一、置信区间
置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度。
样本均值和总体均值是不同的。一般来说,我们想知道一个总体平均,但我们只能估算出一个样本的平均值。那么我们就希望使用样本均值来估计总体均值。我们使用置信区间这一指标,试图确定我们的样本均值是如何准确地估计总体均值的。
如果我们要估计中国女性的平均身高,我们采用的方式可能是先选出一百或者一千位女性,测量她们的身高然后计算出平均值,用这个平均值来估计全中国女性的身高值。
首先导入需要的程序包。

生成样本值和样本均值。
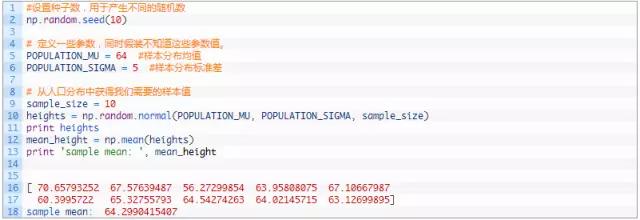
简单地列出样本均值对我们来说并没有多大的作用,因为我们不知道它与总体均值的相关性如何。要获得这个相关性,我们可以计算出样本方差是多少。较高的方差代表了较大的不稳定性和不确定性。下面我们获取样本的标准偏差值。

对我们来说,这个值仍然不会有太大的意义,为了真正理解样本均值与总体均值的相关性,我们需要计算标准误差值。标准误差是样本均值的方差的一种度量方法。
标准误差值:

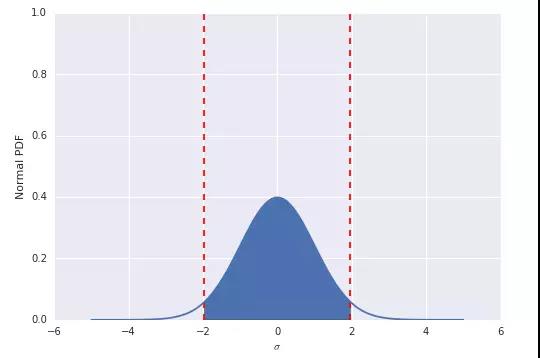
下面我们来获得置信区间为95%时的正态分布的二维图。
结果如下:
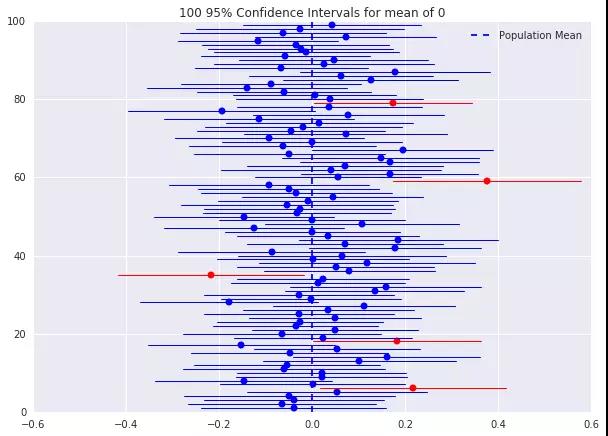
事实上,对于一个单一的样本和由它得来的单置信区间,我们无法得出总体均值落在这个区间内的概率是多大,下面的例子说明了这一事实。
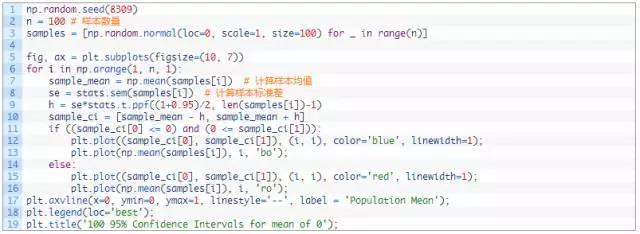
如图所示:
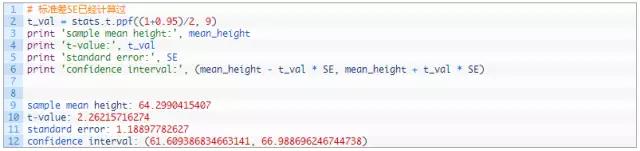
深度讲解:下面使用t检验来计算置信区间。
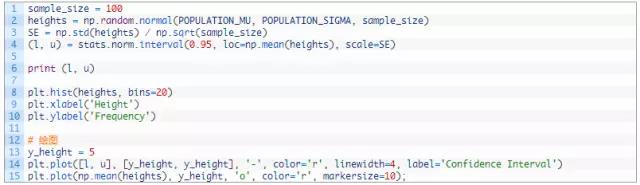
有一个内置的函数scipy.stats可以计算置信区间,记住要指定自由度!

