1引言
一个初入量化投资的分析师经过了一个月的奋斗开发出了一个双均线趋势追踪模型后,兴冲冲的跑来和他的基金经理汇报,于是便有了下面这段对话。
上面这段对话当然是我杜撰的。想通过它表明的观点是,我们将不同的量化技术应用到同样的数据上构建某一类(比如趋势追踪、反转、套利)策略时,最终会挑出来表现最好的量化技术,无论这个技术复杂与否(线性的、非线性的),这个过程本身就是在过拟合。最终被挑出来的,注定是因为在样本内战胜了其他的。从“超参数”(见《科学回测中的大学问》)的意义上说,这个模型难逃 data mining 之嫌,因为它比别的模型更好很可能是因为它对样本数据内的噪音刻画的更精准,而非发现了一些被其他策略忽视到的真实存在于数据之间的因果关系。以上这点粗浅的认识当然不是鼓励大家放弃回测中表现好的、使用表现差的量化技术。就我自己有限的经验来看,任何策略都或多或少存在数据挖掘的问题,而这个问题随着模型复杂度的增加更加突出。
今天就简单聊聊模型复杂度。讨论主要从以下两个角度展开:
1. 模型复杂度和过拟合程度:定量分析模型复杂度和构建策略时 data mining 的程度。
2. 模型复杂度和损失带来的主观感受:回答诸如“面对实盘中同等大小 —— 比如 -10% ——的回撤,不同复杂度的模型是否能给我们带来同样的主观感受”这样的问题。
这两个角度的研究都是很大的课题,本文仅仅是做一点抛砖引玉的探讨。
2模型复杂度和过拟合程度
在构建一个量化投资策略时,一旦确定了模型复杂度,就要进行参数优化。只要是参数优化,无论再怎么小心,都会存在过拟合。本节使用趋势策略阐述在给定的模型复杂度进行参数优化和过拟合程度之间的关系。分析流程如下:
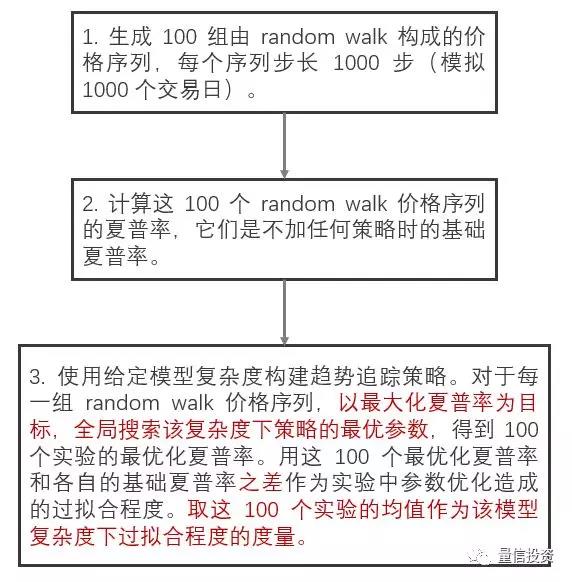
分析中采用的趋势追踪策略是均线多头排列策略。它的定义和模型复杂度介绍如下。
在市场有大趋势的时候,均线一般呈现多头或者空头结构,即不同周期 T 的均线排序和 T 的排序非常一致(比如上涨时,通常有 MA5 > MA15 > MA30)。当投资品从上涨向下跌转换、或由下跌向上涨转换时,短周期均线会先于长周期均线发生变化。在前者发生时,短周期均线开始逐步下穿长周期均线;在后者发生时,短周期均线开始逐步上穿长周期均线。在发生由涨转跌或由跌转涨时,不同周期均线的排序和时间窗口 T 大小的排序关系被打乱,不再完全一致。
使用秩相关系数计算均线排序和时间窗口 T 排序之间的一致性,并使用它择时、构建趋势追踪策略(这里只考虑多头策略)。当均线多头排列时,均线和 T 之间的秩相关性为 1;当均线空头排列时,均线和 T 之间的秩相关性为 -1。由涨转跌时,短期均线开始下穿,秩相关性从 1 开始下降;由跌转涨时,短期均线开始上穿,秩相关性从 -1 开始上升。由此,可以构建策略如下:
使用给定的均线参数周期,各自计算指数平均,进而计算均线排序和参数排序的秩相关系数。空仓时,如果秩相关系数上穿 -TH 则满仓;满仓时,如果秩相关系数下穿 TH 则空仓。不考虑任何成本。
在这个策略中,模型复杂度由如下两组参数刻画:
1. 计算均线的周期参数个数;
2. 判断空仓和满仓时,秩相关系数的阈值。
这两组参数各自从不同层面增加了模型的复杂程度。在分析中,它们的取值如下:
1. 均线参数的个数从 2 到 5 递增,依次增加模型的复杂度。第一个均线周期取值范围是 10 到 100,步长 10;从第二个均线周期开始,在搜索参数时,其取值范围似是前一个均线的取值与 100 之间,步长 10。此外,允许新加入的均线对策略不产生作用。这保证了随着均线个数增加,求解的空间是递增的,从而保证了最优目标函数的单调性。
2. 在分析时,首先仅考虑均线参数个数造成的影响,因此假设阈值为 TH = 0.5 恒定。之后,为了同时考察阈值对过拟合程度的影响,允许阈值 TH 从 0.1 到 0.9 之间(步长 0.1)选择。
依照上述描述进行实验,得到的模型复杂度和过拟合程度的关系如下图所示。其中蓝色圆圈表示仅考虑均线参数个数这一种模型复杂度时的情况,而黄色十字表示同时考虑阈值作为模型复杂度的情况。
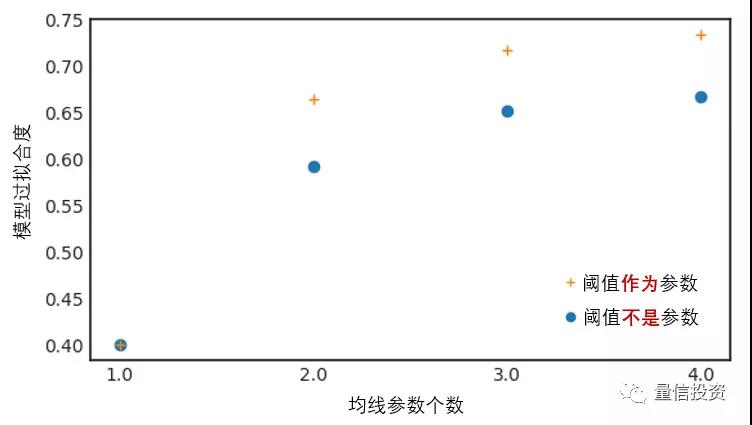
当我们使用真实的交易数据进行策略的参数优化时,尽管使用了训练集和测试集、考虑了参数平原、从各种业务层面解释了参数的选择,依然无法消除参数优化中过拟合的影响。更不幸的是,对于真实交易数据,由于不知道它其中哪些是因果关系、哪些是噪音,因此我们甚至无法评价参数优化造成的过拟合程度。
然而在上述实验中,由于价格序列由随机游走生成,因此随着实验个数的增加,我们预期它们的基础夏普率均值是 0。这正是使用 random walks 来验证策略的好处,因为它的“正确答案”是已知的 —— 一个不存在过拟合的策略在随机游走价格序列上不应该能持续的赚到钱。这 100 个 random walks 的基础夏普率均值为 -0.03。如果参数优化中没有过拟合,那么策略夏普率均值和基础夏普率均值相差不远。然而,分析的结果远非如此。上图表明,随着参数的增多,模型的过拟合程度(100 个策略夏普率均值于基础家谱率均值之差)也在上升;而随着模型复杂度从**度的提升(即加入阈值参数),模型的过拟合程度产生了跳变。
上述结果说明模型的过拟合程度随模型的复杂度递增。
3模型复杂度和损失带来的主观感受
本节来看看模型复杂度和策略损失带来的主观感受之间的关系。
《追求卓越,但接受交易中的不完美》一文曾阐述了如下观点:一个策略投放到实盘时最大的敌人是交易者的心理关。这个心理关指的是交易者能否克服实盘中的心理压力从而坚持使用这个策略。对于任何一个量化投资策略,几乎可以确定的是它在回测中的表现是其在实盘中表现的上限。在实际交易中,价格时刻在波动,充斥着噪音的各路消息以远超过我们能够接受的速度涌来,使人快步踏入行为金融学中的各种认知偏差陷阱、丧失冷静;面对真金白银的亏损,交易者会比想象的更脆弱、更容易怀疑策略的开发中是否存在没有考虑到的问题(对于复杂策略更是如此)、自我动摇想要放弃这个系统 —— 这就是损失带来的主观感受。
当一个策略持续出现回撤,亏损超过回测中最大回撤时,复杂度是否对亏损带给我们的痛苦程度(以及对策略不自信的程度)造成影响呢?为了回答这个问题,自然要建模。建模的流程如下图所示。
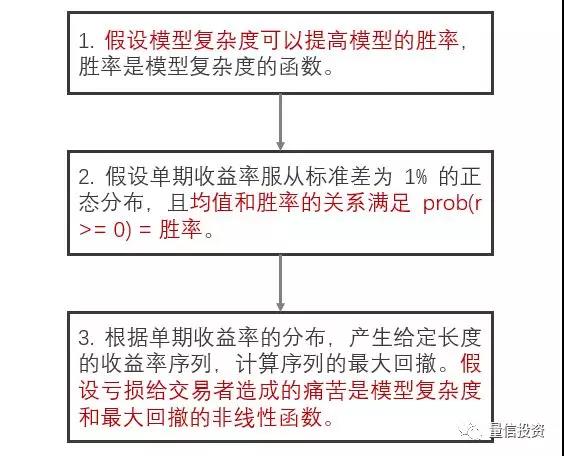
这个流程中有三处需要建模:(1)模型复杂度和胜率的关系;(2)胜率和收益率分布均值的关系;(3)模型复杂度和最大回撤与亏损造成的痛苦的关系。下面分别说明。
假设模型复杂度和胜率的关系如下:
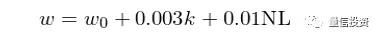
其中 w_0 是基础胜率(假设等于 0.5),k 代表模型中参数的个数,NL 为 binary 变量,取值 0 或者 1,代表模型是否为非线性的(NL = 1 表示非线性)。Disclaimer:本模型没有任何 reference,只是我为了得到量化分析结果选用的一个简单模型。假设单期收益率满足标准差为 1% 的正态分布,均值则和胜率有关。胜率代表着单期收益率大于等于零的概率,因此我们必须选择均值以满足 prob(r ≥ 0) = w。根据这个关系,可以求出均值为:
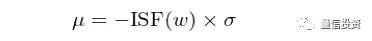
其中 ISF 表示标准正态分布的 inverse survival function。
得到单期收益率的分布之后,就可以构建任意长度的收益率序列。分析中,我们构建长度为 1000 的序列,以此作为该复杂度下假想策略的收益曲率序列的一个实现,并计算出它的 NAV。有了 NAV 就可以计算出它的最大回撤(max drawdown,MDD)。假设亏损造成的痛苦(记为 H)和最大回撤以及模型复杂度的关系如下:
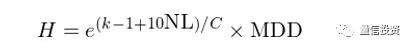
上述模型(disclaimer:同样没有任何 reference)说明 H 由两部分组成:模型复杂度和最大回撤。由该模型的表达式可知,在同样的最大回撤下,不同的模型复杂度给人的主观感受是不一样的,模型复杂度非线性的放大了亏损造成的痛苦。当 k = 1(模型至少有一个参数)且模型为非线性(NL = 0)时,H 的第一项为 1,因此它仅由最大回撤决定。当模型复杂度上升时,对复杂模型的惩罚程度由参数 C(非负实数)控制。C 越小说明对模型复杂度的惩罚越高(即复杂模型会显著放大最大回撤造成的痛苦程度)。结合上述胜率和痛苦程度的模型可知,模型复杂度可以增加胜率(hopefully),但它是以提高亏损造成的主观痛苦为代价的。因此,在这二者之间存在一个平衡。
