RBG团队在2015年,与Fast R-CNN同年推出了Faster R-CNN,我们先从头回顾下Object Detection任务中各个网络的发展,首先R-CNN用分类+bounding box解决了目标检测问题,SPP-Net解决了卷积共享计算问题,Fast R-CNN解决了end-to-end训练的问题,那么最后还能下一个ss算法,依旧**于网络,是一个单独的部分,然而这个算法需要大概2秒的时间,这个点是R-CNN系列的性能瓶颈,所有Fast R-CNN是没有什么实时性的。那么Faster R-CNN的出现就是为了解决这个瓶颈问题。
在Faster R-CNN中提出了RPN网络,Region Proposal Network(区域建议网络)以代替原来的ss算法,可以简单的理解为:
Faster R-CNN =Fast R-CNN+RPN-ss算法
所以,可以说除了RPN,Faster R-CNN剩下的地方与Fast R-CNN是一样的, 那么理解Faster R-CNN的关键其实理解RPN。
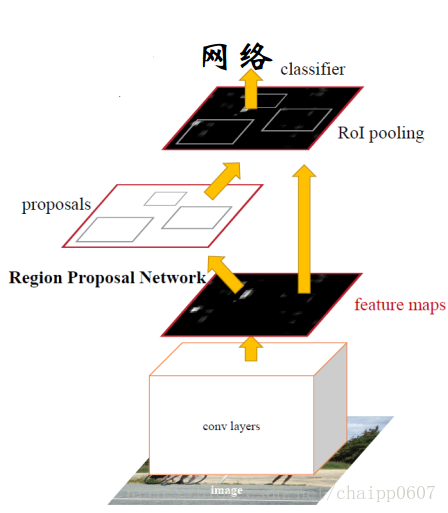
首先,上面这张图说明了RPN在Faster R-CNN中的位置,它在CNN卷积后的特征图上做区域建议(大约300个),并根据RPN生成的区域建议对feature maps做提取,并对提取后的特征做RoI pooling。在RoI pooling之后的东西就和Fast R-CNN一样了。
所以RPN的输入是卷积后的特征图,输出是多个打过分的建议框,所谓打分是对框中是否是物体打分,建议框是四个值(x,y,w,h)。
RPN是一种全卷积网络,它的前几层卷积层和Faster R-CNN的前五层是一样的,所以RPN是在进一步的共享卷积层的计算,以降低区域建议的时间消耗。
也是因为共享卷积的原因,所以我们一般认为RPN只有两层。而RPN前面到底有几层,决定于Faster R-CNN选择哪种初始模型,如果是AlexNet的话,那就是5层,如果是ZFNet的话,也是5层,如果是VGG16的话,就是13层,等等。
那么我们还是用AlexNet举例好了,此时的conv5特征图的尺寸为13*13*256,也就是这一层的特征别送入到RPN中,RPN在这个特征图上用3*3*256的卷积核,一共用了256个。那么卷积核一次卷积之后的特征就是1*1*256,也就是下图中的256-d,之后该特征出两个分支:
第一个分支(reg layer)用4k个1*1*256的卷积核卷积,最后输出4k个数,这里的4是一个建议框的参数,即(x,y,w,h);
第二个分支(cls layer)用2k个1*1*256的卷积核卷积,最后输出2k个数,这里的2是该区域到底有没有物体,即(object,non-object)。
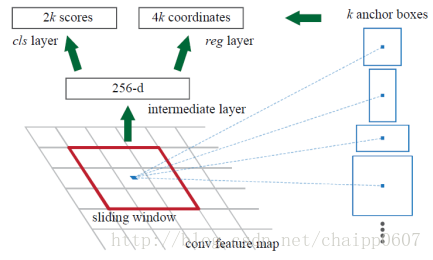
那么,k是什么呢?
k是Anchor box(参考框)的类型数,在Faster R-CNN中k=9,分别是3个尺度scale和3个比例ratio,其中:
scale为(128,256,512)
ratio为 1:1,1:2,2:1


参考框的中心就是卷积核的中心。
所以,在conv5层上,用3*3卷积核每卷积一次,都会生成k个参考框,那么参考框的总数就应该是W*H*K,如上所说,conv5的尺寸为13*13的话,那么生成的Anchor box的总数就是1521个。
然后我们就会发现通过上面的解释,RPN有一些地方是说不通的,下面我们一一解释下这些坑:
1.上面提到Anchor box的总数是1521个,那为什么说RPN生成300个左右的区域建议呢?
每一个参考框都会有一个是不是物体的打分,在检测过程中RPN计算所有的参考框后会选择其中300个得分最高的区域。
2.参考框中的尺寸为(128,256,512),但是conv5的尺寸只有13*13,在哪里生成这些参考框呢?
这些参考框不是在特征图上生成,而是在原图上,而原图之前的尺寸也不是224*244,这个尺寸是原图经过压缩得到的,所以anchor size的选择一定是要考虑缩放前的原图的尺寸,因为最后anchor超过的图像大小,并没有意义。所以RPN在做的是将每个点产生的9个参考框来映射原始图像,也就是通过4k个位置偏移输出和k个参考框,得到参考框在原始图像中的位置。就像Fast R-CNN中ss算法,其实也是在原图上生成的,最后只是经过了坐标变化才能在conv5上提取。
1.在卷积核卷积到一个点的时候,输出了9个参考框,但是这9个建议框的特征是相同的,都是256个3*3*256卷积核卷积得到的1*1*256的特征,那么这9个参考框在哪里引导的RPN关注这些区域呢?
