预测商品指数运行态势, 对于指数管理部门而言, 可以在一定层面上监测和引导商品指数的平稳运行, 降低市场风险, 从而促进商品指数的可投资性和标尺性,同时,为优化商品指数编制方案提供参考途径。未来对于指数投资者而言,通过机器学习的算法对商品指数进行准确预测, 可以为其投资策略提供很好的参考价值,在一定程度上减少盲目投资的现象,减少投资者的损失。支持向量机(SVM)是一种基于统计学习理论和结构风险最小化原理的机器学习理论,本文针对飞创煤焦矿商品指数的非线性变化特点,采用小波去噪后的数据,并利用3种参数优化算法建立基于支持向量机回归理论的商品指数预测模型,并对指数开盘价预测,这对于管理、监测商品指数的平稳运行有着很好的应用价值。
1、模型的建立
基于支持向量回归机原理对飞创煤焦矿指数建立如下模型:
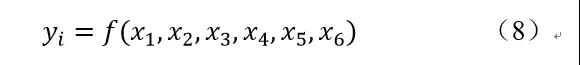
其中,x_1,x_2,x_3,x_4,x_5,x_6分别代表前一天的开盘价、最高价、最低价、收盘价、交易量、交易额,y_i代表开盘价,即本模型代表的含义为用前一天的6个指标,预测今天的开盘价。y_i即为目标函数,根据已知数据建立训练集和测试集,解的最优解带回到回归决策函数方程,得到回归决策函数,最后计算预测结果。
2、小波去噪与原始数据对比分析
利用小波变换的消噪原理去除时间序列中的细微波动,只考虑大体趋势,从而对时间序列进行平滑处理;本文采用5层db3小波进行分解去噪,去噪后指数开盘与原数据的对比走势图如下4所示:
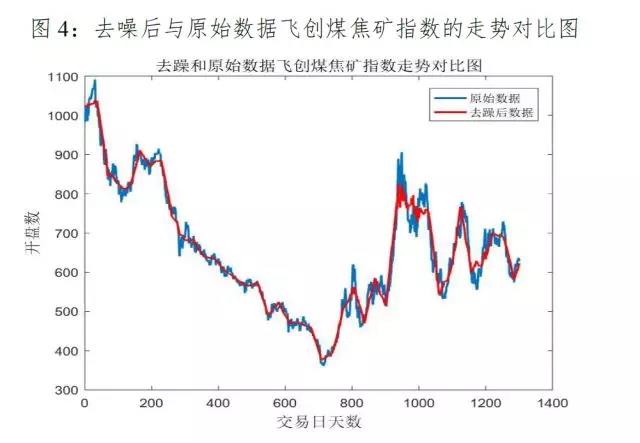
本文对原始数据采用5层 db3 小波进行分解去噪,经小波去噪后的数据明显比原始数据平滑,很好的消除了噪声,有利于后期的回归预测。
3、参数优化结果对比分析
(1)网格搜索法优化结果
