kNN (k-Nearest Neighbour) 算法是一种用于分类和回归的非参数的方法,可以用目标点周围所观察到的数据得平均值来预测出目标点 x 的值。本文将会介绍kNN的回归和分类算法,交叉验证和kNN算法的缺点。
1)kNN回归:
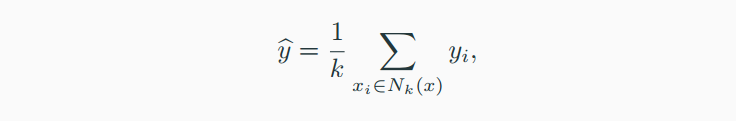
其中N{k}(x)是训练样本中离目标x最近的k个样本。根据以上公式,我们可以看出在预测y的值时,kNN算法是求在训练样本中离x周围最近的k个样本所对应y值们的平均值。以R语言为例,我们需要安装“kknn”包,简单的1NN例子如下:
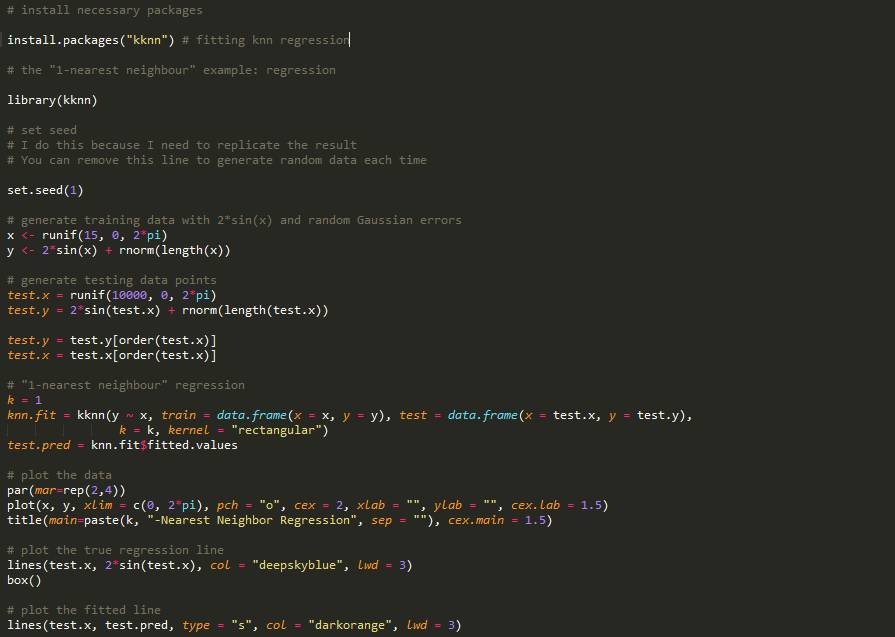
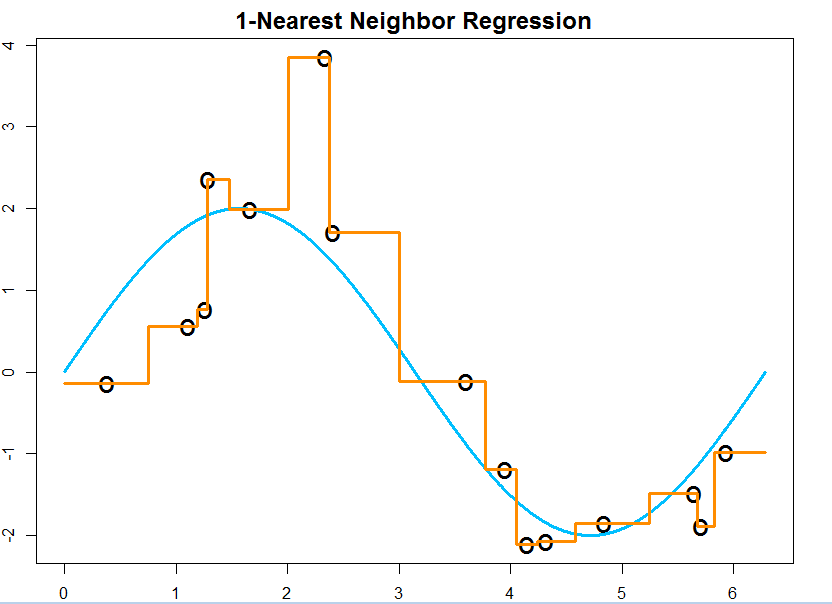
我们可以得到以下fit的结果:
2) kNN分类:
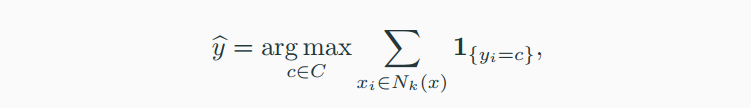
仍以R语言为例,
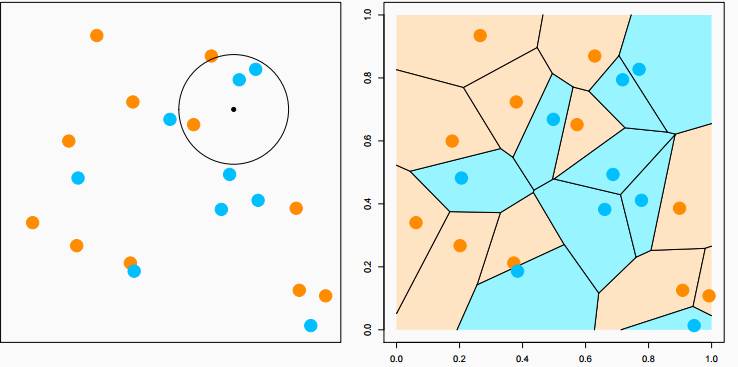
如上图所示,在预测左图中小黑点的分类时,我们在k为半径的一个圆中发现蓝色点的数量大于橙色点的数量,根据kNN算法,我们把目标点归为蓝色点类。当k=1时,我们能得到上右图分区,称作“Voronoi tessellation"。图中的线段皆是两点的垂直平分线。
