请注意, 本文并非投资建议。本文数据是基于之前观察到的收益来模拟得来,和历史上的数据并非完全一致。本文提到的技术对了解如何更好地配置投资组合有帮助,但其不应该用作唯一的投资决策。
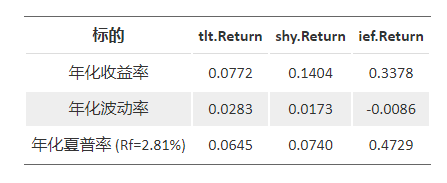
观察三种政府 ETF 债券 (TLT、IEF、SHY) 调整后的股息收益率,可以看到中期债券 (IEF) 风险收益情况比长期债券 (TLT) 更好。下面是以表格形式显示的结果。在本文中,将对结果进行重新分析和可视化展示:
首先,用如下函数来获取 ETF 的收益序列:
pacman::p_load(fImport, PerformanceAnalytics, stringb, tidyverse)
# 将股票数据加载到一个时间序列对象的函数
importSeries = function(symbol,from,to) {
# 从雅虎读取金融数据
input = yahooSeries(symbol,from = from, to = to)
# 列名调整
adjClose = symbol %.% ".Adj.Close"
inputReturn = symbol %.% ".Return"
CReturn = symbol %.% ".CReturn"
# 计算收益率并生成时间序列
input.Return = returns(input[,adjClose])
colnames(input.Return)[1] = inputReturn
input = merge(input,input.Return)
# 计算累积收益率并生成时间序列
input.first = input[,adjClose][1]
input.CReturn = fapply(input[,adjClose],
FUN = function(x) log(x) - log(input.first))
colnames(input.CReturn)[1] = CReturn
input = merge(input,input.CReturn)
# 删掉一些无用数据来释放内存
rm(input.first,
input.Return,
input.CReturn,
adjClose,
inputReturn,
CReturn)
# 返回时间序列
return(input)
}
计算年化收益、标准差和夏普比率。
# 获取短期、中期和长期政府债券的收益率序列
from = "2001-01-01"
to = "2011-12-16"
tlt = importSeries("tlt",from,to)
shy = importSeries("shy",from,to)
ief = importSeries("ief",from,to)
merged = merge(tlt,shy) %>% merge(ief)
vars = c("tlt.Return",
"shy.Return",
"ief.Return")
# 计算年化收益率 (t = table.AnnualizedReturns(merged[,vars], Rf = mean(merged[,"shy.Return"], na.rm=TRUE)))
## tlt.Return shy.Return ief.Return
## Annualized Return 0.0810 0.0303 0.0684
## Annualized Std Dev 0.1403 0.0173 0.0740
## Annualized Sharpe (Rf=3%) 0.3496 -0.0086 0.4974
结果如下:
首先, 将风险定义为投资组合的方差。虽然有各种各样的理由不使用方差来界定风险,但它是从最古老的 50 年代开始这种类型的分析都是全新的,定义收益为预期收益。在上面的表中,年收益率表示持有资产的预期收益为 1 年,标准差的平方及方差表示风险。假设投资组合只包括持有长期和短期债券,便于需要计算投资组合的预期收益和风险。收益的计算是很容易的, 这是两种持仓的加权平均收益,权重就是每个资产的投入资本百分比。
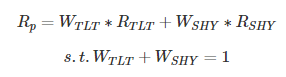
显然这两种资产具有相关性 (在马科维茨于 1952 年的博士论文发表之前, 投资经理不了解相关性并且默认假设为 1 - 马科维茨因此获得了诺贝尔奖)。假设收益是正态分布的,那么投资组合方差将是:
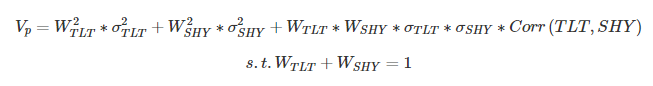
基于上述知识改变持仓权重并为杠铃策略建立风险收益模型。
# 检查相关性
corr = cor(merged[,vars],use = "complete.obs")
c = corr["tlt.Return","shy.Return"]
# 假设一个杠铃策略是持有长期和短期资产
# 定义风险、收益
ws = NULL
wt = NULL
mu = NULL
sigma = NULL
# 50个观察 n=50
# 遍历杠铃策略的权重
rTLT = t["Annualized Return","tlt.Return"]
rSHY = t["Annualized Return","shy.Return"]
sTLT = t["Annualized Std Dev","tlt.Return"]
sSHY = t["Annualized Std Dev","shy.Return"]
for (i in 0:n){wsi = i/n;
wti = 1-wsi;
mui = wsi * rSHY + wti * rTLT
sigmai = wsi*wsi*sSHY*sSHY + wti*wti*sTLT*sTLT + wsi*wti*sSHY*sTLT*c
ws = c(ws,wsi)
wt = c(wt,wti)
mu = c(mu,mui)
