在上一篇推文中,提到了如何运用序列建模进行机器翻译,机器翻译系统主要包含编码器和解码器,编码器负责将待翻译的句子进行特征表示,而解码器则负责将此特征用另外一种语言表示出来。神经机器翻译模型(Neural Translation Machine,以下简称NTM)的编解码系统如下图所示:
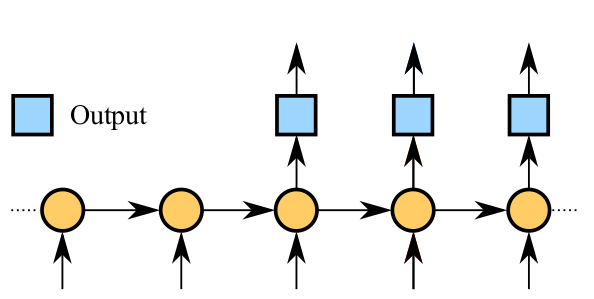
语言模型相比NTM要简单很多,原因是语言模型只涉及一种语言之间的关联,没有编码器、解码器之分。最常见的运用RNN搭建的语言模型如下图所示:
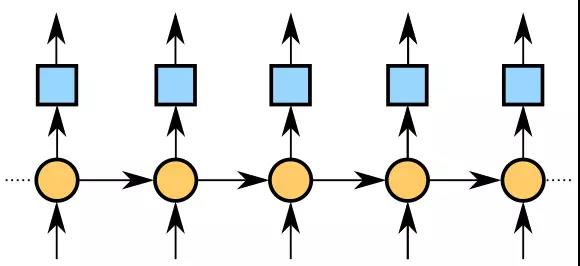
语言建模通常有两个作用,第一是衡量一句话是否合理,譬如说,我们可以用训练好的中文语言模型来评估『今天是星期五』这句话通顺的可能性有多大,或者说混乱度是多少(专业术语是perplexity);第二是用来预测语句序列,即机器造句,比如我们可以给定一个种子序列作为造句的开头部分,然后机器就可以根据该种子序列继续生成后面的句子。
传统的语言模型通常使用统计的方法来得到,常见的统计模型有N-gram或者马尔科夫链,其原理是先根据训练语料计算所有单词的转移概率,然后根据此转移概率计算一句话的perplexity,或者是给定一个种子序列,然后由转移概率随机抽样生成新的句子。
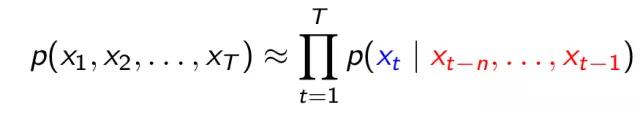
例如,我们要用bi-gram语言模型来评估『今天是星期五』这句话的是否通顺,我们可以计算整句话出现的概率,计算的流程如下:
句子以“今”开头的概率是多少
“今”后面紧邻“天”的概率是多少
“天”后面紧邻“是”的概率是多少
“是”后面紧邻“星”的概率是多少
“星”后面紧邻“期”的概率是多少
“期”后面紧邻“五”的概率是多少
然后把上面所有概率相乘起来,即可得到『今天是星期五』这句话出现的可能性有多大。
传统的语言建模过程是一个无参建模过程,因N-gram的计算过程是不含参数的,其优点是计算量比较小,无需迭代调参,统计词频即可。其缺点主要有两点:第一,计算的概率具有稀疏性,假设出现的单词数量为|V|,然而对于bi-gram而言,并不是|V|*|V|个概率都有被计算,因此如果“是星”在源训练集中没有出现,那么『今天是星期五』出现的概率等于0,这显然是不合理的;第二,这种统计模型不具备泛化能力,即如果“星期四”出现在数据库中,而“星期五”没有出现在数据库中,那么这个时候出现的概率为0,但是,如果这个模型具有泛化能力的话,显然“星期五”与“星期六”是同类的词语,因此出现的可能性应该是一样的。
运用神经网络进行语言建模就可以有效解决以上两个缺点,由于语言也是一种时序问题,因此我们一般采用RNN/LSTM进行建模,目的是使得模型具备长期记忆性,从而可以保证语言模型在判断或生成长句子时更加符合语法规则。
