1. 关联分析
关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。比如,在著名的购物篮事务(market basket transactions)问题中,

关联分析则被用来找出此类规则:顾客在买了某种商品时也会买另一种商品。在上述例子中,大部分都知道关联规则:{Diapers} → {Beer};即顾客在买完尿布之后通常会买啤酒。后来通过调查分析,原来妻子嘱咐丈夫给孩子买尿布时,丈夫在买完尿布后通常会买自己喜欢的啤酒。但是,如何衡量这种关联规则是否靠谱呢?下面给出了度量标准。
支持度与置信度

暴力方法
若(对于所有事务集合)项的个数为dd,则所有关联规则的数量:
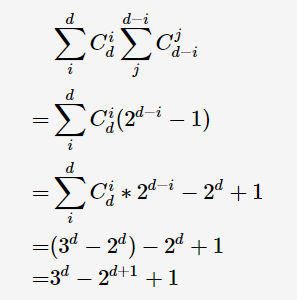
如果采用暴力方法,穷举所有的关联规则,找出符合要求的规则,其时间复杂度将达到指数级。因此,我们需要找出复杂度更低的算法用于关联分析。
2. Apriori算法
Agrawal与Srikant提出Apriori算法,用于做快速的关联规则分析。
频繁项集生成
根据支持度的定义,得到如下的先验定理:
定理1:如果一个项集是频繁的,那么其所有的子集(subsets)也一定是频繁的。
这个比较容易证明,因为某项集的子集的支持度一定不小于该项集。
定理2:如果一个项集是非频繁的,那么其所有的超集(supersets)也一定是非频繁的。
定理2是上一条定理的逆反定理。根据定理2,可以对项集树进行如下剪枝:
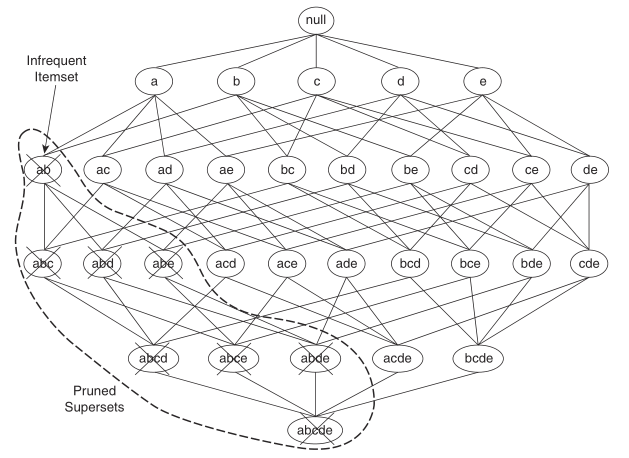
项集树共有项集数: 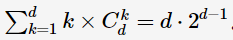 。显然,用穷举的办法会导致计算复杂度太高。对于大小为k−1的频繁项集Fk−1,如何计算大小为k的频繁项集Fk呢?Apriori算法给出了两种策略:
。显然,用穷举的办法会导致计算复杂度太高。对于大小为k−1的频繁项集Fk−1,如何计算大小为k的频繁项集Fk呢?Apriori算法给出了两种策略:
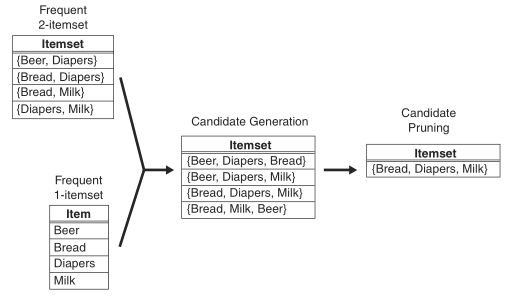
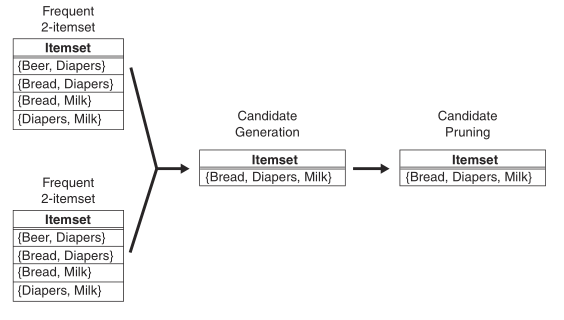
1.Fk=Fk−1×F1方法。之所以没有选择Fk−1与(所有)1项集生成Fk,是因为为了满足定理2。下图给出由频繁项集F2与F1生成候选项集C3:
2.Fk=Fk−1×Fk−1方法。选择前k−2项均相同的fk−1进行合并,生成Fk−1。当然,Fk−1的所有fk−1都是有序排列的。之所以要求前k−2项均相同,是因为为了确保Fk的k−2项都是频繁的。下图给出由两个频繁项集F2生成候选项集C3:
生成频繁项集Fk的算法如下:

关联规则生成
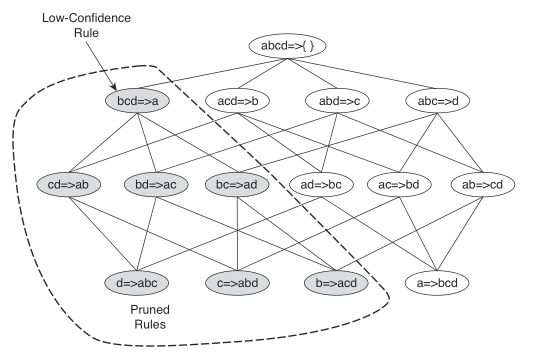
关联规则是由频繁项集生成的,即对于Fk,找出项集hm,使得规则fk−hm⟶hm的置信度大于置信度阈值。同样地,根据置信度定义得到如下定理:
定理3:如果规则X⟶Y−X不满足置信度阈值,则对于X的子集X′,规则X′⟶Y−X′也不满足置信度阈值。
根据定理3,可对规则树进行如下剪枝:
关联规则的生成算法如下:





