简单说:机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。用一张图说明它所包含的内容:
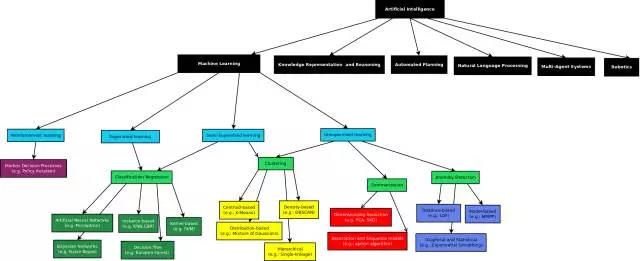
我们把目光集中到上图中的有监督学习,它是指数据中包括了我们想预测的属性,有监督学习有以下两类:
分类(Classification):样本属于两个或多个类别,我们希望通过从已标记类别的数据学习,来预测未标记数据的分类。例如,识别手写数字就是一个分类问题,其目标是将每个输入向量对应到有穷的数字类别。从另一种角度来思考,分类是一种有监督学习的离散(相对于连续)形式,对于n个样本,一方有对应的有限个类别数量,另一方则试图标记样本并分配到正确的类别。
回归(Regression):如果希望的输出是一个或多个连续的变量,那么这项任务被称作回归,比如用年龄和体重的函数来预测三文鱼的长度。
之前对这块没啥接触的伙伴,Andrew Ng 的课是不错的入门选择,另外这里还有一份关于它的笔记。
·········································································
scikit-learn是一个基于NumPy、SciPy、Matplotlib的机器学习包,主要涵盖了分类、回归和聚类等机器学习算法,例如knn、SVM、逻辑回归、朴素贝叶斯、随机森林、k-means等等,简言之:是一只强大的轮子。官网有个很好耍的例子:安德森鸢尾花品种亚属预测。
我们有一百五十个鸢尾花的一些尺寸观测值:萼片长度、宽度,花瓣长度和宽度。还有它们的亚属:山鸢尾(Iris setosa)、变色鸢尾(Iris versicolor)和维吉尼亚鸢尾(Iris virginica)。我们使用这些数据,从中学习并预测一个新的数据。在scikit-learn中,通过创建一个估计器(estimator)从已经存在的数据学习,并且调用它的fit(X,Y)方法。代码如下:

输出每日涨跌统计:
True 1379
False 1185
dtype: int64
可见过去十年中,有1379个交易日是上涨的,而1185个交易日下跌。画个图对比下:

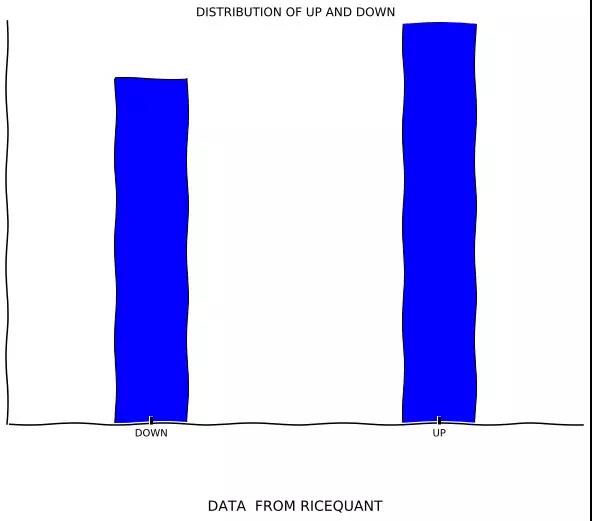
从图来看差距还是很明显,看来如果心情以每日涨跌来决定的话,快乐的时光还是更多的,真是A股的正能量。
进而统计每日收益率的特征:

可以看到过去2000多个交易日中,沪深300单日涨幅最大为8.5个点(大奇迹日),单日跌幅最大为9.5个点(大盘跌停)。
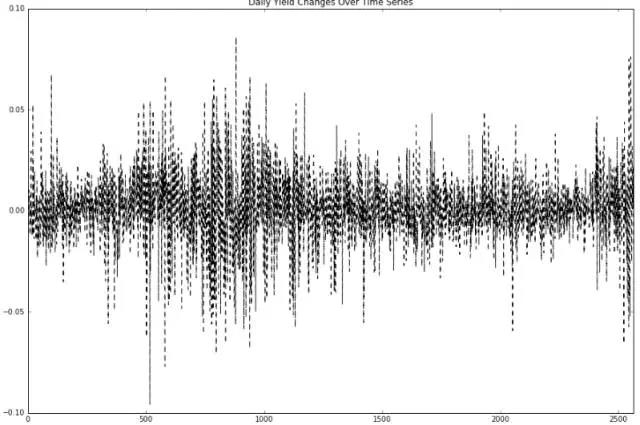
曲线以零为轴上下震荡,可以看到曲线有两大宽幅波动的区间,一个是07年的牛市,另外一个,就是我们现在这个渐行渐远的......似乎开始向0轴收敛的......虽然宽幅波动这意味着风险增强,但同时也诉说着交易市场的活跃,宽幅波动的开端暗示着牛市脚步的靠近,末端预示着牛儿的即将远行。
根据每日收益率的历史数据还可进一步绘制频率分布直方图并使用Kernel Density Estimate对数据进行拟合:

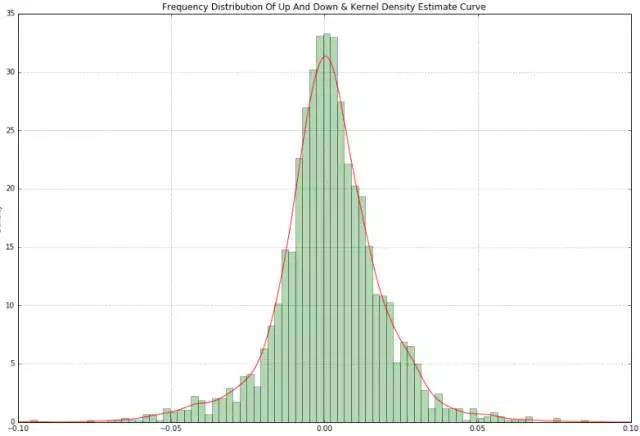
是一个标准正态分布,可是如果仔细瞅瞅你会发现,涨跌幅靠近零轴,涨强跌弱;而涨跌幅远离零轴的位置,跌强涨弱。也就是,微涨与微跌,微涨的情况更为显著,大涨与大跌,大跌分布更为明显。
上面介绍了机器学习的基本概念、scikit-learn的使用以及我们的数据——HS300指数数据的特征及分布,下面正式进入机器学习实战中。讨论的问题主要有三点:
机器学习估计器的选择,即我们使用何种算法进行我们的预测。
训练集样本数量的选择,即我们每次预测结果之前使用多少条训练集合的样本。
