深度学习的具体模型及方法
1、自动编码器(AutoEncoder )
2、稀疏自动编码器(Sparse AutoEncoder)
3、限制波尔兹曼机(Restricted Boltzmann Machine)
4、深信度网络(Deep Belief Networks)
5、卷积神经网络(Convolutional Neural Networks)
自动编码器( AutoEncoder )
将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,再加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),就有理由相信这个code是靠谱的。所以,通过调整encoder和decoder的参数,使得重构误差最小,就得到了输入input信号的第一个表示了,也就是编码code了。
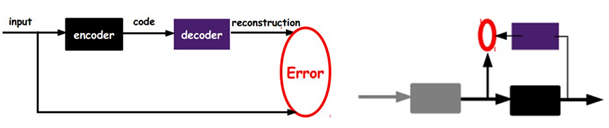
因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
稀疏自动编码器(Sparse AutoEncoder)
在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0),就可
以得到SparseAutoEncoder法。
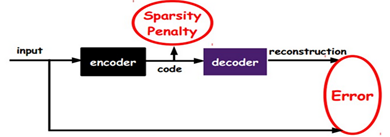
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效。
限制波尔兹曼机(RBM)
定义:假设有一个二部图,同层节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值(0,1)变量节点,同时假设全概率分布p(v,h)满足Boltzmann分布,称这个模型是RBM。
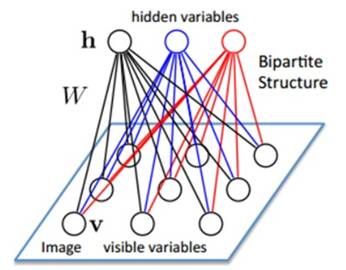
训练模型:
联合组态(jointconfiguration)的能量可以表示为:
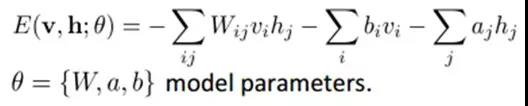
而某个组态的联合概率分布可以通过Boltzmann分布(和这个组态的能量)来确定:

给定隐层h的基础上,可视层的概率确定:
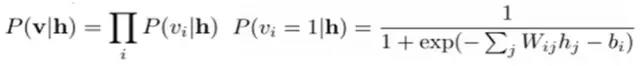
(可视层节点之间是条件**的)
给定可视层v的基础上,隐层的概率确定:
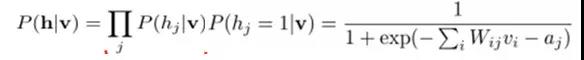
给定一个满足**同分布的样本集:D={v(1), v(2),…, v(N)},我们需要学习参数θ={W,a,b}。
最大似然估计:
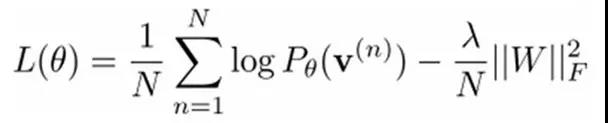
对最大对数似然函数求导,就可以得到L最大时对应的参数W了。
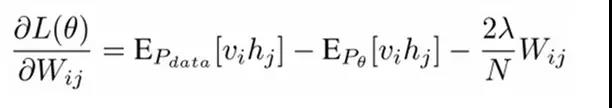
