前言
在今天给大家介绍一个研究工具:pomegranate。它比其他软件包更加灵活,更快,直观易用,并且可以在多线程中并行完成。

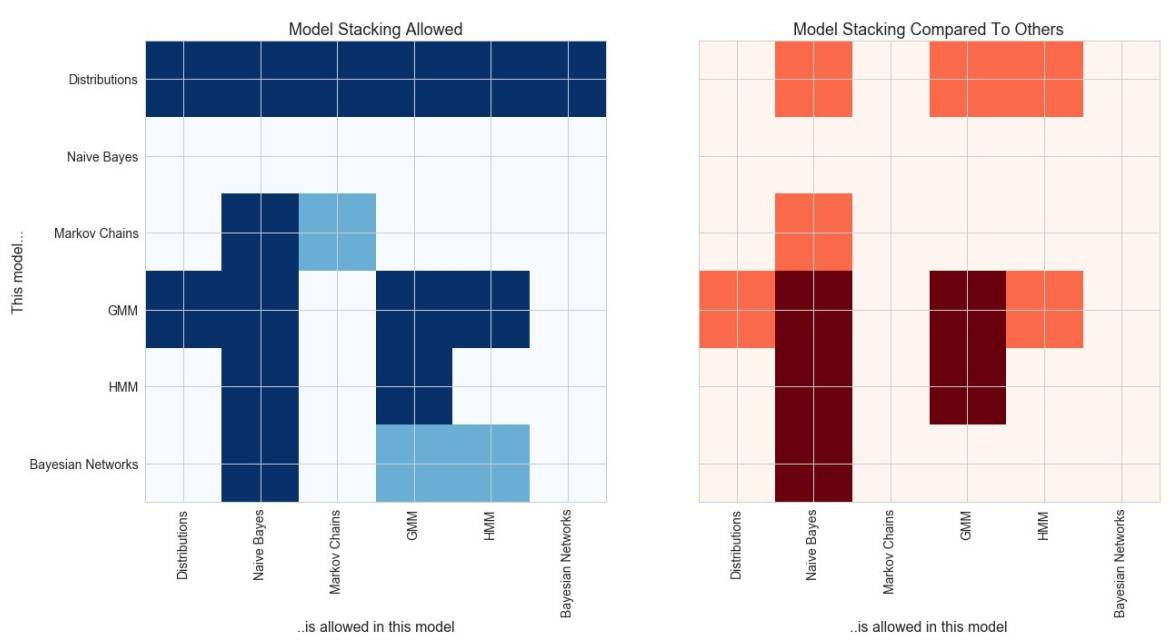
The API
主要模型介绍
一般混合模型
隐马尔可夫模型
贝叶斯网络
贝叶斯分类器
所有模型使用做多的方法
model.log_probability(X) / model.probability(X)
model.sample()
model.fit(X, weights, inertia)
model.summarize(X, weights)
model.from_summaries(inertia)
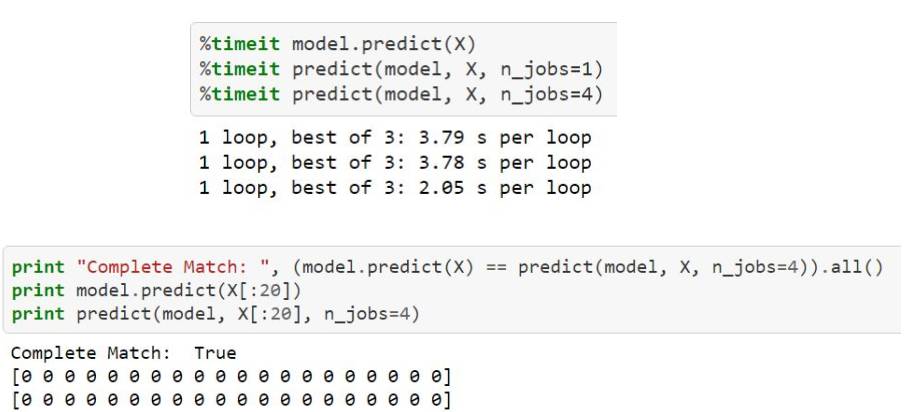
model.predict(X)
model.predict_proba(X)
model.predict_log_proba(X)
model.from_samples(X, weights)
支持很多分布函数
单变量分布
1. UniformDistribution
2. BernoulliDistribution
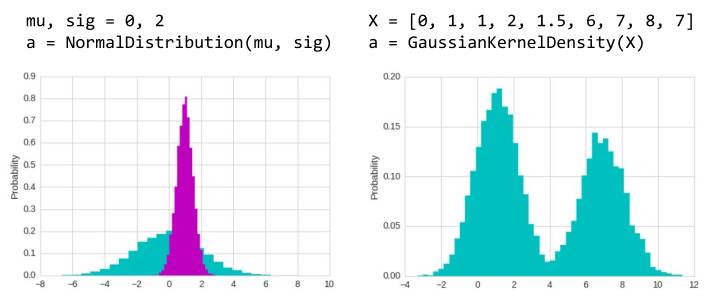