涨跌时间窗口的选择,即我们每个样本中的特征个数,我们训练集每个单元包含连续多少个交易日的涨跌。
机器学习估计器的选择
事实上,机器学习应用中一个很棘手的问题就是根据自己问题的实际找到一个合适的估计器,不同的估计器适合于不同类型的数据以及研究的对象,下面这张图给出了一个粗暴的引导:
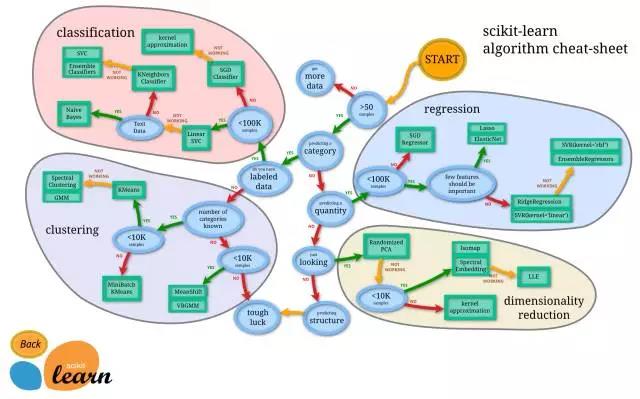
按图索骥,把目光聚焦到图的左上角,最终选择的结果为:EnsembleClassifiers、LinearSVC、KNeighborsClassifier.另外JMLR这儿有篇神奇的文章: Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?,文章测试了179种分类模型在UCI所有的121个数据上的性能,发现Random Forests 和SVM 性能最好。为此,我们的EnsembleClassifiers选择RandomForestClassifier,即我们最终想在RandomForestClassifier、LinearSVC、KNeighborsClassifier中比较比较。
将CSI300数据与另外15只随机选择的股票,保证相同的训练集样本数量与时间窗口的情况下,分别使用RandomForestClassifier、LinearSVC、KNeighborsClassifier这三种估计器进行学习,与此同时通过计算预测的胜率来比较各自的表现。
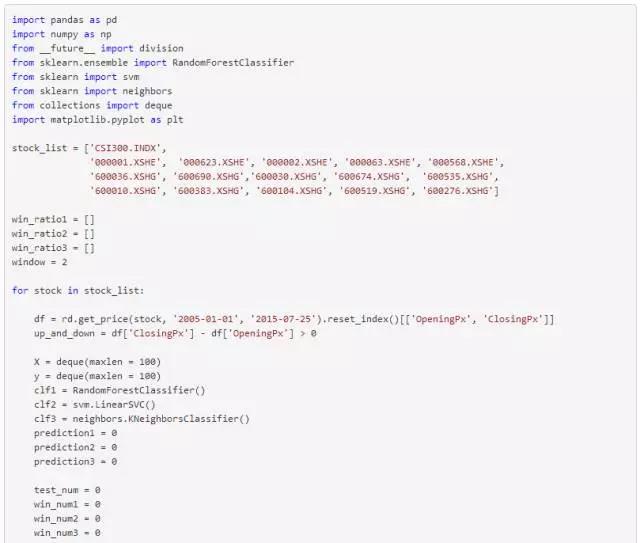
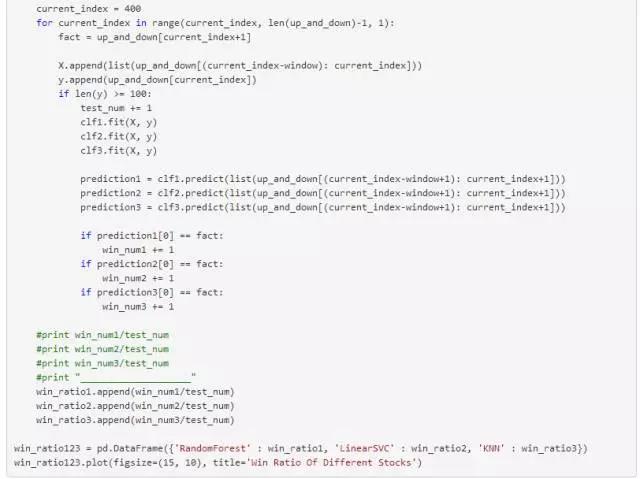
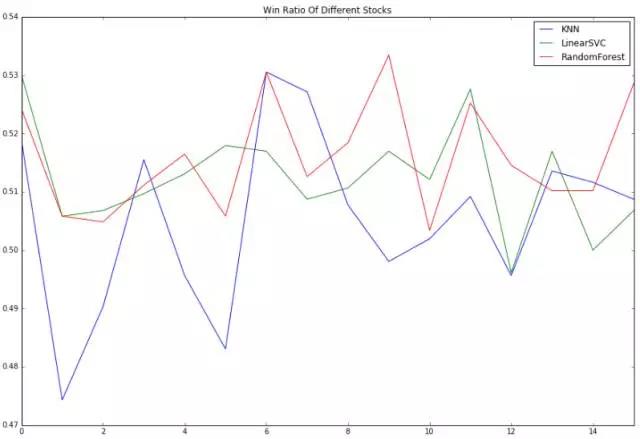
可以看出,KNeighborsClassifier表现明显逊于RandomForestClassifier、LinearSVC,它的波动较大且胜率与另外两者比也不理想。下面就使用RandomForestClassifier作为估计器做测试。
