论的。如果是做跨交易所的交易,首先需要考虑的是两个交易所之间的网络延迟。当数据通过网络到达主机的时候,有一个最基本的tick-to-trade延迟,是指主机接收到数据到做出响应所需的时间。但这个东西的测量很有技术含量,根据不同的测量方式,它可能包括或不包括网卡及网络栈的处理时间。所以拿到一个HFT系统的延迟数据时,首先要搞清楚它指的是什么,然后再来讨论。
题主提到从一个直连计算节点的router的角度来观测,这是一个理论上看起来可行但实际仍然很模糊的概念,因为一般router本身是不做存储和处理的,一个router会收发大量不同的数据,要理解一个接收到的包是对之前发出去的某个包的“回应”,是需要相当的处理逻辑的,一般很难这样测。比较合理的测试仍然是在主机端做记录,测试从收到市场数据(tick)的TCP/UDP包到发送交易指令(trade)包的时差。目前(2014)的情况是,这个延迟如果平均控制在个位数字微秒级就是顶级了。因为网络传输才是延迟的大头,如果网络上的平均延迟是1毫秒(1000微秒)以上,你的单机延迟是2微秒还是20微秒其实是没有区别的。一般单机比网络低一个数量级就可以了,比如网络上需要100微秒(很现实的数字),单机控制在10微秒足以保证速度上没有劣势。至于公众报道,有时是为搏人眼球,难免有夸大的成分,不必太当真。
接下来说说做为一名从业者,我对各个层面的理解。
首先网络架设上光纤肯定是最差的方案。国外几个主要的交易所(同一洲内)之间基本上都有微波(microwave/milliwave)线路,比光纤的延迟要低很多,延迟敏感的应用一定要选择这种线路。这个差距首先受制于光在光纤中的传播速度只有在空气中的2/3左右,另外在大城市建筑密集地区(也正是一般交易所的所在地),光纤的复杂布线会进一步增大延迟,差距可能增至2到3倍。要想对此有一个具象的概念,只要看Quincy Data的这张线路图:
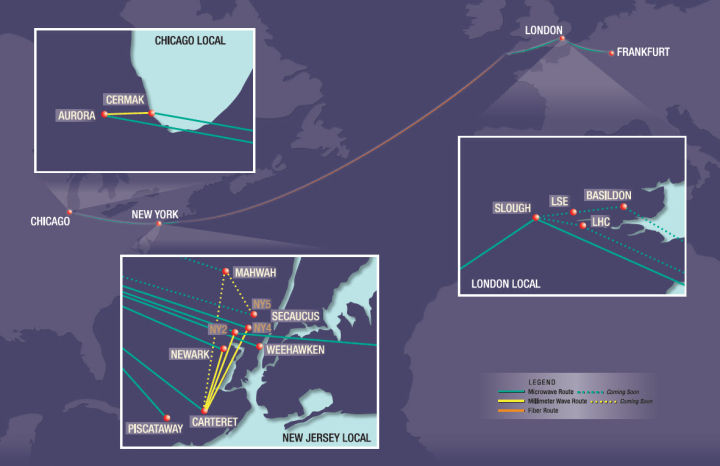
但微波技术有两个主要的缺点,第一是微波在空气里传播受天气影响很大,刮风下雨都会导致通信受损,有时直接故障,所以需要备用的光纤线路,以及监控天气…… 这方面进一步的发展可能是激光技术;第二是带宽太小,如果是跨交易所的业务,不可能通过微波来转移大流量的市场数据,只能用来收发下单指令,这方面有一些潜在发展空间,比如可以做一点有损压缩,传一个缩减版的市场数据,也能起到加快信息传递作用。这块网络服务本身就是一个**的业务了,一般所说的colocation也是由服务商负责的,HFT主要需要的是选择适合自己的服务商。
网络线路确定以后,数据就送到了HFT主机。这时候需要决定网卡的方案,专用的网卡除了自身硬件的设计外,一定需要的是切换掉系统自带的kernel space TCP/IP stack,避免昂贵的context switching。网络栈上的I/O延迟,收包发包加起来做到2~3微秒是可以的。这个层面上FPGA是很有应用价值的,因为可以做一些额外的逻辑处理,进一步解放CPU。
对于FPGA,我同意@Nil的回答,业务逻辑烧到硬件里的开发,调试成本和周期都是很难承受的,不看好做为长期发展的路线,这个东西其实和套利,数学模型一样是赚外行眼球的东西。但做专用的网络I/O设备却是比较有优势的。(这里可以另举一个例子以供思考FPGA的特点和适用性,目前很多主流交易所的技术架构上,为了适应高速交易的需要,市场数据是采取UDP双通道的方式发放的,即同一份数据发到两个UDP broadcast channel上。客户端需要自行收发排序,大家可以思考一下这种数据要如何编程才能高效稳定的处理,开发过程需要如何调试测试,如果数据协议发生变化要如何处理?FPGA在这种场景中又该如何应用?这当然是开放问题,但是应该有助于理解真实的需求。)