利用网格搜索法进行参数寻优,首先在大范围粗略的寻找最佳参数c和g,让c和g的取值变化都为…,参数粗略选择的结果如下图5和图6所示:
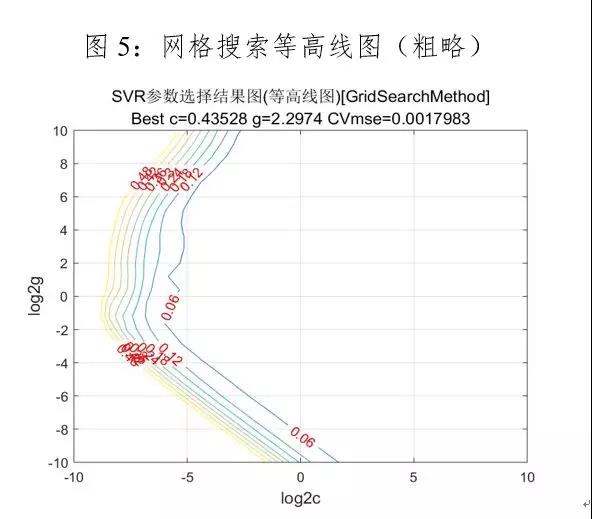
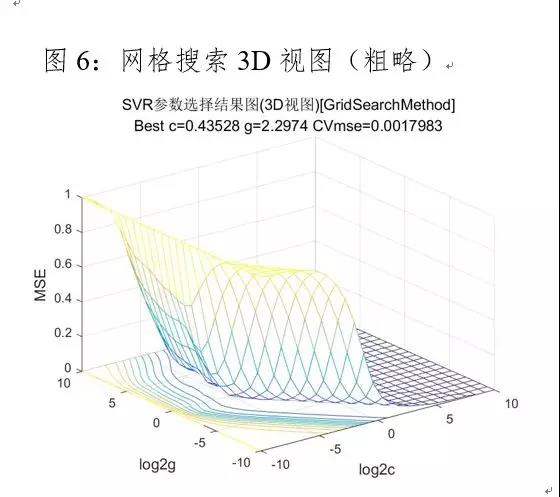
由图5看以看出c和g集中所在的区域,因而在参数粗略选择的基础上进行精细选择,让c的取值变化范围为2^(-8)…2^(-5),g的取值变化范围为2^(-6)…2^8,图6为网格搜索参数寻优的3D视图。缩小c和g的取值范围,进行参数精细选择,参数精细选择结果如下所示:
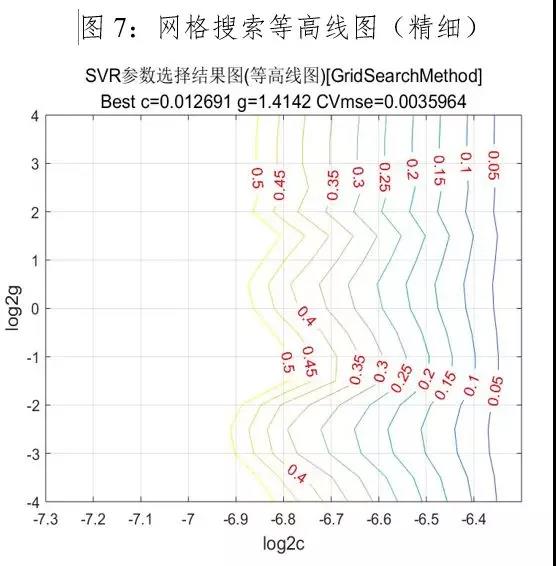
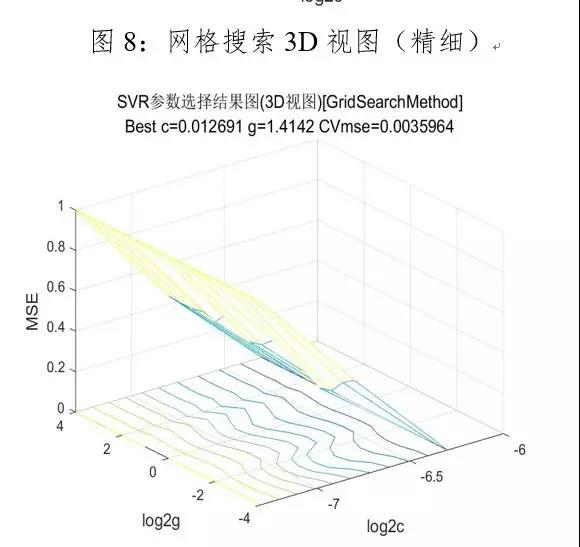
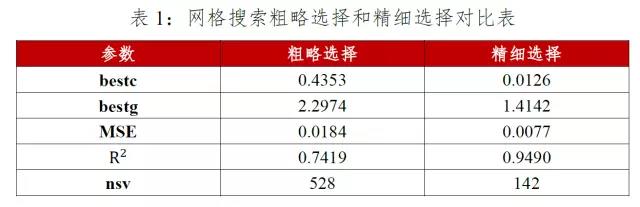
根据表1粗略选择和精细选择的对比可知,最优参数c和g分别为0.0126、1.4142,此时模型的拟合优度达到94.9%,均方误差为0.0077,并且支持向量的个数明显减少。
(2)遗传算法的优化结果
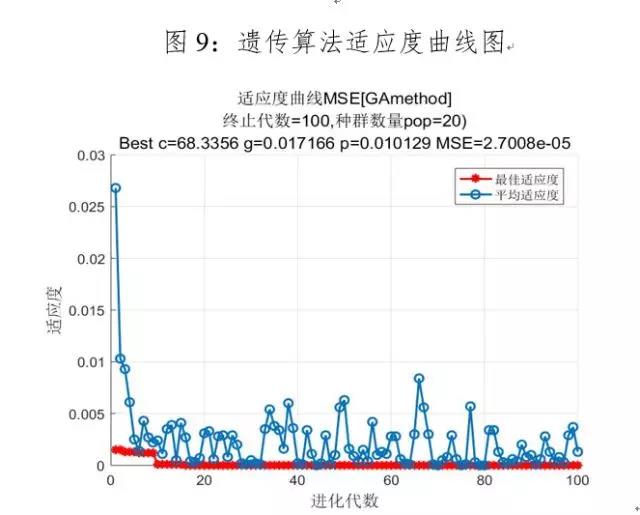
利用遗传算法寻找回归模型的最佳参数,最终的适应度曲线如图9所示,设置最大迭代次数为100代,适应度曲线描述的是均方误差MSE的变化曲线,随着迭代次数的增加,最佳适应度逐渐趋于稳定, 平均适应度上下随机波动,当MSE达到最低值,此时参数达到最优解。最优参数为:
bestc=68.3356,bestg=0.0172,MSE=2.7008e-05,R^2=0.9989。
(3)粒子群优化算法结果
