很多机器学习的问题都会涉及到有着几千甚至数百万维的特征的训练实例。这不仅让训练过程变得非常缓慢,同时还很难找到一个很好的解,我们接下来就会遇到这种情况。这种问题通常被称为维数灾难(curse of dimentionality)。
幸运的是,在现实生活中我们经常可以极大的降低特征维度,将一个十分棘手的问题转变成一个可以较为容易解决的问题。例如,对于 MNIST 图片集(第 3 章中提到):图片四周边缘部分的像素几乎总是白的,因此你完全可以将这些像素从你的训练集中扔掉而不会丢失太多信息。图 7-6 向我们证实了这些像素的确对我们的分类任务是完全不重要的。同时,两个相邻的像素往往是高度相关的:如果你想要将他们合并成一个像素(比如取这两个像素点的平均值)你并不会丢失很多信息。
警告:降维肯定会丢失一些信息(这就好比将一个图片压缩成 JPEG 的格式会降低图像的质量),因此即使这种方法可以加快训练的速度,同时也会让你的系统表现的稍微差一点。降维会让你的工作流水线更复杂因而更难维护。所有你应该先尝试使用原始的数据来训练,如果训练速度太慢的话再考虑使用降维。在某些情况下,降低训练集数据的维度可能会筛选掉一些噪音和不必要的细节,这可能会让你的结果比降维之前更好(这种情况通常不会发生;它只会加快你训练的速度)。
降维除了可以加快训练速度外,在数据可视化方面(或者 DataViz)也十分有用。降低特征维度到 2(或者 3)维从而可以在图中画出一个高维度的训练集,让我们可以通过视觉直观的发现一些非常重要的信息,比如聚类。
在这一章里,我们将会讨论维数灾难问题并且了解在高维空间的数据。然后,我们将会展示两种主要的降维方法:投影(projection)和流形学习(Manifold Learning),同时我们还会介绍三种流行的降维技术:主成分分析(PCA),核主成分分析(Kernel PCA)和局部线性嵌入(LLE)。
