最近一段时间,“蒸馏”这个词被越来越频繁地使用。在 AI 领域,它通常意味着把复杂能力提炼成更紧凑、可复用的结构;而放到策略研究里,这个思路同样成立。说得更直接一点,就是把原本分散、模糊、依赖主观经验的知识,整理成可以计算、可以验证、也可以继续修正的系统。
crypto-kol-quant 这个项目最近很火,其中真正有意思的地方,不是它抓取了多少 KOL,也不是它用了 LLM,而是它试图做一件量化研究里并不常见的事:把交易员的经验蒸馏成一组可计算的能力因子,再进一步聚合成共识信号。这个问题本身很值得认真对待。因为如果一批长期活跃、风格稳定的交易员,确实在市场中形成了各自的认知框架,那么这些框架理论上就不该只存在于推文、图表和只言片语里,它们也应该有机会被提取、整理,并进入可运行的策略链路。
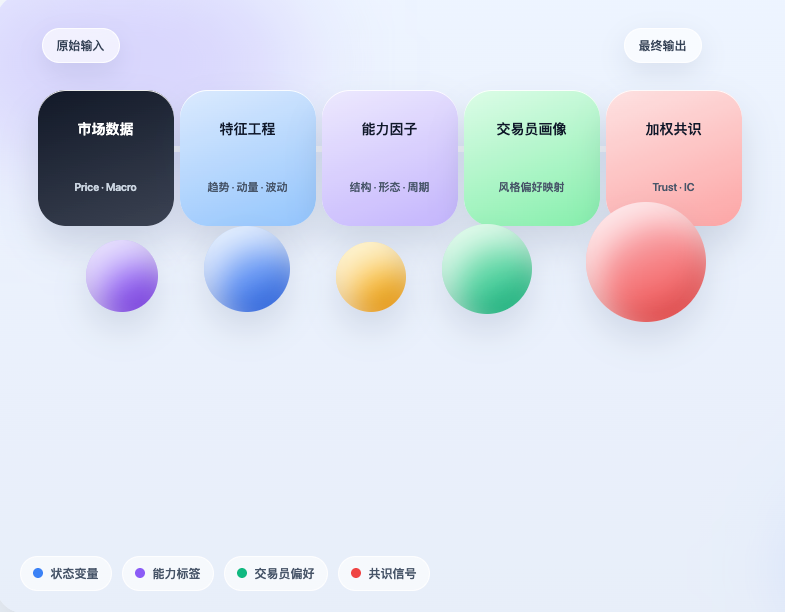
基于这个思路,我们在发明者量化环境里做了一个初步实现。重点不是把项目简单“搬过来”,而是把它最核心的逻辑真正串起来:先获取市场数据,再把市场翻译成结构化状态;然后根据这些状态去判断哪些交易能力正在被触发;接着把这些能力映射回交易员画像,最后再把不同交易员的个人判断聚合成一个带权重的共识信号。它显然还不是一个成熟的交易系统,但它至少完成了一件重要的事:证明交易员经验确实可以被压缩、结构化,并真正进入策略判断流程。
蒸馏的对象,不是观点,而是交易能力
很多人第一次接触这类项目时,容易把它理解成“KOL 情绪策略”。但这其实并不准确。原始项目真正做的,不是简单判断谁今天更乐观,也不是统计谁喊了多、谁喊了空,而是更进一步去追问:这位交易员到底如何理解市场?他在什么结构下会偏多?他更关注趋势、位置、形态、波动,还是宏观环境?这些判断方式,能不能整理成一组稳定的能力标签?