利用粒子群优化算法寻找回归的最佳参数,最终的适应度曲线如下图10所示,设置最大进化代数为200,随着迭代次数的增加,最佳适应度逐渐趋于稳定,平均适应度上下随机波动,当mse达到最低值,此时参数c和g是最优值,bestc=0.1,bestg=2.659,mse=0.0026,=0.9847。
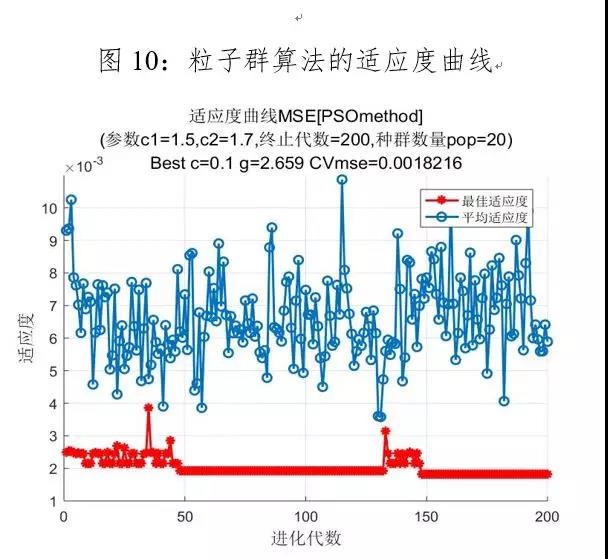
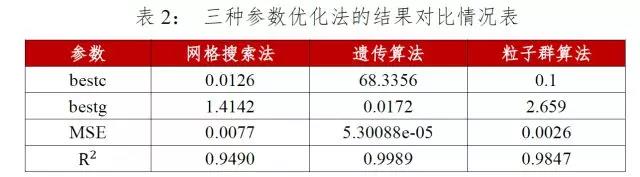
综上所述,三种优化算法的结果对比如表2所示,遗传算法参数优化的结果最好,模型的拟合优度最高,达99.95%,所以c和g的最优参数分别为62.0424、0.1783。
利用遗传算法参数优化得到的最佳的参数进行SVM网络训练,然后利用训练得到的模型进行预测,测试集为数据源的后301条数据,分别选取小波去噪后的数据和原始数据作为测试集,对指数开盘价进行预测,并对比分析小波去噪和原始数据对模型和预测误差的影响。
(1)原始数据的指数预测
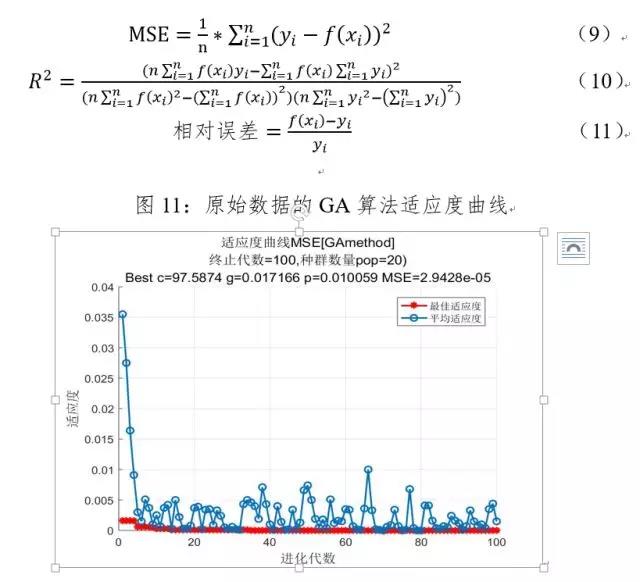
利用原始数据的后301个交易日的数据作为测试集,运用最优算法—遗传算法训练后的模型进行预测,结果如下图11-13、表3所示,评价指标的计算公式如下所示,其中为真实值,为预测值,MSE为均方误差,为可决系数。
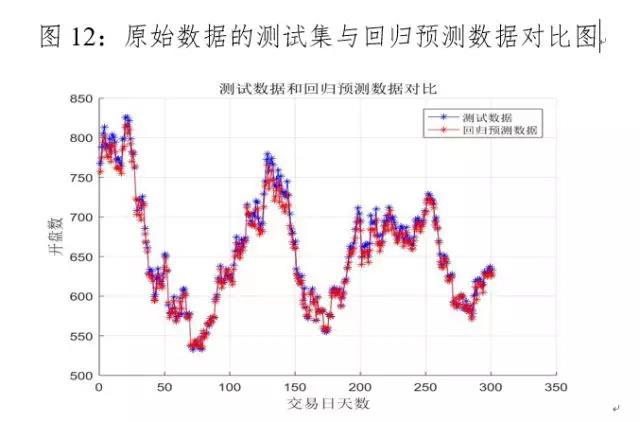
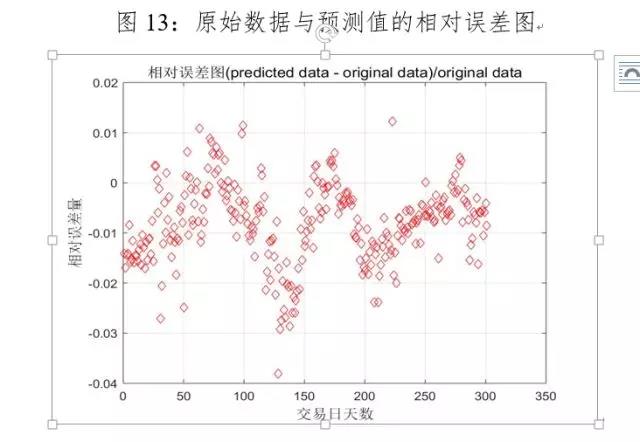
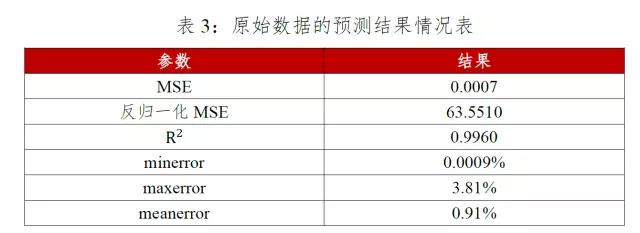
原始数据作为测试集进行回归预测的结果发现:均方误差为63.55,相对误差的范围为[0.0009%,3.81%],平均相对误差为0.91%,预测相对误差在0附近波动,达到了很好的预测效果;原始数据与回归数据拟合的较好,但在指数上涨的拐点处预测值明显低于实际值,这可能与回归模型缺乏市场情绪指标、现货指标等原因造成的;模型的拟合优度高达99.6%,证明支持向量回归模型适合预测飞创煤焦矿指数的开盘价。