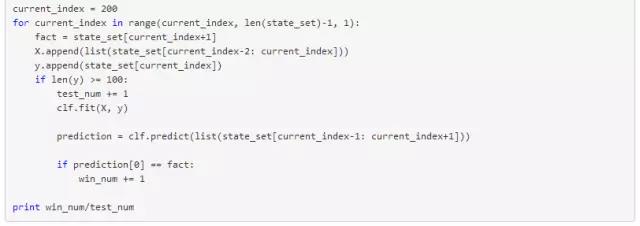
训练集样本数量一定程度制约了预测结果的准确性,理想情况下我当然希望每次做预测的样本数量越多越好,但是你知道理想很骨感的,训练集样本数量一方面受实际总的数据量限制,另外,计算的资源与时间也是制约的一个因素。我们最终要形成某种程度的妥协,即保证相当程度的预测效果下选择最小的训练集样本数量。于是我们计算样本数从1~300范围内的胜率,有了下面的代码:

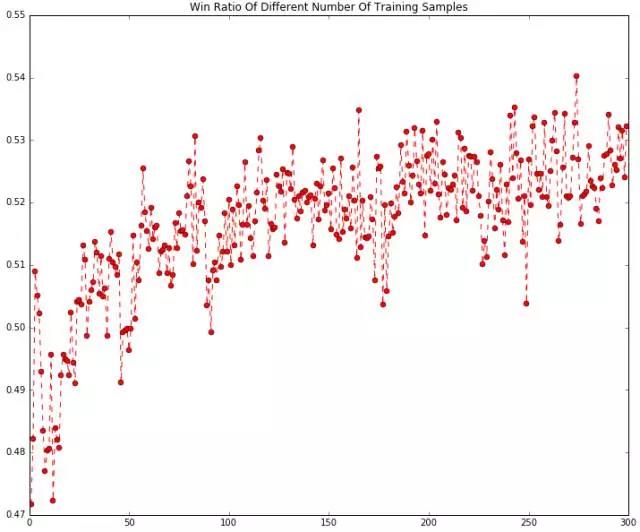 可以看出,控制其它条件不变的前提下,随着样本数量的增多,胜率逐步提高结果更为稳定并且最后维持在0.52~0.53左右波动,为了节约计算资源以及考虑到历史数据的总量,选择100个训练集样本数是较为合理的。
可以看出,控制其它条件不变的前提下,随着样本数量的增多,胜率逐步提高结果更为稳定并且最后维持在0.52~0.53左右波动,为了节约计算资源以及考虑到历史数据的总量,选择100个训练集样本数是较为合理的。

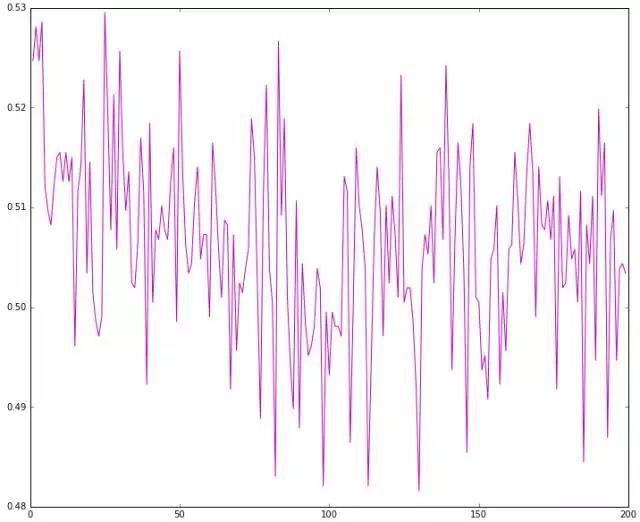
一个共同点是:每次曲线的开端都会存在倒塌式下滑,而后稳定震荡于0.5扔硬币的概率左右。也就是说,动量是存在的,只不过很小(结合前面两节的试验结果其期望处于0.53这个位置),且时间窗口很短,超出这个时间窗口,预测问题就转化为扔硬币问题。
总结
上文讨论了三个变量对预测结果的影响,结果并不满意,一方面daybar的数据量局限,一方面,总会有没注意到的细节且训练数据的维度较低。但是这个探索路途很有意思。后续还可以有很多可以扩展尝试的地方,比如把涨与跌分类为大涨大跌小涨小跌,比如再把交易量的数据加入训练集。
话说细分涨跌的代码分享如下:
 1人赞赏收藏
1人赞赏收藏