维数灾难
我们已经习惯生活在一个三维的世界里,以至于当我们尝试想象更高维的空间时,我们的直觉不管用了。即使是一个基本的 4D 超正方体也很难在我们的脑中想象出来(见图 8-1),更不用说一个 200 维的椭球弯曲在一个 1000 维的空间里了。
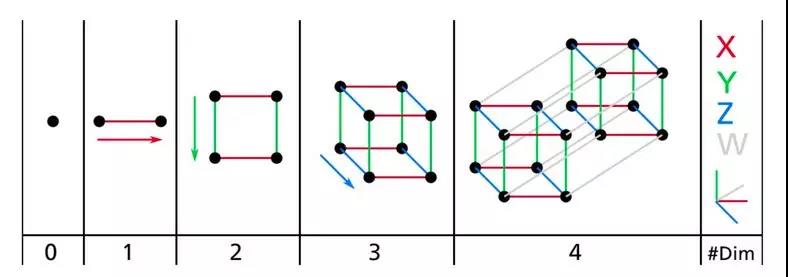
图 8-1 点,线,方形,立方体和超正方体(0D 到 4D 超正方体)
这表明很多物体在高维空间表现的十分不同。比如,如果你在一个正方形单元中随机取一个点(一个1×1的正方形),那么随机选的点离所有边界大于 0.001(靠近中间位置)的概率为 0.4%(1 - 0.998^2)(换句话说,一个随机产生的点不大可能严格落在某一个维度上。但是在一个 1,0000 维的单位超正方体(一个1×1×...×1的立方体,有 10,000 个 1),这种可能性超过了 99.999999%。在高维超正方体中,大多数点都分布在边界处。
还有一个更麻烦的区别:如果你在一个平方单位中随机选取两个点,那么这两个点之间的距离平均约为 0.52。如果您在单位 3D 立方体中选取两个随机点,平均距离将大致为 0.66。但是,在一个 1,000,000 维超立方体中随机抽取两点呢?那么,平均距离,信不信由你,大概为 408.25(大致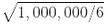 )!这非常违反直觉:当它们都位于同一单元超立方体内时,两点是怎么距离这么远的?