一.文本数据挖掘
金融市场中,投资者利用的数据主要集中于数字化的金融数据,如:历史价格、交易量、各种宏观指标等等,并在此基础上制定交易策略。然而,这并未包含另一类主要的金融数据——文本数据。文本数据存在于金融市场的方方面面,比如**机构公布的宏观信息,上市公司发布的公司公告,或者新闻媒体对于金融市场的新闻报道等等,金融文本数据是反映金融市场情况的一类重要数据,基于此的投资策略也逐渐进入投资者的视野。
金融文本信息按照内容分类可以分为:宏观经济信息、行业信息、公司信息、技术面信息、投资者情绪信息;按照信息来源可以分为:**机构信息、公司公告信息、机构信息、新闻信息、社交媒体信息等。以上的文本信息都可以作为构建文本数据挖掘策略的信息来源。
然而,直接获得的文本数据是非结构化数据,无法直接构建交易策略。构建文本挖掘策略的一个重要过程是对于文本的处理和分类。首先,要对获取的文本信息进行清洗,提取有效信息;然后,对文本信息进行分类。文本挖掘策略需要提取的信息类型大致可以分为两类:热度和情绪。涉及的主要分类算法包括:贝叶斯分类器,字眼统计分类器,向量距离分类器,判别分类器,文本情绪打分等。主要逻辑流程如图1:

图1 文本挖掘策略逻辑
随着互联网大数据时代的来临,金融市场中对于文本数据挖掘策略也越来越重视。光大搭建了中文云文本挖掘系统,并基于此构建了光大关键词指数、光大情感指数、光大关键词网络图、光大关注度因子四个搜索引擎;中证指数公司、百度和广发基金合作基于大数据搜索因子构建出一套稳健的策略指数选样模型;南方基金和新浪合作构建出基于新浪财经数据的文本挖掘策略指数。文本数据挖掘策略将越来越受到投资者的重视。
二.文本挖掘策略
1. 行业高频词
新闻的热度水平是市场对于投资对象关注度的直接反映,而资产价格是由市场买卖力量决定。显然,新闻的热度与相应投资标的收益率存在正相关关系。
对于投资标的的热度,其相关的特有的高频词词汇数量是一个很好的反映。通过搜索当天所有的新闻网站,如:《中国广播网》《中国新闻网》《新浪财经》《中国财经新闻报》等等,统计不同资产标的的高频词,并且统计其词汇数量总和,标记为当天该资产标的的热度。
为使统计得到的高频词具有区别性和代表性,可以将资产标的按照行业分类,统计当天行业高频词词汇总和,进而对下一时刻的行业指数收益率做出预测。
2. 行业高频词因子有效性检验
得到行业高频词词汇数量总和后,可以将其看作收益率的一个因子,利用单因子有效性检验方法对其进行检验,包括:IC值,排序IC值,IC的均值、方差、p检验值,分组后top组、bottom组的收益率、胜率、IR值,IC值的IR值。
(1) IC值频数直方图
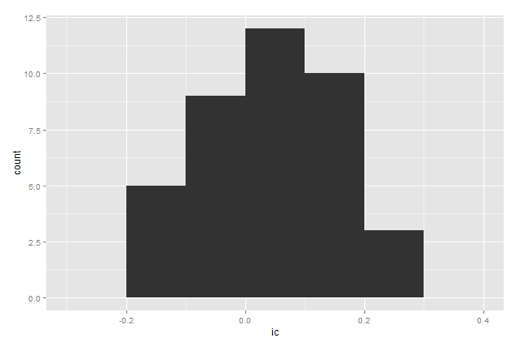
图2 IC频数直方图
(2) 排序IC频数直方图
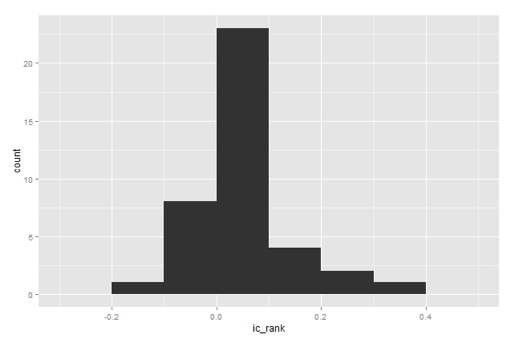
图3 排序IC频数直方图
(3) 分组收益率
