先说一个事引出这个博客的内容,我最近投的一篇论文被拒稿,用到的方法使SVM(很惭愧,还在用20年前的算法,当然这并不是重点),审稿意见里面有一段话是这样说的(说的很中肯):“该方法本身的特点来看就很难达到100%正确率”,当然这并不是说SVM无法做到100%,我理解的很难达到的原因就是在于SVM算法本身的松弛因子的引入。
从前面四个内容来看,SVM理论可以完美的找到正负样本间的最大的分类间隔,这意味着不仅仅可以实现对训练数据的分类,还保证了决策平面是最理想的。那么SVM为什么还要引入松弛因子呢?我们可以看下面这个例子:
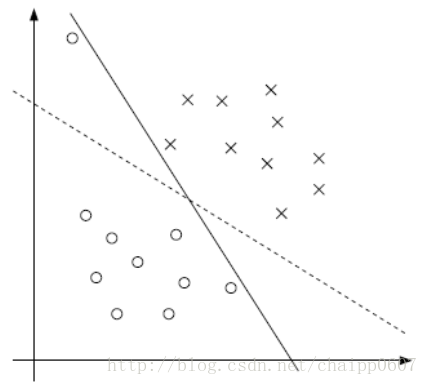
实线的决策平面分开了所有的正负样本,但是造成的结果是最大分类间隔非常小,而虚线虽然没有完全区分开所有的正负样本,但是保证了分类间隔更大,这个例子可以说明,不一定实线完全分类的决策平面就是最好的。
同时,还有一种情况,如果左上角的圆再向右侧移动的话,那么样本的数据本身就是线性不可分的。
综合上面的两点考虑,SVM引入了松弛因子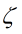 。
。
在原有的约束条件上加入一个松弛因子,要求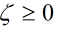 ,那么约束条件变为:
,那么约束条件变为:
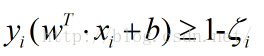
很显然,由于松弛因子是一个正数,那么新的约束条件一定没有原来的条件“严格”,也就是松弛了。
同时,目标函数同样发生变化:
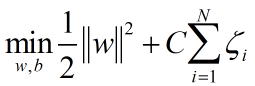
这个目标函数的变化是通过间隔松弛向量的范数定义的泛化误差界推导的出来,但是这不是SVM的重点,重点在于改变的目标函数对决策平面的影响。
除了一阶软间隔分类器,SVM的目标函数还有二阶软间隔分类器的形式:
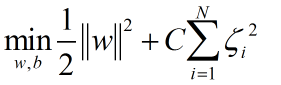
而无论是上述哪种情况,实际上都是为目标函数引入一个损失,而上面的参数C被称之为惩罚因子。
惩罚因子的大小决定了对离群点的容忍程度(松弛的程度),比如,如果C是一个非常大的值,那么很小的松弛因子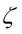 都会让目标函数的值边的很大,然后目标是在求一个最小值,这就意味着哪怕是个很小的松弛都不愿意容忍。还有一种极端的情况是如果C选定成一个无穷大的值,那么软分类间隔问题(soft margin)会退化称为一个硬分类间隔问题(hard margin)。
都会让目标函数的值边的很大,然后目标是在求一个最小值,这就意味着哪怕是个很小的松弛都不愿意容忍。还有一种极端的情况是如果C选定成一个无穷大的值,那么软分类间隔问题(soft margin)会退化称为一个硬分类间隔问题(hard margin)。
可以拿一个很直观的例子说明惩罚因子C的影响,C越大意味着对训练数据而言能得到很好的分类结果,但是同时最大分类间隔就会变小,毕竟我们做模型不是为了在训练数据上有个多么优异的结果。相反的,如果C比较小,那么间隔就会变大,模型也就有了相对而言更好的泛化能力。
最后新的目标函数(采用一阶范式):
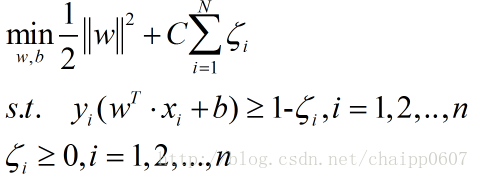
这里的约束条件是2n个。
在前面我们就已经知道,有了目标函数之后,后面的工作就是引入拉格朗日乘子,对偶问题转化后求导,解出拉格朗日乘子后反带回去求w和b,这个讨论对于引得目标函数来说是一样的,而且推导的过程在前面四部分中解释的已经非常清楚,对于新的问题,只是加了两个参数:
1.目标函数本身多出来的一个松弛因子。
2.拉格朗日乘子法为新的约束条件引入的参数。
需要注意的是,参数C是一个已知量,是人为设定的!
拉格朗日函数:
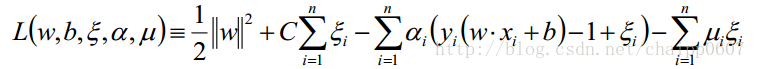
其中,a和u是拉格朗日乘子,对偶后就变成了:
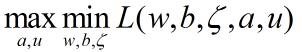
解决min问题,求偏导:
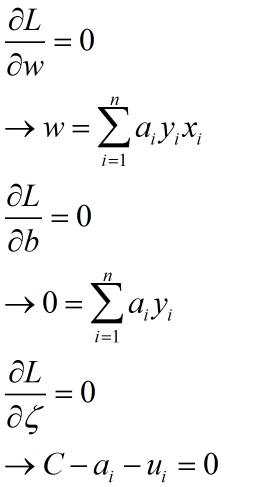
将三式带入到L中求得:
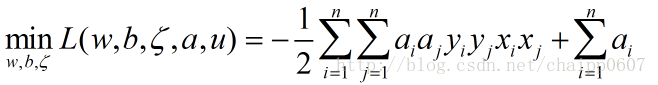
带入到上面的对偶问题中:
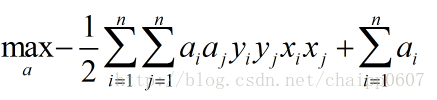
再次转化问题:
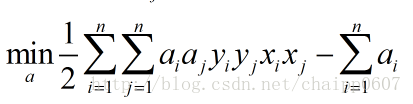
此时的约束条件为:
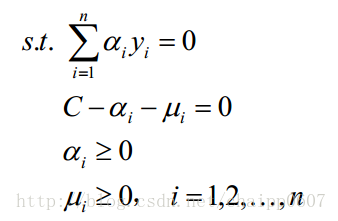
这个约束条件中的后三个是可以转化的,因为u是一个大于等于0的数(拉格朗日性质决定的),同时由于C-a=u,即C-a>=0。同时由于a>=0,后三个条件最后就变成:
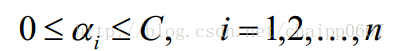
那么最后整理得到的对偶问题就是:
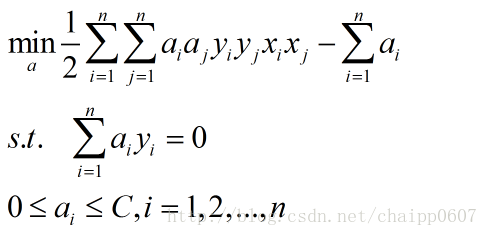
这个结果和学习SVM(三)理解SVM中的对偶问题最后的结果很像,只是多出了些约束。