特征确实是相同的,但是得到的特征最终是要向原图做映射的,以得到最终的区域建议,而相同的特征对应了9种不同的参考映射方式,于是相同的特征,映射给不同的参考框时,loss是不同的。那么哪种方式是做好的呢,当然是loss最小的那个。所以不同的9个参考框,它们的区别并不体现在特征上,而是在loss上,我们下面就看下RPN的损失函数。
首先给出函数的公式:
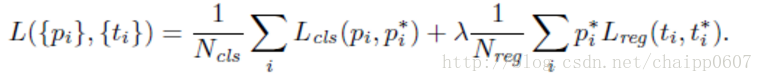
这个公式和Fast R-CNN的多任务损失其实很像,同样是一个在做分类,一个在做回归,然后把两个函数加在一起。i是一个batch中anchor box的索引。
用于分类的loss:
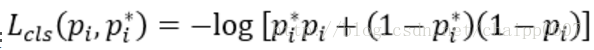
这依然是一个负的log值,,Pi为第i个参考框是物体的预测概率,Pi*是一个指示函数,如果anchor是物体的话,Pi* 就是1;如果anchor是背景,那么Pi* 就是0。
那么如果某一个区域是物体的话,如果pi=1,pi*=1,此时的损失函数为0;同理pi=0的话,损失函数为正无穷。
用于回归的loss:
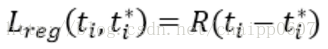
其中R还是smooth L1平滑方程:
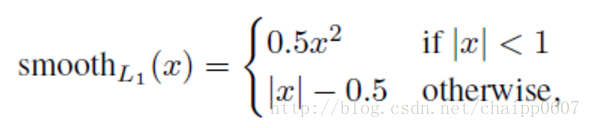
同样的背景没有边界框,所以需要Pi* Lreg。
而ti与ti*分布对应四个值,分别是x,y,w,h的坐标偏差,其中:
x,y,w,h是预测框(就是reg layer的输出);
xa,ya,wa,ha是anchor参考框;
x*,y*,w*,h*是ground truth框;
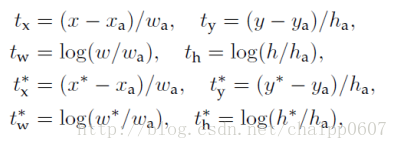
ti是预测框与anchor之间的偏差,ti*是ground truth与anchor之间的偏差,那么我们考虑一种情况,那就是ti与ti*与相同了,此时损失函数就是0,那么这意味着:
预测值与anchor之间的偏差=ground truth与anchor之间的偏差
也就是说预测值完全等于ground truth。这就是上面提到的注意机制引导RPN关注anchor的过程,当anchor不同的时候,loss函数是不同的。所以这是一个反向的过程,我们选择出来了某一个点上3*3范围内的特征,那么这个特征是物体还是背景呢,还有就是它对应原图中哪个区域的时候,效果是最好的呢?这就是RPN要解决的问题。
在这里顺便说一下个人的一个想法,会更方便理解,RPN在conv5上用3*3的卷积核卷积,那么如果原图上某一个区域在conv5上的大小恰好就是3*3呢?那么这个卷积就相当于一个全尺寸卷积了,显然它是可以学习到这个区域内的所有特征的,然后我们再看下这些尺寸,这方便我们理解为什么RPN选择了3*3卷积。
conv5的尺寸为13*13;
卷积为3*3;
原图大小如果是1024;
那么anchor选择为256的时候,它们的比例非常接近:
13/3 = 1024/256
但是原图的尺寸不一定都是1024*1024,所以为了考虑形变与缩放,anchor有9个选择。
Faster R-CNN的训练时分步的,但是不是分阶段的,因为end-to-end的问题在fast R-CNN就已经解决了。前面说了Faster R-CNN =Fast R-CNN +RPN,所以训练的过程需要分步来完成,但是每一步都是end-to-end。
Step 1:训练RPN网络;用的是ImageNet上的初始模型,因为RPN是由自己的损失函数的,所以在这里可以先把RPN训练起来,但是在组合mini-batch做梯度回传的时候为了避免负样本(背景)偏多的情况,会人为的我们随机地在一个图像中选择256个anchor,其中采样的正负anchor的比例是1:1。如果一个图像中的正样本数小于128,我们就用负样本填补这个mini-batch。
Step 2:训练Fast R-CNN;训练好RPN之后,单独训练Fast R-CNN,此时Fast R-CNN是不与RPN共享卷积层的,也就是初始模型还是ImageNet上得到的,用的区域建议是RPN生成的,训练的过程在之前的文章就就介绍了。
Step 3:调优RPN,在这一步中将再次训练RPN,这不过这次的前五层卷积核与Fast R-CNN共享,用Step2中的结果初始化RPN,并固定卷积层,finetune剩下的层。
Step 4:调优Fast R-CNN,此时用的区域建议是Step3中调优后的RPN生成的,同样是固定了卷积层,finetune剩下的层。

上面这张图说明了Faster R-CNN的单图测试时间与mAP,可以看到,Fast R-CNN与R-CNN的时间与Object Detection系列(三) Fast R-CNN的说法不一样了,这是因为后者加上了ss算法的时间,大概2s左右的样子。
单图测试时间的大幅缩减,让Fast R-CNN能够真正意义上实现实时检测任务。但是吧,Faster R-CNN的性能评价是在8个K40 GPU上做出来的。