一旦问题被这样提出,策略的重心就变了。系统不再关心某一句话本身,而是关心那句话背后的方法论。换句话说,这套策略真正蒸馏的对象,不是文本,而是交易知识本身。它试图把原本依赖人去理解的主观经验,翻译成程序可以识别和调用的规则化能力。这也是它和常见情绪模型最大的不同:它不是去判断市场情绪有多热,而是去重建不同交易框架在当前市场中的反应方式。
第一步:先把市场翻译成状态变量
蒸馏要想真正落地,第一步一定不是预测,而是特征工程。原因很简单,交易员的语言是给人看的,不是给程序看的。比如“价格回踩关键均线,是不错的二次上车点”这句话,对交易员来说很好理解,但对程序来说,它必须先被拆开:关键均线是什么,是 50 日还是 200 日;当前价格是不是接近这条均线;趋势有没有被破坏;有没有出现承接信号。
所以系统首先要做的,不是给出多空结论,而是把原始行情转换成一组结构化状态。这里最基础的一层,是用价格去构建趋势和动量特征。均线、指数均线、RSI、MACD 之类的变量,不是为了堆指标,而是为了回答一个简单的问题:市场现在大致处在什么状态。

关键代码如下:
# 用不同周期的均线描述价格所处的趋势位置
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# 指数均线对近期价格变化更敏感
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI 用来描述市场是否进入超买超卖,或者动量是否衰减
f['rsi14'] = _rsi(c,14)
# MACD 及其信号线、柱体,用来观察趋势和动量变化
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
这段代码做的事情并不复杂。均线帮助系统判断当前价格相对长期趋势的位置,RSI 和 MACD 则用来描述动量是在增强还是衰减。它还没有进入交易判断,只是在建立一层“市场状态描述”。
接着,系统还要补上波动率和位置关系,因为很多交易判断并不只依赖趋势,还依赖“现在是不是波动收缩期”“价格是不是接近区间高点或低点”。
对应的代码是:
# 对数收益率是计算波动率的基础
logr = np.log(c / c.shift(1))
# 近 30 天年化波动率,用来衡量当前市场波动水平
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# 最近 20 天和 50 天的高低点,用来判断价格所处位置
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
这里的 rv30 表示近 30 天的年化波动水平,而区间高低点则用来帮助系统判断,当前价格在最近的价格结构中到底处于什么位置。除此之外,宏观背景也被一起纳入状态空间。因为有一类交易员并不是只看币价本身,他们会同时观察美元指数、美股风险偏好和利率环境。代码里对应的处理方式,是先把这些变量按日对齐,再转换成可读取的状态:
# DXY 作为美元强弱的背景变量
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX 作为风险偏好背景变量
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
这一步的意义可以概括为一句话:先把“市场现在怎么样”,翻译成机器可以持续读取的结构化状态。如果没有这一层,后面的蒸馏就无从谈起。
第二步:把主观经验写成能力因子
仅有特征还不够,因为特征只是在描述市场,并不直接表达“这种状态意味着什么”。下一步必须把交易员的经验写成规则,也就是根据当前这些状态变量,去判断哪些交易能力正在被触发。
这一步是整套策略蒸馏味道最强的部分。因为这里不再是抽象地说“某种框架很重要”,而是把它真正写成程序条件。当前实现里包含的能力因子,覆盖了形态、结构、指标、周期和宏观几个层面。比如有些能力来自形态识别,像牛旗、熊旗、双顶双底、头肩结构、三角形;有些来自结构分析,像 Wyckoff、SMC、ICT 等框架;有些来自指标本身,比如 RSI 背离、均线金叉死叉、布林压缩突破;还有一些来自周期和宏观环境,比如减半周期、趋势市和震荡市切换、DXY 回落、风险偏好回升等。