这一事实意味着高维数据集有很大风险分布的非常稀疏:大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能远离任何训练实例,这使得预测的可靠性远低于我们处理较低维度数据的预测,因为它们将基于更大的推测(extrapolations)。简而言之,训练集的维度越高,过拟合的风险就越大。
)!这非常违反直觉:当它们都位于同一单元超立方体内时,两点是怎么距离这么远的?这一事实意味着高维数据集有很大风险分布的非常稀疏:大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能远离任何训练实例,这使得预测的可靠性远低于我们处理较低维度数据的预测,因为它们将基于更大的推测(extrapolations)。简而言之,训练集的维度越高,过拟合的风险就越大。
理论上来说,维数爆炸的一个解决方案是增加训练集的大小从而达到拥有足够密度的训练集。不幸的是,在实践中,达到给定密度所需的训练实例的数量随着维度的数量呈指数增长。如果只有 100 个特征(比 MNIST 问题要少得多)并且假设它们均匀分布在所有维度上,那么如果想要各个临近的训练实例之间的距离在 0.1 以内,您需要比宇宙中的原子还要多的训练实例。
降维的主要方法
在我们深入研究具体的降维算法之前,我们来看看降低维度的两种主要方法:投影和流形学习。
在大多数现实生活的问题中,训练实例并不是在所有维度上均匀分布的。许多特征几乎是常数,而其他特征则高度相关(如前面讨论的 MNIST)。结果,所有训练实例实际上位于(或接近)高维空间的低维子空间内。这听起来有些抽象,所以我们不妨来看一个例子。在图 8-2 中,您可以看到由圆圈表示的 3D 数据集。