sigma = c(sigma,sigmai) }
#风险收益的数据集
rrProfile = data.frame(ws=ws,wt=wt,mu=mu,sigma=sigma)
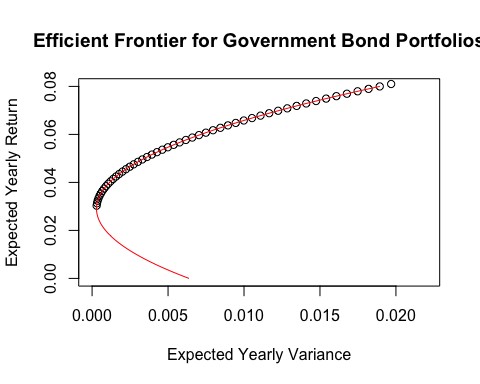
注意, 上面的方程是二次的,可以配合刚刚创建的点画出抛物线。注意,通常收益数据会放在 X 轴上,而把拟合方差 (风险) 数据作为因变量放在 Y 轴。
# 为模型拟合一个二次函数
fit = lm(rrProfile$sigma ~ rrProfile$mu + I(rrProfile$mu^2))
接下来,在图上添加拟合线。
# 得到回归系数
coe = fit$coefficients
# 得到每个回归预测的风险值
muf = NULL
sfit = NULL
for (i in seq(0,.08,by=.001)){
muf = c(muf,i)
s = coe[1] + coe[2]*i + coe[3]*i^2
sfit = c(sfit,s)
}
# 绘图
plot(rrProfile$sigma,
rrProfile$mu,
xlim=c(0,.022),
ylim=c(0,.08),
ylab="Expected Yearly Return",
xlab="Expected Yearly Variance",
main="Efficient Frontier for Government Bond Portfolios")
# 画出预测边值
lines(sfit,muf,col="red")
tseries 包中的 portfolio.optim 比较而言更好用。只需要输入预期收益率, 该函数会直接返回出来最优组合权重。在最低预期收益率 (比如 100% 持有 SHY) 到最高预期收益率 (比如 100%持有 TLT) 之间修改输入的收益。注意,portfolio.optim 会使用日收益率做计算,因此代码将不得不做一些处理并假设一年有 255 个交易日。
# 添加第三个标的
#除非想做一个格点搜索,否则就需要对每个级别的收益减少风险来优化投资组合。
# portfolio.optim 在时间序列中不能有 NA 值。
m2 = removeNA(merged[,vars])
wSHY = NULL
wIEF = NULL
wTLT = NULL
er = NULL
eStd = NULL
# 在收益水平之间不断循环搜索找到最优的投资组合,包括最小值(rSHY)和最大值(rTLT)
# portfolio.optim 使用日收益数据,因此不得不做出相应的调整
for (i in seq((rSHY+.001),(rTLT-.001),length.out=100)){
pm = 1+i
pm = log(pm)/255
opt = tseries::portfolio.optim(m2,pm=pm)
er = c(er,exp(pm*255)-1)
eStd = c(eStd,opt$ps*sqrt(255))
wTLT = c(wTLT,opt$pw[1])
wSHY = c(wSHY,opt$pw[2])
wIEF = c(wIEF,opt$pw[3])
}
# 绘图
plot(rrProfile$sigma,
rrProfile$mu,
xlim=c(0,.022),
ylim=c(0,.08),
ylab="Expected Yearly Return",
xlab="Expected Yearly Variance",
main="Efficient Frontier for Government Bond Portfolios")
# 画出预测边值
lines(sfit,muf,col="red")
# 画出三个标的的有效边界。
lines(eStd^2,er,col="blue")
legend(.014,0.015,c("Barbell Strategy","All Assets"),
col=c("red","blue"),
lty=c(1,1))
solution = data.frame(wTLT,wSHY,wIEF,er,eStd)
如下图:
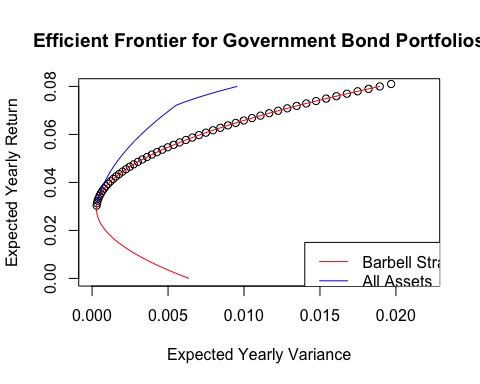
总资产组合中有效边界的蓝线表示其优于杠铃策略。对于每个风险水平,预期收益都更高。从图表上看, 这表明添加 IEF 到组合将优化组合。进一步,看到杠铃策略收益的逼近最大值,用三个标的组合的组合策略比之前的风险少了一半。
在前面的文章中,构建了一个投资组合的有效边界的债券,下一步,要找到超级有效的 (或市场) 的投资组合。如果您有不熟悉的概念, 第二部分可以在维基百科上参考一些资料。
如果你不愿意看维基百科,我也会解释相关概念的。如果你有一个保底收益率 (无风险利率), 那么资产位于图表的 y 轴。在边界的切点处画一条切线,切点代表着非常有效的投资组合。你可以混合持有一定权重的组合标的和无风险资产, 实现比边界曲线更好的风险收益比。明白了吗?非常棒!所以需要找到线和切点。首先,让假定一个无风险利率。有些人会使用 3 个月的国债收益率。为了和数据匹配,需要将它处理成一年期的。我的银行给我一个 2% 的年保底收益率,所以我将用 2%。
如何找到切点?当有两个标的时,存在一个二阶多项式。当有三个标的时有一些存在缺陷的面(非凸时求极值较困难),在这种情况下应该停止投资 SHY,转向投资 TLT。拟合高阶多项式,但不能确保有一个凹面。或者可以说, 不能保证切点总是高于边值。同样地,也可以想象一下二次的情形或许有切点存在负值。作为一个例子,这里虽然六阶多项式的拟合符合缺陷, 但切线点不是有用的。只有一个实根,其余的都是虚根,需要另一种方法。为第一部分里的边值拟合一个多项式;此时在持仓组合中只有 SHY 和 IEF。虽然这样也行得通,但是这不太通用。想找到一个可以不管是什么边值形状都适用的通用解决方案。