网络部分的问题解决以后,最后就是核心的业务逻辑的处理。这部分也许会用到一些数学建模,但是没有什么神话,不是什么菲尔兹奖得主才能搞的东西(那些人的用武之地更多是去投行那边做衍生品,那才是真正需要高等数学的东西)。很多时候核心的还是延迟,这个在计算机内部分两个部分,一是core的使用率,比如irq balance,cpuisol,affinity等,主要是要尽可能的独占core;另一个是cache invalidation,从L1/L2/L3 cache到TLB,page fault,memory locality之类都要仔细考虑,这个更多考验的是对体系结构的理解和程序设计的功力,跟语言的关系不大。
具体选择那种语言,首先是取决于公司的技术积累和市场上的技术人员供给。函数式语言(erlang/ocaml等)的好处是语言表达能力强,开发速度快,逻辑不容易出错,但相对的对机器底层的控制差一些,有时候他们的编译器或运行时干了什么不太容易搞清楚,所以在性能上的调优会比在C++之类投入更多一点,这里面有一个取舍问题,要根据公司情况来具体分析。
业务逻辑部分其实相当简单。做这种高速交易肯定不会有什么凸优化,解微分方程之类复杂的运算。核心的部分一般就是加加减减,比比大小什么的。业务逻辑本身的处理完全可以做到纳秒级,如果看到有人宣称他们的延迟是纳秒级,一般是指这种。
操作系统同样是一个不需要神话的东西,普通的linux已经有足够的空间用来做性能优化。简单说,一个企业级的linux(如redhat)加上通用的架构(intel主流处理器)足以做到市面上已知的最低延迟,不必幻想有什么奇妙的软硬件可以做到超出想像的事情。
另外需要提醒大家注意的是,其实做一个低延迟系统,首先需要考虑的不一定是延迟能降到多低,而是怎么测量系统的延迟?对一个HFT系统来说,所谓的tick-to-trade延迟,一定要有既精确又不影响系统性能的测试方法才有意义。可以想像一下,最理想的测试场景一定是你的系统真正运行在直连交易所,有真实的市场数据传入的情况下,并且测试的代码就是真正的交易算法时,得到的数据才有意义。如何得到这个苛刻的测试环境,以及如何测量系统的各个部分的延迟,是一个非常有技术含量的工程,难度往往并不亚于系统设计本身。
最后说点题外话,技术发展是非常快的,在这个时代没有什么秘密能永久保鲜,HFT/low latency trading也不例外。现在欧美在这方面的市场已经逐渐趋近饱和,毕竟软硬件的性能都是有上限的,当大家都能达到微秒甚至纳秒级时,仅仅靠拼速度就没那么大优势了。目前虽然拼速度仍然有盈利空间,但是长远来看一定需要在保证速度的基础上增加算法智能性和系统稳定性,从这个角度上说像把全部算法都烧进FPGA的做法是很难维持的,开发周期和成本都太高了。接下来真正有挑战的应该是高速系统和大数据的结合,这应该是一个很有想像力的空间。
参考资料:
Barbarians at the Gateways
Online Algorithms in High-frequency Trading
Ultra Low Latency Wireless Solutions
Get the facts on the FPGA Order Book
TCP Bypass
Don't bother joining the low latency arms race, say low latency traders