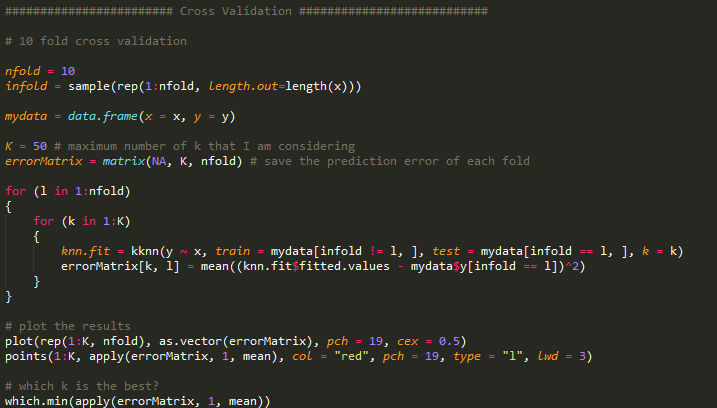
3.交叉验证:
不少读者看到这里会好奇,在kNN模型中到底什么样的k最符合我的预测模型呢?
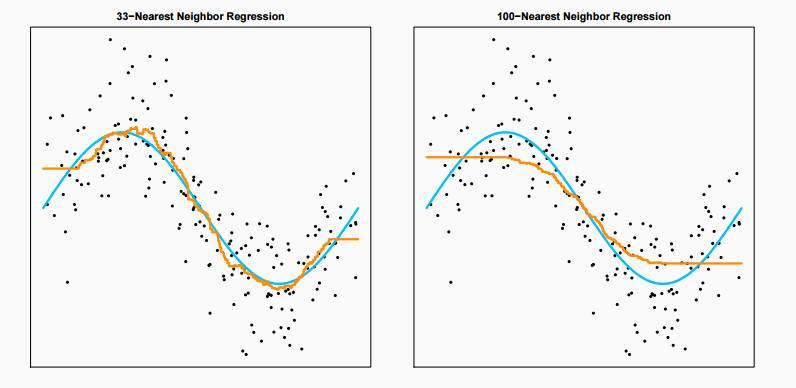
从上图中发现,33NN模型由于方差较小显著优于1NN。然而,当k增加到100时,误差变得尤为显著。我们需要在误差和方差选择一个这种方案:
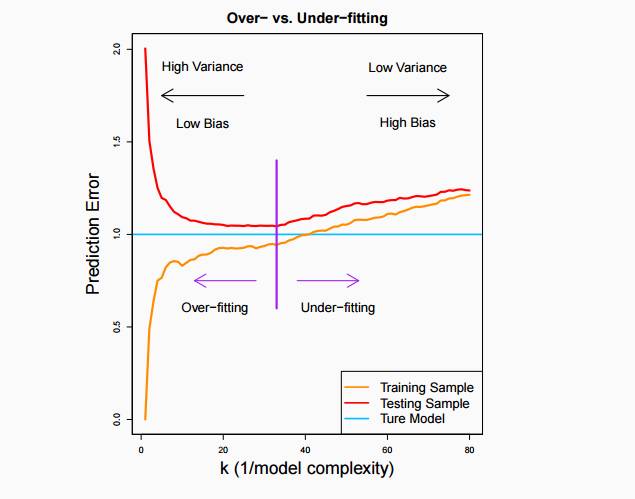
在寻找平衡点时,我们可以用交叉验证方法寻找最优解。
(1)将训练样本随机分成10组
(2)其中9组作为训练样本,应用k*NN模型;剩下的一组作为模型测试样本记录误差
(3)重新再10组里选择9组作为训练样本,重复10次
(4)平均10次实验的误差,最小的即为最优k。
简单的R代码实现如下,我们得到最佳的k值是33。
4.kNN的缺点:
虽然kNN模型具有容易实现,简单快捷的优点。但在平时建立模型是我们需要注意,kNN模型在每次预测时需要储存所有的训练样本数据,因为在预测时需要返回训练样本找邻近的所有k个点。其次,kNN模型对样本的异常值较为敏感,建立模型是,需要对数据进行预处理降低异常值对结果的影响。