下面来看一些实验结果。对于每一个给定的模型复杂度,随机产生 2000 个长度各为 1000 的收益率序列,并计算它们的最大回撤以及痛苦程度 H,取这 2000 个实验的均值作为该模型复杂度下损失造成的痛苦程度的度量。首先考虑线性模型,即 NL = 0 的情况。下面三张图分别显示了 C 取不同数值时,参数个数 k 和 H 的关系:
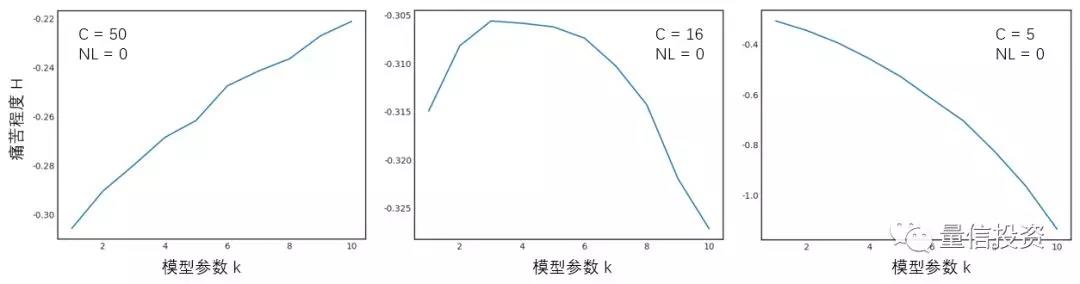
当 C 很大时,我们对模型复杂度的惩罚很低,模型复杂度的作用单边体现在提高胜率上。更高的胜率意味着更低的最大回撤,因此随着模型参数的增加,痛苦程度逐渐降低。当 C 很小时,情况正好相反。模型每增加一个参数,造成的痛苦程度非线性急速攀升,大大的抵消掉高胜率造成的低回撤的影响,痛苦程度随模型复杂度单调上升。当 C 取值中规中矩时,从上面中间的图中能够观察到胜率和痛苦程度之间的取舍,在理论上存在最佳的模型复杂度。
当 NL = 1 时,可以观察到和前面类似的结果(下图)。由于在 H 的建模中,我们对 NL 的惩罚较高(系数为 10),因此对于同样的 C 和 k,NL = 1 比 NL = 0 意味着更大的亏损痛苦。
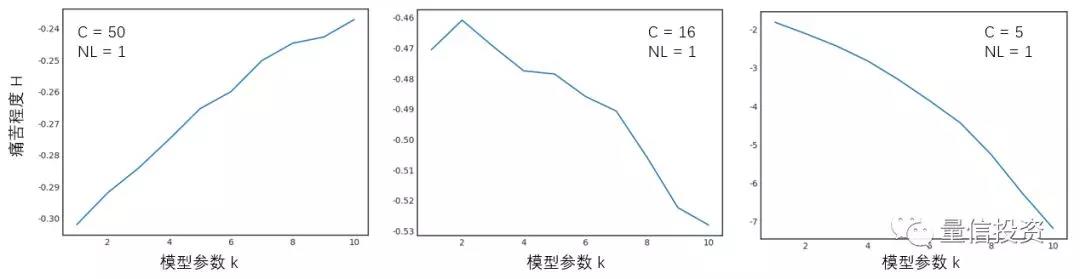
上面的分析都是探索性的,并没有实证数据作为依据(难以找到使用不同模型复杂度策略的投资者并统计它们面对亏损时的不同感受)。我分析的初衷是,在构建投资策略时,任何决定都要在得与失之间取舍。复杂模型在提高胜率的同时,也一定在某种程度上有它的弊端。从我有限的经验来说,在实盘中出现同样程度的亏损时,复杂的模型比简单的模型更让人不安。
在当下,我们越来越崇尚各种复杂的模型。本小节仅仅希望从一个完全不同的角度来提出一些思考:我们在样本外是否 100% 做好了准备接受复杂模型?交易中存在各种认知偏差,如果我们连最简单的按一根均线做趋势追踪都无法坚决的执行,那又有什么来保证我们在面对实盘亏损时能够坚守复杂模型呢?如果我们不能坚守复杂模型,那么开发复杂模型所付出的心血和努力是否付之东流呢?
4结语
前不久我听了 Vanguard 题为《先锋领航多资产 FOF 策略及外部管理人选聘概览》的报告。感触最深的是当谈到对策略的看法时,先锋的观点是策略的理念一定要简单 —— 能用一句话说清楚策略赚的什么钱,就不要用两句描述;策略的程序一定要可理解、完全透明。大道至简。借用老罗的一句话那就是:“ Simplicity is the hidden complexity.”
各种复杂模型带来的边际超额收益能否 justify 它们的复杂度呢?拭目以待。
 1人赞赏收藏
1人赞赏收藏