3. NormalDistribution
4. LogNormalDistribution
5. ExponentialDistribution
6. BetaDistribution
7. GammaDistribution
8. DiscreteDistribution
9. PoissonDistribution
内核密度
1. GaussianKernelDensity
2. UniformKernelDensity
3. TriangleKernelDensity
多变量分布
1. IndependentComponentsDistribution
2. MultivariateGaussianDistribution
3. DirichletDistribution
4. ConditionalProbabilityTable
5. JointProbabilityTable
模型可以从已知值中创建
模型也可以从数据直接学习
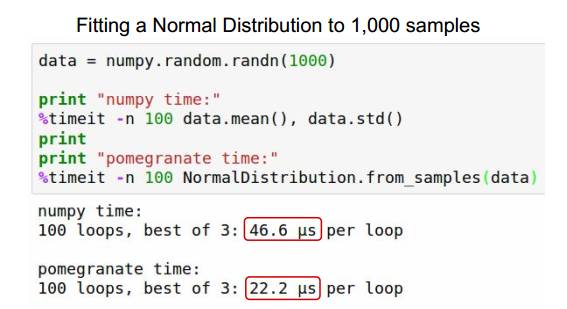
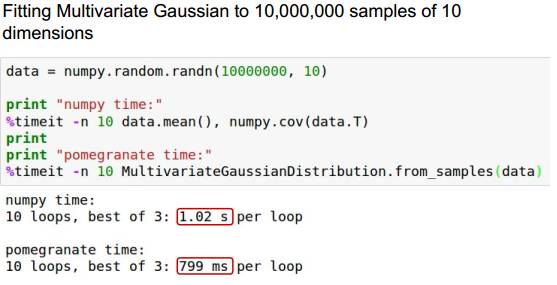
pomegranate 比 numpy 快
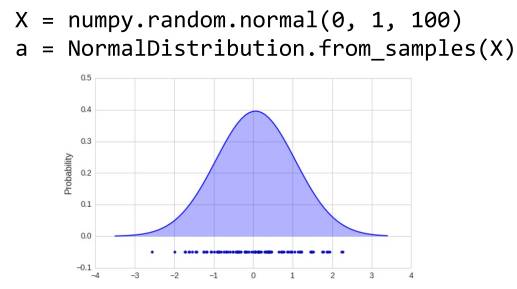