(2)小波去噪后的指数预测
利用对原始数据小波分解去噪后的301个交易日的数据作为测试集,并运用最优算法-遗传算法训练后的模型进行预测,结果如下图14-16、表4所示:
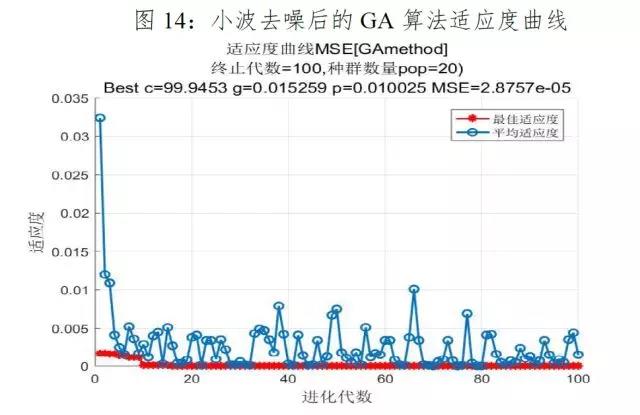
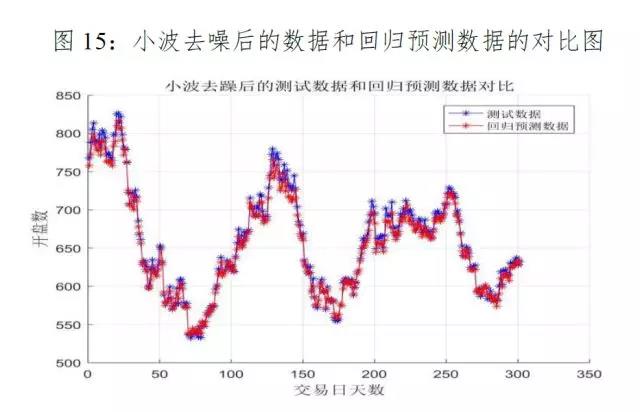
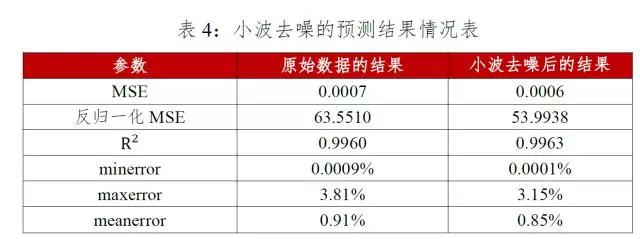
原始数据经小波分解去噪后的数据作为测试集进行回归预测的结果是:均方误差为53.99,相对误差的范围为[0.0001%,3.15%],平均相对误差为0.85%,预测相对误差较低,达到了很好的预测效果;实际值与回归预测值拟合的较好,但在指数上涨的拐点处预测值也明显低于实际值;模型的拟合优度高达99.6%,证明支持向量回归模型适合预测飞创煤焦矿指数,而且小波去噪后的均方误差和相对误差均低于原始数据做测试集的回归结果,证明经小波去噪后的支持向量机模型预测效果更好。
采用支持向量机原理建立了基于支持向量机非线性回归的预测模型,本文测试集选取了301个交易日的数据进行预测,利用最优算法-遗传算法进行参数寻优,实证结果表明经小波去噪、基于遗传算法参数优化的支持向量机回归模型预测效果最好。该方法下预测值与实际值之间的相对误差范围为[0.0001%,3.15%],平均相对误差为0.85%;模型的拟合优度达99.6%,误差较小,预测数据与原始数据拟合得比较好,结果表明,基于支持向量机的飞创商品指数预测是有效的,预测结果值得参考。
(一)增加数据量或频率