一个很典型的例子,是“趋势回踩延续”。很多交易员都会有类似经验:如果大趋势仍然向上,价格回踩关键均线,而且当前 K 线出现了承接,那么这往往意味着趋势延续。程序对它的表达非常直接:
# 判断当前价格是否接近 50 日均线
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# 如果 50 日均线仍在 200 日均线上方,且回踩均线后出现阳线承接
# 则记为一个趋势延续能力信号
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
这里并没有神秘的地方,它只是把一句人类语言拆成了几个机器可以逐一判断的条件。另一个例子是“布林压缩突破”。对于许多交易员来说,波动长期收缩后再突然向上或向下扩张,往往意味着新的方向选择。对应的规则写法是:
# 如果前一根 K 线布林带宽度低于压缩阈值,则视为波动收缩
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# 收缩之后向上突破上轨,给正向信号;向下跌破下轨,给负向信号
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
宏观因子的处理也是一样。对于一类更偏宏观的交易员来说,BTC 并不是完全孤立的价格序列,它会受到美元、股市和利率环境影响,所以这些理解也被写成能力判断:
# DXY 回落通常被视为对 BTC 偏正面的背景
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# 标普上涨可视为风险偏好改善
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# 短端利率回落可视为流动性边际改善
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
这一层真正重要的,不是它写了多少规则,而是它完成了蒸馏最关键的一步:把原本只能靠主观理解的判断,压缩成了可计算条件。需要顺便指出的是,当前版本的大多数能力因子仍然是条件触发型,而不是连续评分型。这意味着系统更像是在判断某种结构是否成立,而不是对每个细微波动都持续重新定价。这也决定了它目前更适合日线或中低频判断,而不是高频交易。
第三步:因子不直接加总,而是先映射回交易员画像
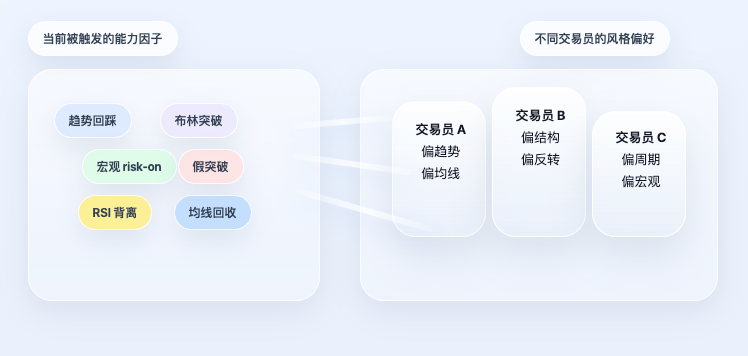
如果策略只做到因子层,那它仍然只是一个普通规则系统。原始项目更特别的地方在于,它没有在这里停下来,而是继续往前推进了一步:因子并不直接决定方向,而是先映射回交易员画像。
这一点非常关键。因为现实中的交易员,并不是“平均使用所有能力”的。有人偏趋势,有人偏结构,有人偏周期,有人偏宏观。即便面对同样的市场状态,不同人关注的重点也完全不一样。所以系统不会简单地把所有因子一股脑平均,而是先读取每位交易员的能力偏好,再根据当前因子状态为他计算个人信号。
对应的画像读取逻辑如下:
# 读取每位交易员在画像中使用的能力因子及其权重
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
每份画像本质上都在回答一个问题:这个交易员更依赖哪些能力因子,以及这些能力在他的框架里权重有多大。有了这份画像后,系统才会去计算每位交易员在当前市场里的“个人信号”:
for p in profiles:
sig = 0.0
wt = 0.0
# 遍历该交易员关注的所有能力因子
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# 当前因子得分乘以交易员对该因子的偏好权重
sig += w * score
wt += abs(w)
# 归一化后得到该交易员在当前市场下的个人信号
trader_raw = sig / wt if wt > 0 else 0.0
看到这里,这套系统的味道其实已经很不一样了。它不再只是看“哪些因子亮了”,而是在近似重建一件事:如果把今天的市场交给这 99 位交易员,他们分别会怎么判断。
第四步:从个人信号到加权共识