那么如何运用LSTM进行语言建模呢?在训练之前,我们需要得到数据集。由于语言建模是一个监督学习问题,因此我们需要得到(X,Y)这样的训练对。假设我们这里进行的是单词水平的语言建模,即以一个单词为单位,所以我们为了得到(X,Y)这样的训练对,比如训练样本是一句“How are you",我们可以把X设为['How','are'],把Y设为['are','you'],这样设定好之后,如果网络输入'How'这个单词,那我们的标准输出应该是'are',建立了一一对应的时序关系。
数据集构建好了之后,就开始构建模型了。首先,我们对每个单词做一个one-hot编码,由此编码再得到每个单词的特征向量表示,这个过程我们称为word embedding。
第二步,假设我们要构建一个三层LSTM网络,我们就可以把第一个单词作为RNN网络的输入x_t-1,经过计算得到最上面隐含层状态h_t-1,然后由h_t-1经过一个softmax层即可计算P(x_t|y_t-1)是多少。
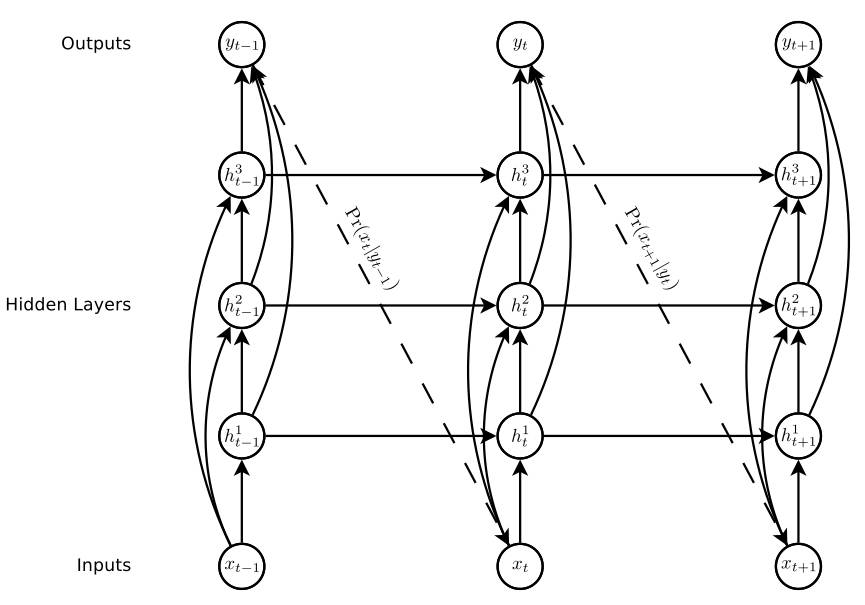
第三步,将该概率值传到输入层作为第二时刻的输入x_t,然后经过三个循环隐含层即可计算得到h_t,同理,可以算出P(x_t+1|y_t)的值。
重复以上步骤,直到训练了整个mini-batch,接下来根据最大似然估计法则确定目标函数的表达式,训练过程中的目标是使得整句话出现的概率最大,因此目标函数可以写为:
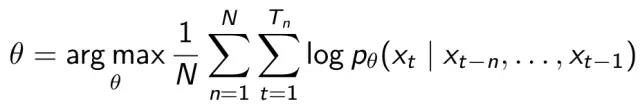
即:
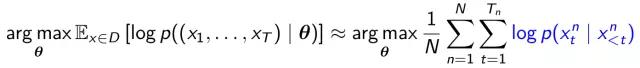
然后就可以使用后向传播算法进行参数更新。
当模型训练好了以后,我们就可以使用这个模型来造句了。造句的方法就是抽样,但是我们必须先给定一个种子序列,例如"I am",然后将"I"和"am"分别输入到网络中,得到y_3的值,然后依概率进行抽样即可得到第三个单词...根据上图的计算流程,我们可以生成无限多个单词组成的句子。
除了单词水平的语言建模以外,常见的还有字母水平的语言建模,对于字母水平的语言建模,其好处就是可以生成OOV(out of vocabulary)的单词,不过字母水平的建模要比单词水平的更难一些,因其要求模型具有更长的时序记忆性。
值得注意的是,机器造句的实际效果不仅与训练语料库的大小有关,还与模型的好坏有关。如果使用RNN进行语言建模,那么其长期记忆性是非常差的,造出来的句子经常会不通顺。可以改善的方法有:使用深层LSTM模型、使用基于注意力的模型、使用外部memory的网络、使用深度强化学习等等,至于这些方法具体如何运用,后面几期会慢慢介绍。