深信度网络(DBN)
DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是P(Label|Observation)。
对于在深度神经网络应用传统的BP算法的时候,DBNs遇到了以下问题:
(1)需要为训练提供一个有标签的样本集;
(2)学习过程较慢;
(3)不适当的参数选择会导致学习收敛于局部最优解。
DBNs由多个限制玻尔兹曼机(RBM)层组成,一个典型的神经网络类型如下图所示。
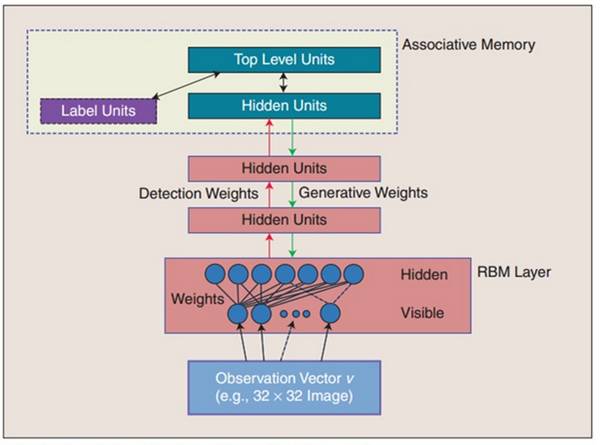
在最高两层,权值被连接到一起,更低层的输出将会提供一个参考的线索或者关联给顶层,顶层就会将其联系到它的记忆内容。
卷积神经网络(Convolutional Neural Networks)
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个**神经元组成。CNNs是第一个真正成功训练多层网络结构的学习算法。
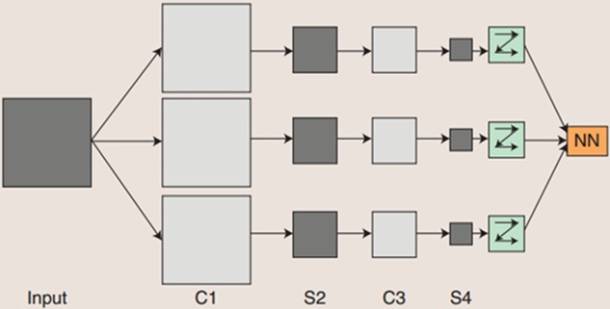
概念示范:输入图像通过与m个可训练的滤波器和可加偏置进行卷积,在C1层产生m个特征映射图,然后特征映射图中每组的n个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到m个S2层的特征映射图。这些映射图再经过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
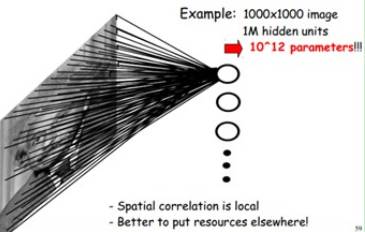
关于参数减少与权值共享:
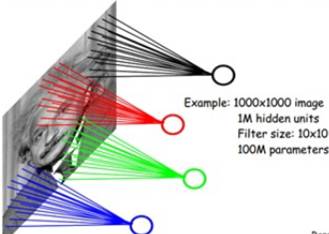
减少参数的方法:
每个神经元无需对全局图像做感受,只需感受局部区域(FeatureMap),在高层会将这些感受不同局部的神经元综合起来获得全局信息。
每个神经元参数设为相同,即权值共享,也即每个神经元用同一个卷积核去卷积图像。
隐层神经元数量的确定:
神经元数量与输入图像大小、滤波器大小和滤波器的滑动步长有关。
例如,输入图像是1000x1000像素,滤波器大小是10x10,假设滤波器间没有重叠,即步长为10,这样隐层的神经元个数就是(1000x1000)/ (10x10)=10000个。
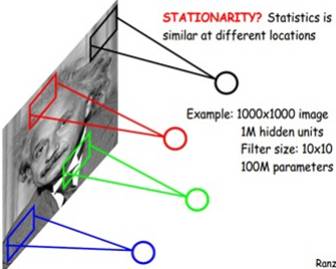
总之,卷积网络的核心思想是将:局部感受野、权值共享以及时间或空间子采样这三种结构思想结合起来获得某种程度的位移、尺度、形变不变性。
CNN的优点:
1、避免了显式的特征抽取,而隐式地从训练数据中进行学习;
2、同一特征映射面上的神经元权值相同,从而网络可以并行学习,降低了网络的复杂性;
3、采用时间或者空间的子采样结构,可以获得某种程度的位移、尺度、形变鲁棒性;
4、输入信息和网络拓扑结构能很好的吻合,在语音识别和图像处理方面有着独特优势。




