几个月前人工智能围棋程序AlphaGo大胜李世石九段,人工智能再一次成为舆论的焦点,就连“深度学习”这样一个专业的概念也被广泛地传播开来。事实上,AlphaGo的主体框架是一个深度增强学习模型。用一个深度神经网络拟合增强学习模型中的Q值(对不起,我也不知道自己在说些什么),完美地将机器学习中的深度学习与增强学习这两个分支结合在一起。假设大家对机器学习以及最优化理论中的套路有一定了解的话,下面我们将进一步探索(深度)增强学习的原理,以及其在量化投资中的应用。
MDP与动态规划
Markov Decision Process(马尔克夫决策过程),是在Markov过程的基础上加入了行动(Action)与回报(Reward)的概念。首先,马尔克夫性就是说未来状态(的分布)只与当前状态有关,而与过去无关。而MDP中,在每种状态下可以采取若干种行动,当前状态与行动共同决定未来状态;并且在每次采取行动之后会获得一个相应的回报。具体而言,一个MDP由{S,A,P,R,γ}这五个部分组成:
S是所有状态(States)构成的集合;
A是所有行动(Actions)构成的集合;
P是转移矩阵,即给出从某一状态&行动之下转移到另一状态的概率;
R是回报(Reward),它是状态(s)与行动(a)的函数R(s,a);
γ是贴现率(搞金融的都懂==),它的存在是为了让我们在对未来所有Reward进行求和的时候不会碰到正无穷。
我们可以认为MDP是对真实世界一个很好的模拟。面对当前时刻的环境,我们可以大致估计自己各种行为对环境的影响,以及这种行为可能带来的即时与远期后果。在此基础上,我们选择一个可以最大化未来所有收益之和的行为,从而转移到下一个状态,并不断重复该过程。这样就可以自然地引入策略(Policy)与价值(Value)的概念。策略π(s)就是S到A的一个映射,即一套完整的相机而动的方案,事先约定在每种状态下采取什么策略。而价值V(s,π)是状态与策略的函数:从状态s开始,一直遵守策略π,那么未来一切收益贴现和的期望就是这个策略的价值。这样一来,所谓的最优策略π*(s)就是价值最大的策略。在此基础上,继续定义最优值V*(s)=V(s,π*),作为状态的函数,V*是执行最优策略时的价值。最优策略与最优值可以用动态规划求解(Bellman Equation,Value/Policy iteration),这里就不展开讨论了。
说了这么多MDP,我们可以暂时考虑下投资这件事情。也许有的同学已经在想:哇MDP的框架简直就是一个投资问题,股票的各种量价数据是当前的State,而投资者的买卖操作是Action,而收益(率)天然就是那个Reward。但问题是,我们并不知道状态之间是如何转移的,也就是说P是未知的。况且,在已知当前状态的条件下,我们也并不知道买卖操作给我们带来的收益是多少。这样就自然而然地引出了下一话题--增强学习。
Reinforcement Learning
增强学习RL就是让一个智能的agent通过不断地与环境交互,实现MDP的参数估计,并进一步找出可以最大化Reward期望贴现和的最优策略。参数估计主要是针对转移概率P与回报函数R,具体的方法是很简单粗暴的:根据历史观测求极大似然估计。以单只股票为例,将它每日的收盘价当作状态,那么从状态s1转移到状态s2概率的估计值就是简单地统计一下历史观测中前一天收盘价为s1时,有百分之多少的情况后一天的收盘价为s2。即:

同理,R(s,a)的估计值是在s状态与a行动下已经观测到的回报均值。值得一提的是,上面关于股票的例子中转移概率P与a是无关的,因为我们认为自己的action是不会影响股价的;而回报R是与我们的action高度相关的。但在其他一些增强学习的例子中,action可能仅影响P而不影响R,也可能同时影响P与R,这些情况都在RL的大框架之内。得到这些参数的估计值之后,就可以利用动态规划继续求解最优策略。