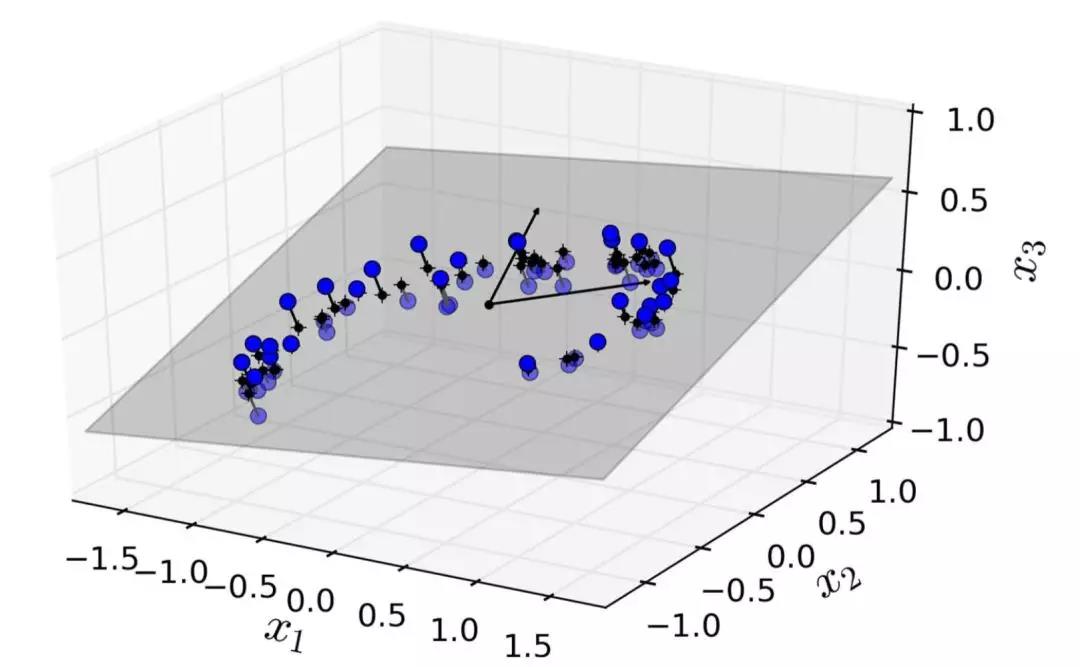
图 8-2 一个分布接近于2D子空间的3D数据集
注意到所有训练实例的分布都贴近一个平面:这是高维(3D)空间的较低维(2D)子空间。现在,如果我们将每个训练实例垂直投影到这个子空间上(就像将短线连接到平面的点所表示的那样),我们就可以得到如图8-3所示的新2D数据集。铛铛铛!我们刚刚将数据集的维度从 3D 降低到了 2D。请注意,坐标轴对应于新的特征z1和z2(平面上投影的坐标)。
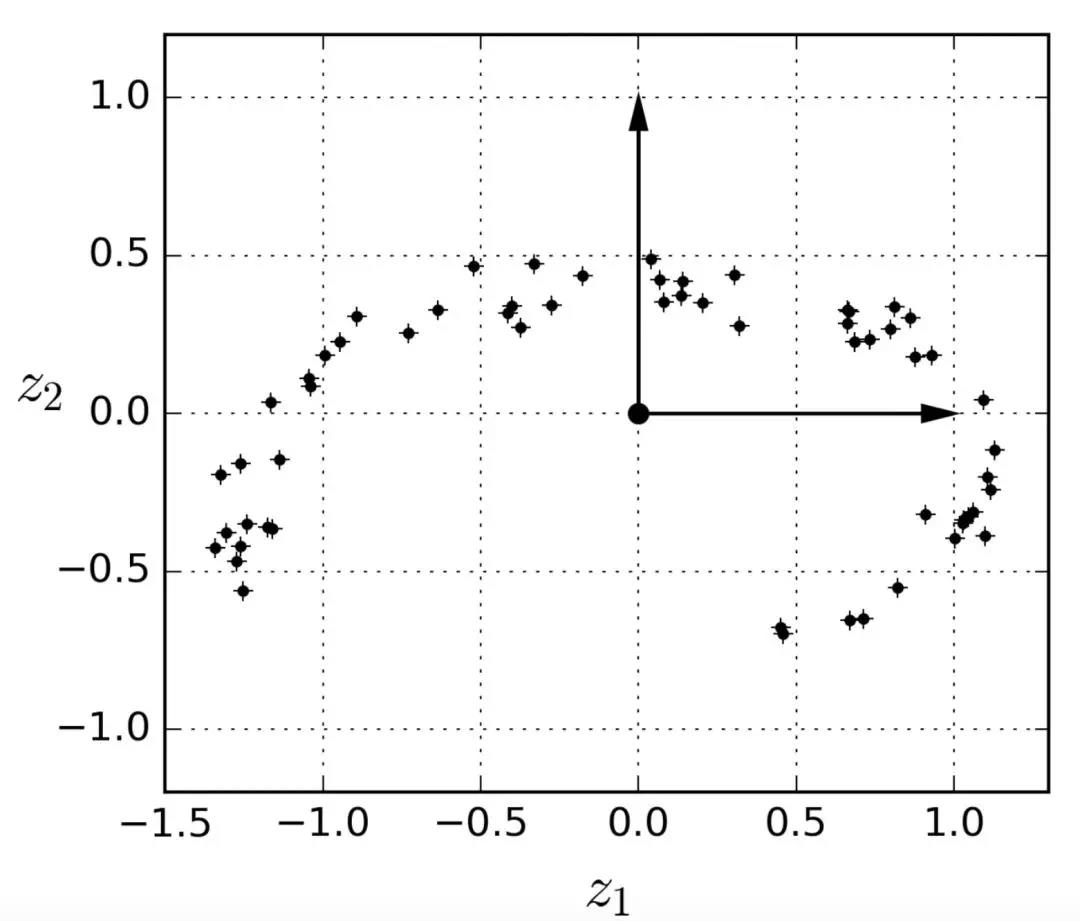
图 8-3 一个经过投影后的新的 2D 数据集
但是,投影并不总是降维的最佳方法。在很多情况下,子空间可能会扭曲和转动,比如图 8-4 所示的着名瑞士滚动玩具数据集。
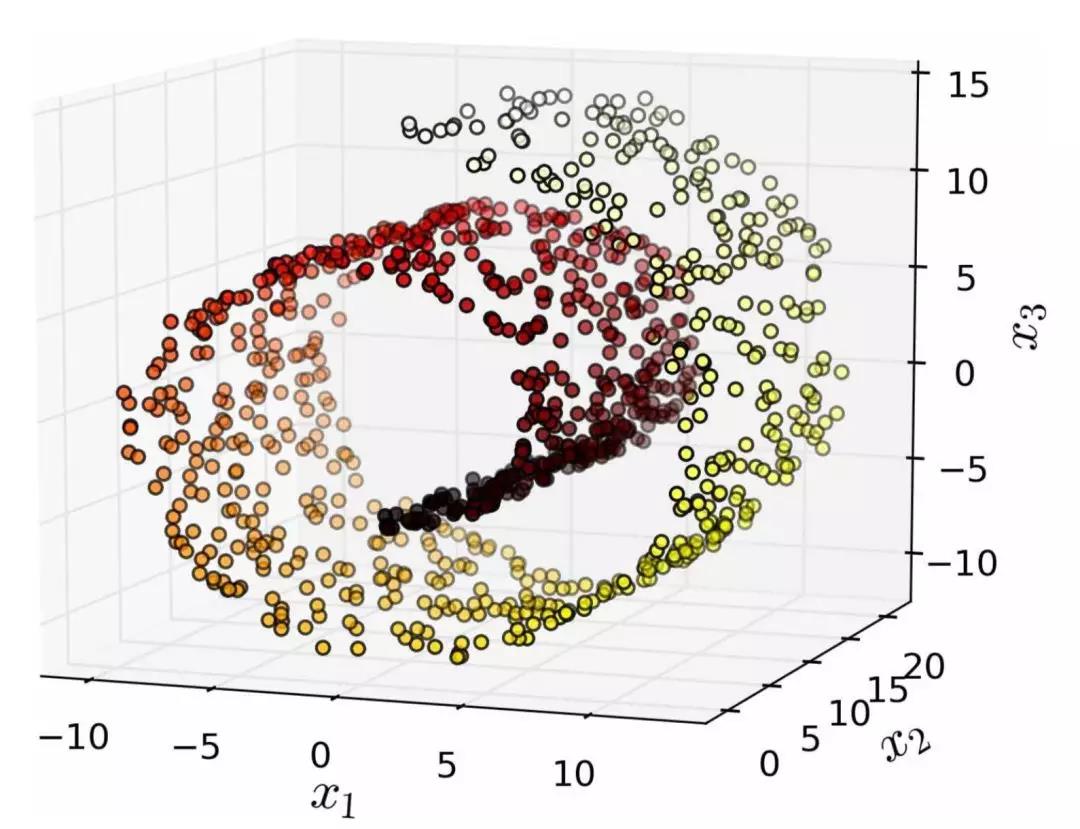
图 8-4 瑞士滚动数玩具数据集
简单地将数据集投射到一个平面上(例如,直接丢弃x3)会将瑞士卷的不同层叠在一起,如图 8-5 左侧所示。但是,你真正想要的是展开瑞士卷所获取到的类似图 8-5 右侧的 2D 数据集。
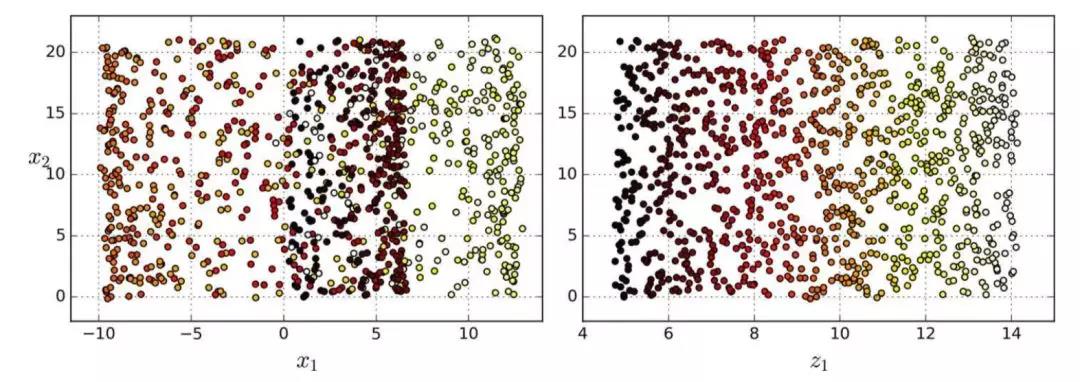
图 8-5 投射到平面的压缩(左)vs 展开瑞士卷(右)
流形学习
瑞士卷一个是二维流形的例子。简而言之,二维流形是一种二维形状,它可以在更高维空间中弯曲或扭曲。更一般地,一个d维流形是类似于d维超平面的n维空间(其中d < n)的一部分。在我们瑞士卷这个例子中,d = 2,n = 3:它有些像 2D 平面,但是它实际上是在第三维中卷曲。