由于支持向量机方法是通过对历史样本的不断学习来建立预测模型的,SVM 预测模型的建立就是对历史样本的自学习记忆过程。因此,用尽可能多的样本参与学习训练,使预报模型包含比较完备的支持信息,可以提高预测精度。由于飞创煤焦矿指数基期是2012年12月31日,数据量相对较少,未来随着数据的增多或者采用每分钟数据预测精度会进一步提高。
(二)增加影响因子的数量
支持向量回归机因变量的选择是模型预测好坏的关键,本文只选取期货市场中的开盘价、收盘价、最高价、最低价、成交额、成交量6个指标;由于数据频率不同、定量数据等原因,未考虑现货数据、宏观经济指标、市场情绪指标等,存在不足,影响预测效果。如果未来再增加现货指标、市场情绪指标等因子,全面的包络影响指数值的因素,可能对预测结果会有较大改善。
(三)运用其他优化算法
模型预测精度的提高,需要不断优化数据、参数等,才能提高模型的预测精度。因而未来我们的研究方向将是利用优化算法提高模型预测精度,如利用主成分分析法对数据进行降维,去掉一些重复信息以便提高模型的运行速度和准确性;再如基于模糊集理论利用信息粒化算法对指数进行变化趋势和变化空间的预测。对模型进行进一步优化,从而进一步提高其预测精度,是未来研究工作的重要内容。
(四)采用动态的训练样本数据
一般支持向量机回归的研究方法是采用固定不变的训练样本形成固定的支持向量机来对未来一段时间的信息进行预测,这种方法并不能充分运用最新的样本信息进行预测,从而可能导致预测结果出现失真。鉴于指数走势一般是与最近样本信息联系较为紧密的,可以采用动态“滑窗”方式选定训练样本集,即预测第t+1天指数值时,动态选取前n天数据进行预测,即选择t-n,t-n+1,…,t-1 天的数据对应于每个指标数据的第二天的指数值,构造训练集。根据以上训练形成的向量机模型,取t天指数的指标数据可以预测第t+1天的数据。当预测t+2天时,“滑窗”则往前平移一天。这种方法构造的支持向量机,能够尽量确保当前预测值跟最近的n天指数信息相关,从而提高预测精度。