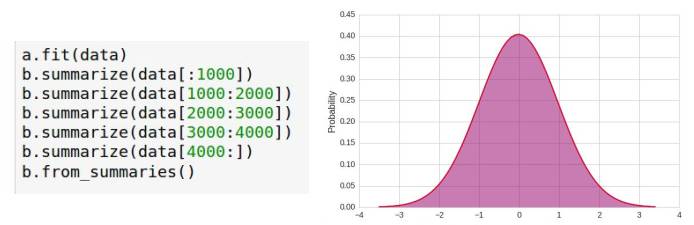
只需要一次数据集(适用于所有模型)。以下是正态分布统计示例:
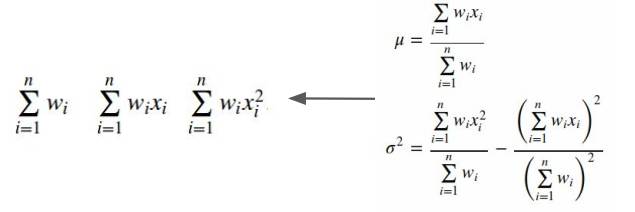
支持核心学习
由于使用了足够多的统计数据,因此可以支持外核/在线学习。
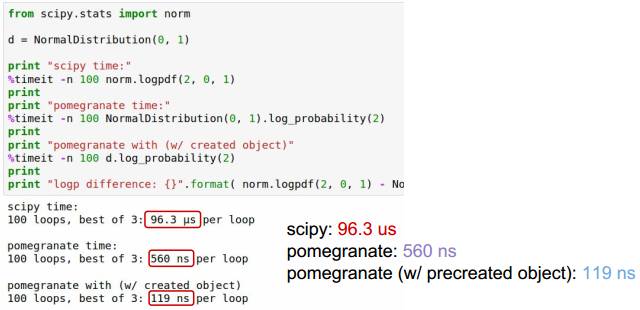
pomegranate 比 scipy 快
The API
主要模型介绍
一般混合模型
隐马尔可夫模型
贝叶斯网络
贝叶斯分类器
通用混合模型(GMM)可以对多组分布进行建模
GMM使用期望最大化(EM)来拟合
1、使用kmeans ++或kmeans ||初始化集群
2、对于等于后P(M | D)(E步)的所有点分配权重
3、使用加权点更新分布(M步)
4、重复2和3,直到收敛
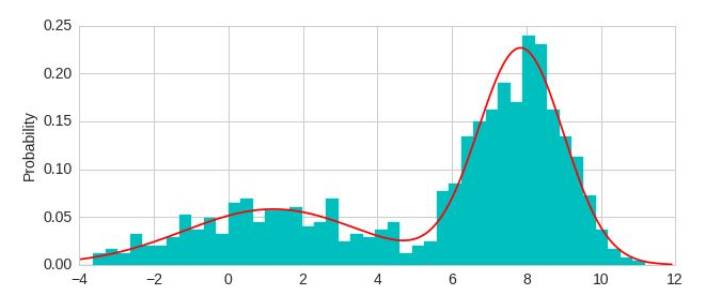
model = GeneralMixtureModel.from_samples(NormalDistribution, 2, X)
GMM不限于高斯分布
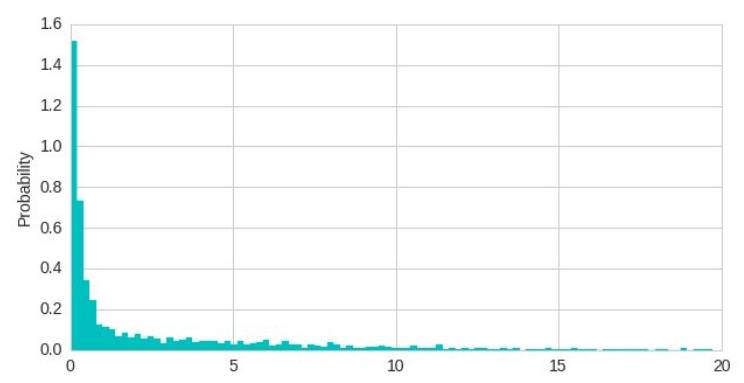