另一个重要的方法是Q-Learning,可以在不估计P和R的情况下,agent直接选择最优action。Q(s,a)是状态与行动的函数,其值定义为从状态s开始并使用a作为第一个行动时的最大回报: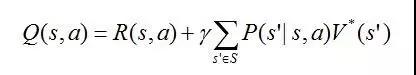
这个式子看起来有些复杂但思想很简单,右边第一项是当前的即时回报,第二项是期望最优值V*的贴现。显然,如果有了Q函数,我们可以在固定每种状态的条件下,找最大化Q值的action,这样也就找到了最优的状态到行动的策略。所以问题的关键就在于学习Q函数,也正因此这个方法叫做Q-Learning。考虑到Q与V*具有如下关系:
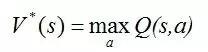
,那么可以得到关于Q的一个贝尔曼方程: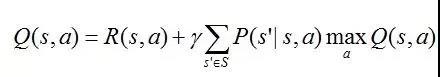
从而也可以迭代学习Q值直到收敛。
为了方便表述与理解,这里只以确定性MDP为例讨论,即已知当前状态与行动时,未来状态是唯一确定的(而不是一个概率分布)。首先建立一张Q值表并将所有的Q值初始化(如全部设为0),
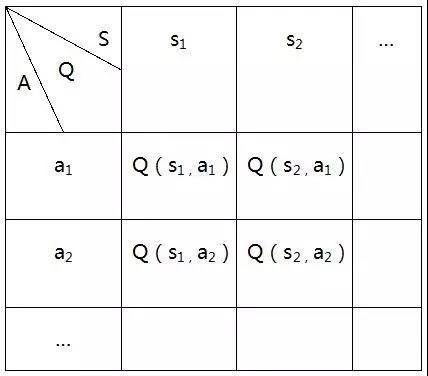
此时通过下式来迭代更新Q值: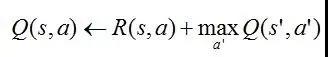
这里的s’就是由s与a唯一决定的下一状态。但以一个表来表示Q的成本是很大的,而且在遇到表以外的action或state时是无法给出Q值的(没有泛化能力)。于是,我们终于遇到了深度学习。
深度学习Q函数
上文提到Q表有一些弊端,索性直接拟合Q函数,而DeepMind正是使用了一个深度神经网络拟合Q函数,命名为DQN(Deep Q Net)。那么问题来了:神经网络作为一种监督学习,其训练是需要有标签(label)样本的,而这里Q值的标签是什么呢?答案就是之前迭代关系式中更新的Q值。他们的思路就是在更新Q的过程中同时训练DQN的权重W。(这块内容就不深究了,因为并没有搞懂)
量化中的应用
尽管RL与投资问题十分贴切,但要真正运用起来还是十分有难度的,以下总结一些问题以及我的思考。
1.状态设定:
目前深度增强学习效果比较好的场景有围棋、Atari游戏、直升机(机器人)等。这些场景下Reward往往只与State相关,例如围棋棋盘当前的状态唯一决定价值,不管棋手走了哪一步到达当前状态。但下一个状态与当前的行动是紧密相关的。相反在股票投资中,我们的买卖策略不大可能影响股票的状态,但却直接影响我们到下一期时的收益。从这个角度讲,投资更像是一个静态问题。有一个办法是将agent当前持有的各种股票数量当作状态的一部分,这样action就可以影响state之间的转换了,从而可以使用DQN中的各种细节处理与技巧。
另外,股票的大部分特征都是连续的变量,需要划分为离散的区间当作状态。模型对各种划分是否robust是一个需要验证的问题。当然这个问题是比较细节的。
2.特征选取:
深度学习有时也称无监督特征学习,正是因为它可以很好地从原始数据中提取有效的features,从而解决了以往机器学习中最大的难点--找feature。但在深度增强学习中,深度网络的作用与在其他地方是有区别的,并不能用来自动地选择、构造特征。所以在用深度增强学习对量化投资过程进行建模时,仍需依靠人工经验以及金融背景选择各种特征(量价关系、技术指标等)。
3.目标函数:
一般而言将每天在股市上的收益当作Reward就是最直接的选择,但这样并不能控制风险。所以也可以选择加入风险度量在目标函数当中,例如Sharp Ratio。但是由于风险是用方差来表示的,很难在每个时间点都给出度量值,因而需要一些处理技巧来改进。