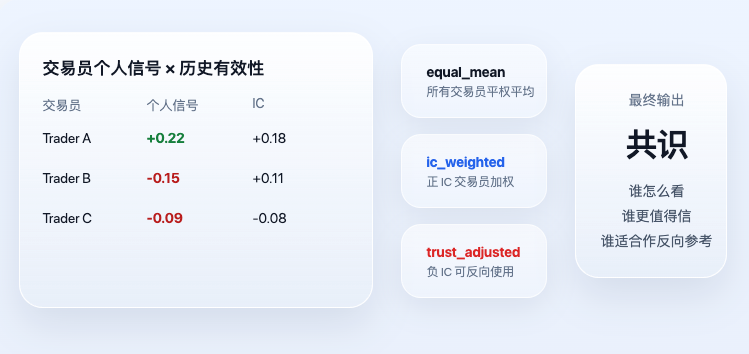
当每位交易员的个人信号都算出来以后,系统才进入真正的共识层。这里的“共识”不是简单投票,更不是谁声音大谁说了算,而是进一步考虑历史有效性。
当前代码里最重要的两个结果是 ic_weighted 和 trust_adjusted。对应的核心逻辑是:
# 先对正 IC 的交易员做正向加权,得到 ic_weighted
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted 更进一步:
# 正 IC 顺向使用,负 IC 反向使用,再按绝对 IC 大小加权
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
这段代码表达了两个很朴素但非常重要的原则。第一,历史上更有效的交易员,在今天拥有更大的权重。第二,历史表现为负 IC 的交易员,也不是被丢弃,而是可能被当作反向指标使用。因此,最终输出的 trust_adjusted 不是简单的“大家怎么看”,而是“谁怎么看,以及谁更值得信”。
这也是为什么这套系统和普通的情绪模型不同。它不是在统计声音的多少,而是在做一轮带历史检验的认知聚合。如果把整套方法压缩成一句话,它其实就是:先把市场转成状态变量,再把状态变量映射成能力因子,再把能力因子映射成交易员个人信号,最后把这些个人信号按历史有效性聚合成共识判断。
在发明者上的实现,真正跑通了什么
如果只停留在研究项目里,这套系统更像一个“共识分析器”;而在发明者上的实现,重点是把整条链路真正串起来,让它可以持续运行。最核心的代码其实只有三行:
# 第一步:把原始行情和宏观变量转成结构化状态
feat_df = build_features(records, macro if macro else None)
# 第二步:根据状态变量评估当前哪些能力因子被触发
factor_scores = evaluate_factors(feat_df)
# 第三步:把能力因子映射回交易员画像,并聚合成共识结果
consensus = compute_consensus(factor_scores)
这三行几乎就是整套策略最重要的三层抽象。第一层负责市场状态,第二层负责能力判断,第三层负责交易员共识。它们后面当然还接着执行层、风控层和状态展示,但从研究逻辑上讲,最关键的部分已经完整成立了。也就是说,这份实现最重要的意义,不在于它多了多少运行细节,而在于原始项目里的能力画像不再只是静态文件,因子不再只是研究输出,共识不再只是报告里的数字,它们已经被串进了一个持续运行的判断流程里。
它为什么仍然只是一个原型
当然,这套实现并不是终局。当前代码使用的是 BTC 日线框架,所以它更适合做中低频的共识判断,而不是高频交易系统。它的核心仍然围绕日线结构、周期位置、宏观背景和交易员能力偏好展开。此外,交易员画像和 IC 目前仍然是静态输入,还没有进入在线进化阶段。也就是说,系统虽然完成了“知识蒸馏”的第一步,但还没有完全做到“蒸馏后的知识继续自我修正”。
但这并不妨碍它已经说明了一件非常重要的事情:交易员经验是可以被层层压缩、结构化,并真正进入策略链路的。它的价值不在于已经形成稳定收益,而在于把一条原本停留在概念层的研究路径,推进到了可运行阶段。至于这些能力因子该如何演化,交易员权重该如何更新,共识该如何在真实市场里持续校正,仍然需要更多运行数据去回答。
结语
crypto-kol-quant 真正有启发性的地方,不在于它用了多少流行概念,而在于它把一件很难被系统化的事情,真正往前推进了一步:把交易员的经验,从表达变成能力,从能力变成因子,再从因子变成共识。而在发明者上的这份实现,做的正是把这条蒸馏链路真正跑通。它没有夸大自己已经是终局,也没有试图掩盖它仍然只是一个早期原型的事实。但它至少证明了,交易经验不一定只能停留在图表和语言里,它可以被蒸馏、被结构化、被运行,甚至可以被放进一个持续判断市场的系统之中。
如果说传统量化擅长从价格序列里找规律,那么这类策略真正值得继续推进的方向,也许是:从人的认知里提取规律,再让这些规律反过来参与市场。而这,可能正是“蒸馏”在策略研究里最值得关注的地方。