单个指数分布不能很好的数据进行建模
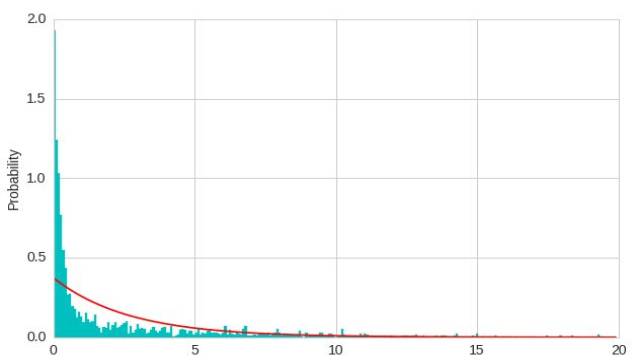
model = ExponentialDistribution.from_samples(X)
两个指数混合使数据更好的模拟
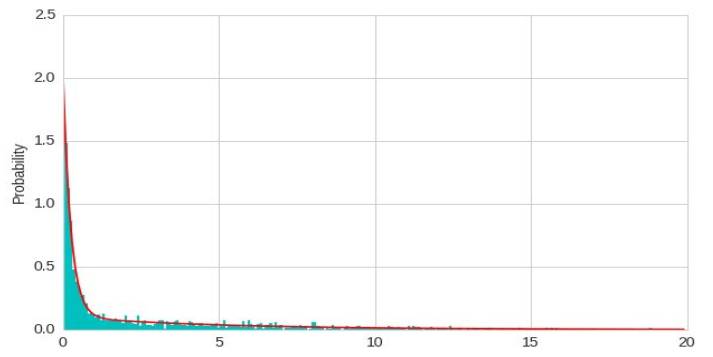
model = GeneralMixtureModel.from_samples(ExponentialDistribution, 2, X)
Heterogeneous mixtures are natively supported
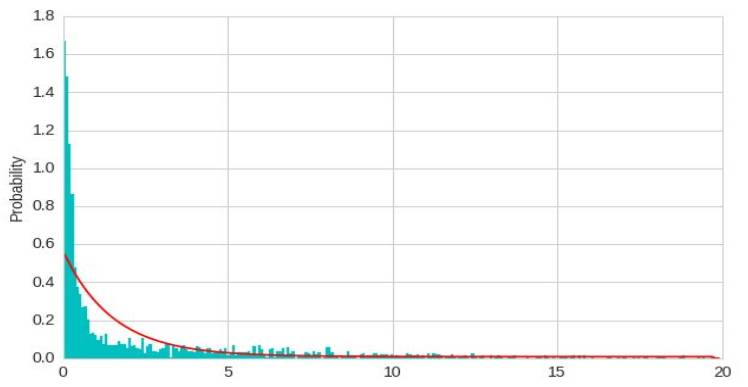
model = GeneralMixtureModel.from_samples([ExponentialDistribution, UniformDistribution], 2, X)
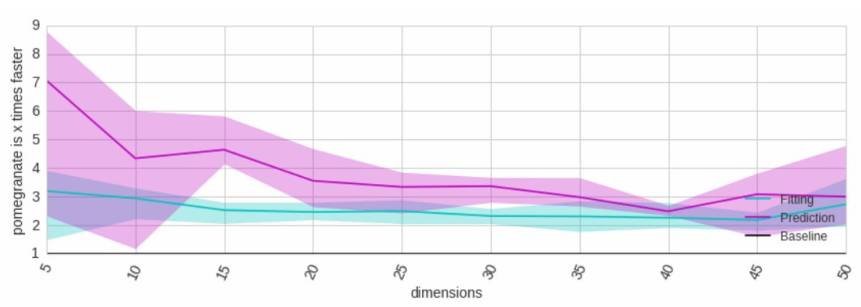
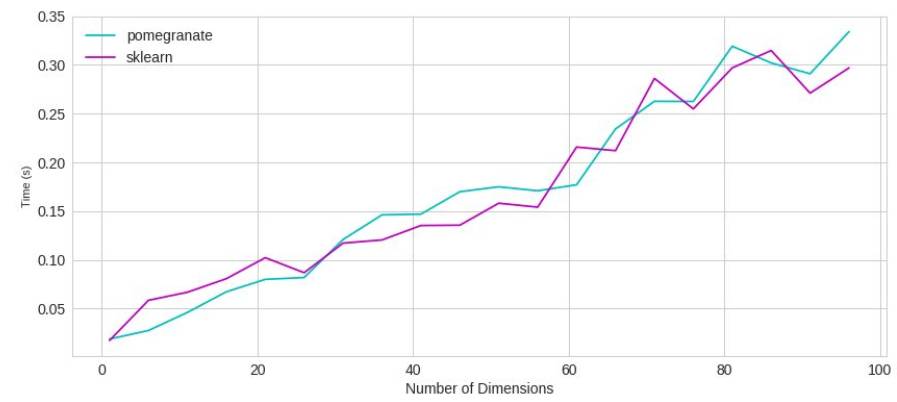
一般混合模型比sklearn快
The API
主要模型介绍
一般混合模型
隐马尔可夫模型
贝叶斯网络