许多降维算法通过对训练实例所在的流形进行建模从而达到降维目的;这叫做流形学习。它依赖于流形猜想(manifold assumption),也被称为流形假设(manifold hypothesis),它认为大多数现实世界的高维数据集大都靠近一个更低维的流形。这种假设经常在实践中被证实。
让我们再回到 MNIST 数据集:所有手写数字图像都有一些相似之处。它们由连线组成,边界是白色的,大多是在图片中中间的,等等。如果你随机生成图像,只有一小部分看起来像手写数字。换句话说,如果您尝试创建数字图像,那么您的自由度远低于您生成任何随便一个图像时的自由度。这些约束往往会将数据集压缩到较低维流形中。
流形假设通常包含着另一个隐含的假设:你现在的手上的工作(例如分类或回归)如果在流形的较低维空间中表示,那么它们会变得更简单。例如,在图 8-6 的第一行中,瑞士卷被分为两类:在三维空间中(图左上),分类边界会相当复杂,但在二维展开的流形空间中(图右上),分类边界是一条简单的直线。
但是,这个假设并不总是成立。例如,在图 8-6 的最下面一行,决策边界位于x1 = 5(图左下)。这个决策边界在原始三维空间(一个垂直平面)看起来非常简单,但在展开的流形中却变得更复杂了(四个**线段的集合)(图右下)。
简而言之,如果在训练模型之前降低训练集的维数,那训练速度肯定会加快,但并不总是会得出更好的训练效果;这一切都取决于数据集。
希望你现在对于维数爆炸以及降维算法如何解决这个问题有了一定的理解,特别是对流形假设提出的内容。本章的其余部分将介绍一些最流行的降维算法。
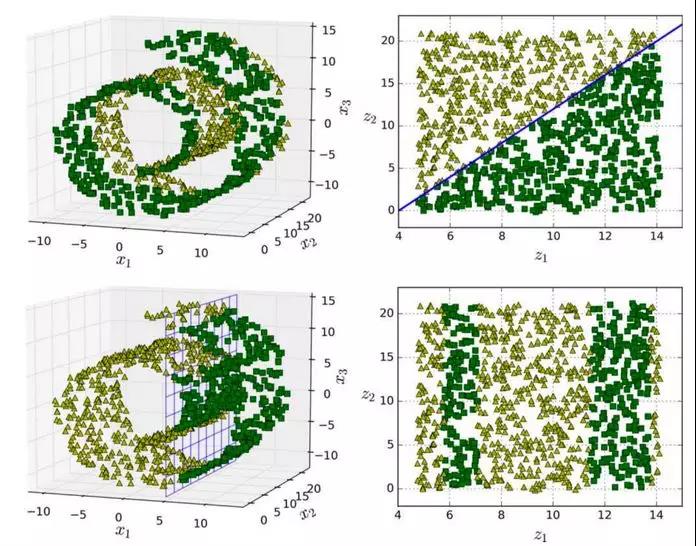
图 8-6 决策边界并不总是会在低维空间中变的简单