对于正态分布,还有一个内置的函数可以计算置信区间,这个函数不需要指定自由度。

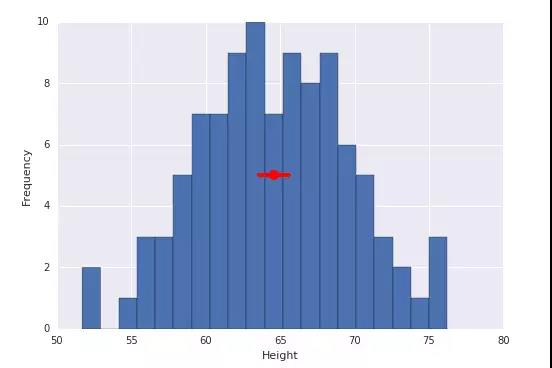
下面是一些可视化图形上的置信区间的代码:
结果如下:
标准偏差,标准误差和置信区间的计算都依赖于一定的假设。如果违反这些假设,那么95%的置信区间的可信度将会降低。我们说,在这种情况下的置信区间是非校准的。下面是一个例子。
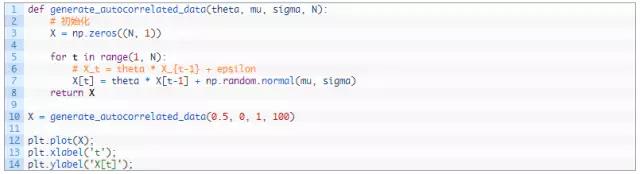
执行结果为:
事实证明,对于较大的样本量,我们应该看到样本均值渐近收敛到零。

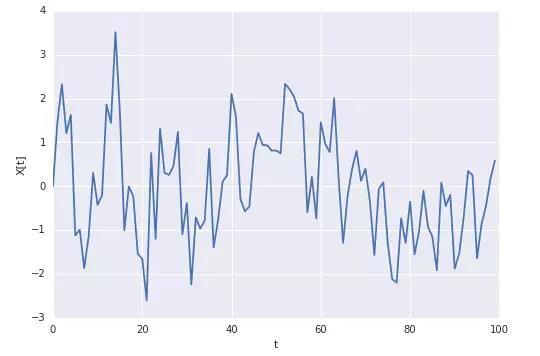
结果如下:
从图中可以很明显的看出结果慢慢收敛,我们也可以查看一下样本均值的均值。

可以看出结果相当接近0,那么就象征性地认为它是0吧。既然我们知道了总体均值,我们还可以检验置信区间的准确性。首先编写2个辅助函数,用以计算输入数据的置信区间以及判断是否区间内是否包含0。
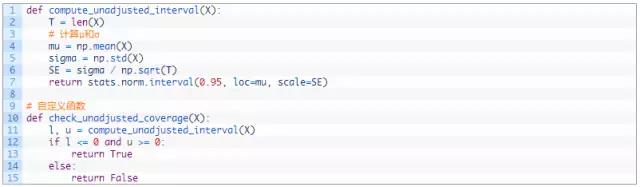
多次调用函数,每次都利用采样数据计算出一个置信区间,然后检查该区间是否包含了总体均值。如果区间得到正确的校准,我们应该会看到95%的区间包含了总体均值。

很显然结果是不正确的,在这种情况下,我们需要做的是在考虑到自相关的情况下修正我们的标准误差估计。