贝叶斯分类器
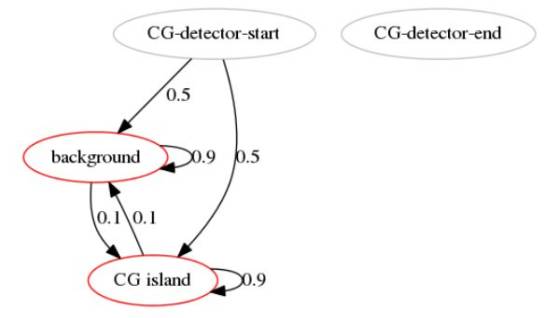
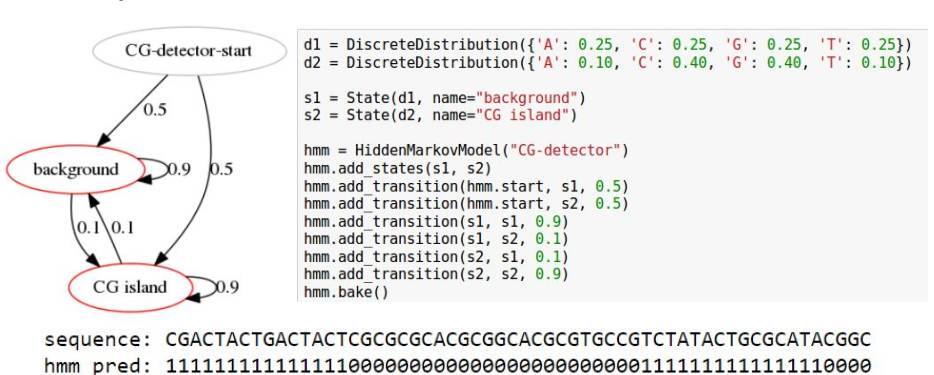
CG enrichment detection HMM
GACTACGACTCGCGCTCGCGCGACGCGCTCGACATCATCGACACGACACTC


GMM-HMM

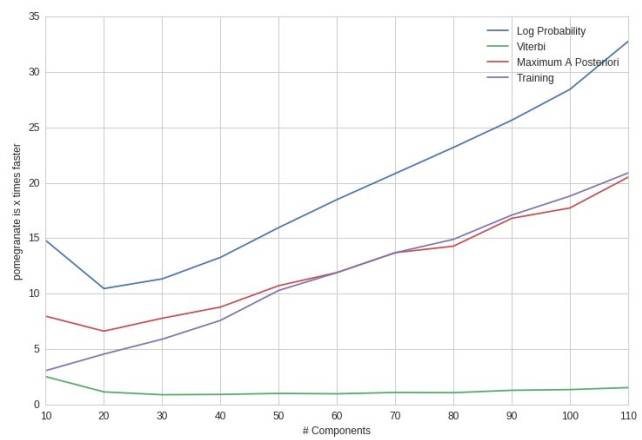
HMM比hmmlearn快
The API
主要模型介绍
一般混合模型
隐马尔可夫模型
贝叶斯网络
贝叶斯分类器
P(M|D)= P(D|M)P(M) / P(D)
Posterior = Likelihood * Prior / Normalization
基于数据建立一个简单的分类器
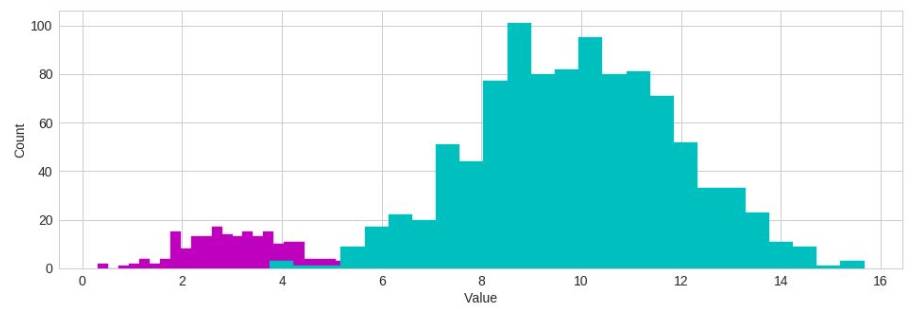
似然函数本身忽略了类不平衡
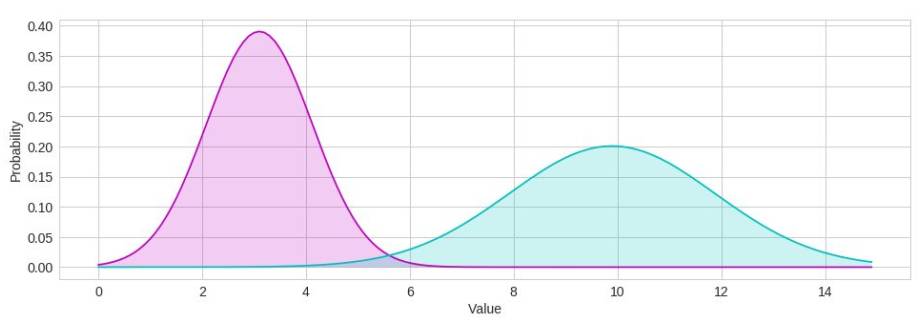
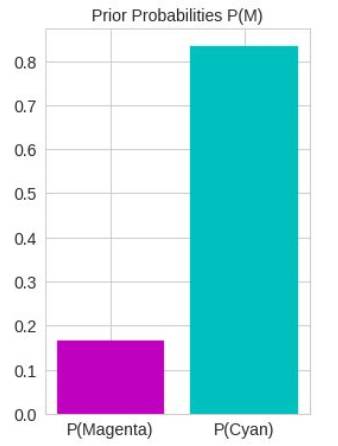
先验概率可以模拟分类不平衡
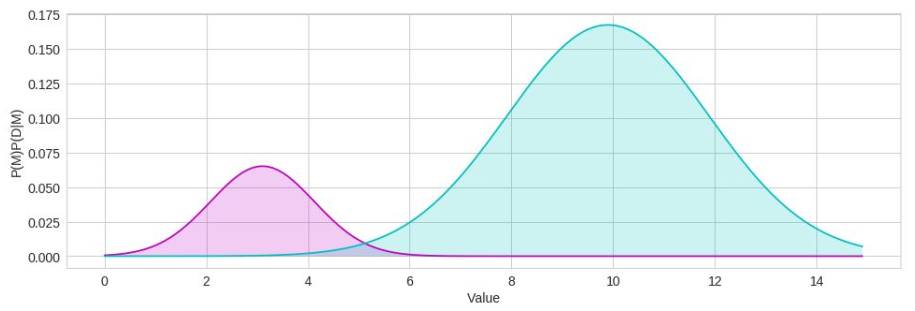
