在上一篇文章中,我们已经看到了SHA256算法的具体流程,但是对背后的原理却知之甚少。从宏观上看,SHA256算法是:
将很长的信息,最长是2^64bit,变成仅仅只有256bit的信息,类似于给每个原始信息加了指纹。
需要满足以下几点安全性质:
1. 不能从SHA256结果得到原始信息,也就是密码学中的原像问题。
2. 不能出现两个不同的原信息,但是SHA256结果一样,即碰撞问题。
3. 最好由原信息的微小变动能让SHA256结果面目全非,即雪崩效应。
(当然还有第二原像问题,可以直接参见《密码学原理与实践》第四章)
而上一篇介绍的SHA256的流程就是为了达到这些目的。
首先思考一下,如果把一个很长的信息,比如1000万bit(当然远远小于2^64)的信息直接压缩成256bit的信息,这是非常难的,但是呢,如果可以分组压缩,比如把不管多长的数据,都分成很多组,比如是N,每组信息长度一定,比如是L,如果一个函数是将长度差不多是L的信息压缩成256bit,然后将这个N组压缩之后的256bit经过求和得到最终的256bit作为结果,这样的话,就具有通用性了。这里面需要解决几个问题:
1. 将长度差不多是L的信息压缩成256bit的函数,最好具备上面所需的3个特点,比如不能产生碰撞
2. 即使这个压缩函数已经存在,但是也要保证,函数通过分组压缩的方法,得到的结果也是保持函数的特性,比如不能让一个不产生碰撞的函数经过分组加密处理之后变成了很容易产生碰撞。
其中,所有能解决第2个问题的构造方法,就叫Merkle-Damgard结构。注意,Merkle-Damgard结构构造出来的函数满足所有安全性质的前提是,第1个问题说明的压缩函数必须满足所有安全特性。在《密码学原理与实践》第四章中提出了两个满足Merkle-Damgard结构的构造方法,具体证明过程可以直接看此书,在了解了目的的情况下证明过程很易懂,这里不再赘述。
假设你已经阅读了相关的构造和证明过程,接下来我们看一下SHA256算法,怎么满足了Merkle-Damgard结构。这部分建议对照书中的证明过程阅读。
很显然,满足的是书中算法4.6构造的结构,t >= 2的情况。其中,t = 512,是每组长度,m = 160,压缩函数是把长度m + t的信息压缩到了m,即从160 + 512压缩到了160。 证明中每组长度是t – 1,但是这里每组长度是t。在书中密码体制4.1中,补位结束之后,循环里面,其实就是compress函数,传入的参数是(H,W)。如下:
for i in range(1, N + 1):
# compress函数开始
W = [0] * 64
for t in range(0, 64):
if t < 16:
W[t] = M[i][t]
else:
W[t] = SSIG1(W[t - 2]) + W[t-7] + SSIG0(W[t-15]) + W[t-16]
a = H[i - 1][0]
b = H[i - 1][1]
c = H[i - 1][2]
d = H[i - 1][3]
e = H[i - 1][4]
f = H[i - 1][5]
g = H[i - 1][6]
h = H[i - 1][7]
for t in range(0, 64):
t1 = h + BSIG1(e) + CH(e, f, g) + K[t] + W[t]
t2 = BSIG0(a) + MAJ(a,b,c)
h = g
g = f
f = e
e = d + t1
d = c
c = b
b = a
a = t1 + t2
H[i][0] = a + H[i - 1][0]
H[i][1] = b + H[i - 1][1]
H[i][2] = c + H[i - 1][2]
H[i][3] = d + H[i - 1][3]
H[i][4] = e + H[i - 1][4]
H[i][5] = f + H[i - 1][5]
H[i][6] = g + H[i - 1][6]
H[i][7] = h + H[i - 1][7]
# compress函数结束
传入参数,可以当做是H||1||W,在conpress函数中再切分。
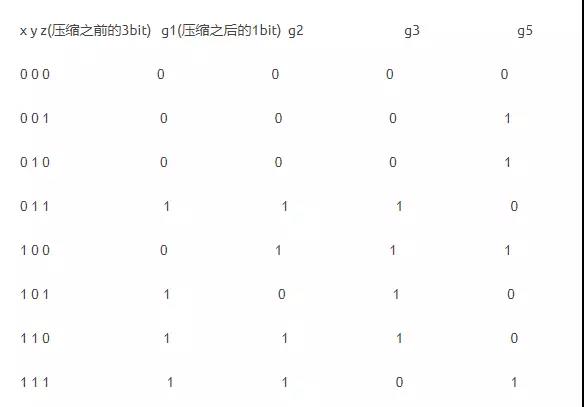
对于上文中的conpress函数,其实不能严格证明就是不发生碰撞的, 而且事实上已经找出一部分碰撞了。这些逻辑操作,比如右移,循环移位,加法,异或(其实就是模2加法),应该是受到代换密码体制或者置换密码体制的影响,因为所有加密,要么就是打乱bit位顺序要么就是替换bit位。其中起到压缩的是内循环的64轮操作,其中CH(e, f, g),这是一个比较关键的压缩部分,相当于是将3个bit位压缩到了1个bit位:有以下情况:
x y z(压缩之前的3bit) g(压缩之后的1bit)
0 0 0 r000
0 0 1 r001
0 1 0 r010
0 1 1 r011
1 0 0 r100
1 0 1 r101
1 1 0 r110
1 1 1 r111
其中R有8位,每位都可能是0或者1,所以是2^8 = 256中情况,但是需要保持1和0的个数相同,都是4,这样结果比较均匀,这样的话是 8! / (4! * 4!) = 70种情况;但是,x,y,x地位是相同的,那么假如,xyz得到一种8位的结果,交换比如x,y得到另一个8位的结果,其实和不交换x,y得到的8位结果是等价的;另外,对于xyz中的每个bit,是0还是1的地位也是相同的,比如xyz和(非x)yz得到的结果也是等价的;最好,如果结果只和某两列或者一列相关也是效果不好的,必须由3列共同决定。这样,可以利用程序遍历,最终其实就得到4种压缩函数