后验模型更真实地对原始数据进行建模
后者的比例是一个很好的分类器
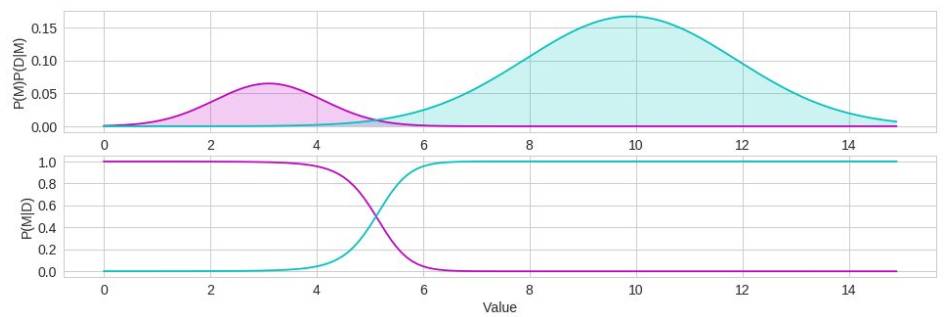
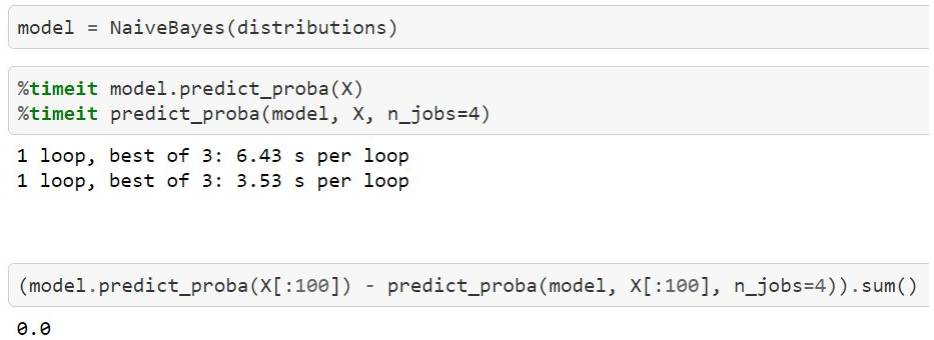
model = NaiveBayes.from_samples(NormalDistribution, X, y)
posteriors = model.predict_proba(idxs)
P(M|D)= ∏P(D|M) P(M) / P(D)
Posterior = Likelihood * Prior / Normalization
Naive Bayes does not need to be homogenous
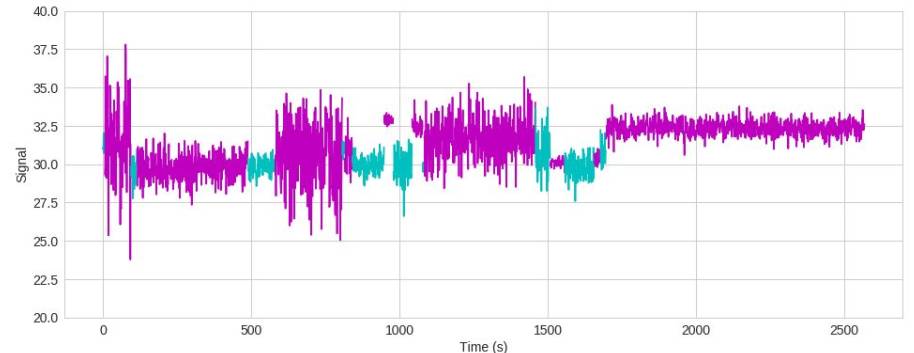
不同的功能属于不同的分布
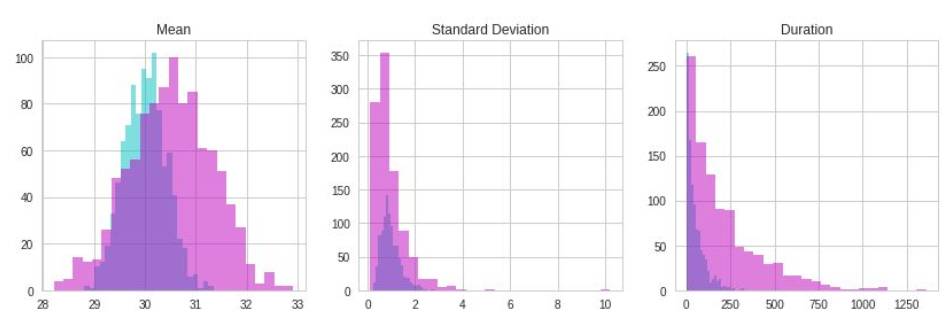

Gaussian Naive Bayes: 0.798
sklearn Gaussian Naive Bayes: 0.798
Heterogeneous Naive Bayes: 0.844
与sklearn一样快
P(M|D)= P(D|M) P(M) / P(D)
Posterior = Likelihood * Prior / Normalization
mc_a = MarkovChain.from_samples(X[y == 0])
mc_b = MarkovChain.from_samples(X[y == 1])
model_b = BayesClassifier([mc_a, mc_b], weights=numpy.array([1-y.mean(), y.mean()]))
hmm_a = HiddenMarkovModel…
hmm_b = HiddenMarkovModel...
model_b = BayesClassifier([hmm_a, hmm_b], weights=numpy.array([1-y.mean(), y.mean()]))
bn_a = BayesianNetwork.from_samples(X[y == 0])
bn_b = BayesianNetwork.from_samples(X[y == 1])
model_b = BayesClassifier([bn_a, bn_b], weights=numpy.array([1-y.mean(), y.mean()]))
并行