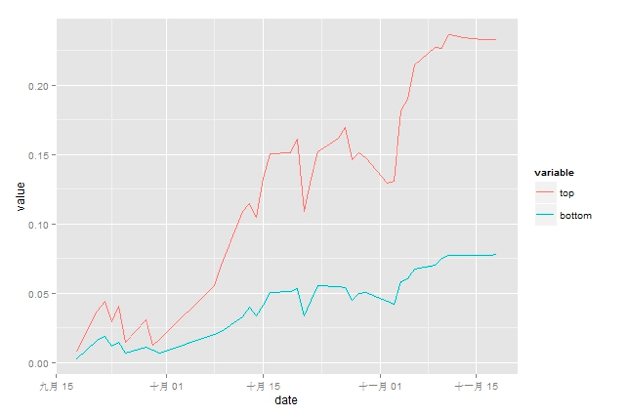
图4 分组收益率
(4) 有效性检验统计值
统计量
IC均值
排序IC均值
IC方差
排序IC方差
IC p值
结果
0.034
0.055
0.113
0.091
0.40
统计量
Top组收益率
Bottom组收益率
Top组IR值
Bottom组IR值
IC IR值
结果
0.006
0.002
0.311
0.286
0.302
通过对于行业高频词因子有效性检验,可以得出结论:对于行业指数收益率,行业高频词热度是一个显著有效的因子。
3. 支持向量机预测模型
支持向量机是一种用于模式识别、分类预测的机器学习方法。依据学习数据,一个支持向量机会构造一个超平面,基于VC维理论和结构风险最小原理折中模型的复杂性和学习能力构建模型,进而可以将新的实例进行非概率二元线性分类。支持向量机具有能够全局优化,较好的泛化性能和训练效率高等有点。
金融市场中,资产价格具有上涨和下跌两类,并且与因子具有非线性关系,因此可以利用支持向量机构建模型对资产价格的变动进行预测。经有效性检验,行业高频词热度是行业指数收益率的一个有效因子,为增加预测的准确率,常用的方法是增加学习数据的维度。根据市场有效性理论,资产价格包含了市场的一切信息。另外,资产价格收益率的时间序列是具有马尔科夫性质的随机过程,即当前状态只与上一时刻状态有关,而与历史状态无关。因此,对于支持向量机预测模型,可以考虑将前一时刻的收益率纳入输入参数。
以t时刻的行业高频词热度和行业指数收益率作为输入参数构建支持向量机模型,对t+1时刻行业指数收益率进行预测。首先将样本数据作为学习数据训练支持向量机,即寻找一个超平面。由于收益率的变动具有非线性性质,在模型中选用径向核函数。支持向量机预测模型的本质是根据输入参数和对应的分类数据训练模型,找到最优的超平面,进而将新的输入参数进行分类以达到预测的目的。
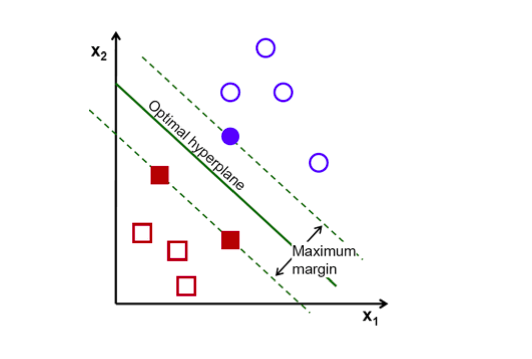
图5 支持向量机示意图
4. 文本挖掘策略
基于支持向量机预测模型的预测结果,可以构建一个以行业指数为交易标的的文本挖掘模型:根据t时刻支持向量机预测模型的预测结果,在t+1时刻等权重买入预测上涨的行业指数。
三.回测结果
选取SAM二级行业指数作为策略对象,回测时间:2015年9月18日-2015年11月18日。
1. 支持向量机预测模型预测准确率
回测窗口包含39天104个行业的数据,选取前10天1040个数据作为模型的训练数据,然后统计模型每天的准确率。整个回测区间中平均准确率为57.7%,样本内模型预测准确率为58.5%,样本外模型预测准确率为57.3%。
(1)预测准确率频数直方图
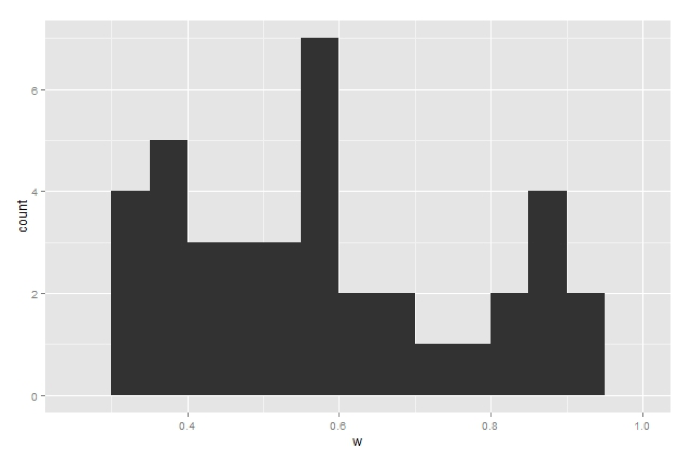
图5 模型预测准确率
(2)样本内预测准确率
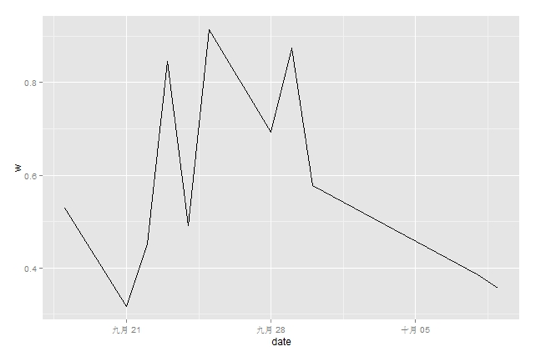
图6 样本内预测准确率
(3)样本外预测准确率
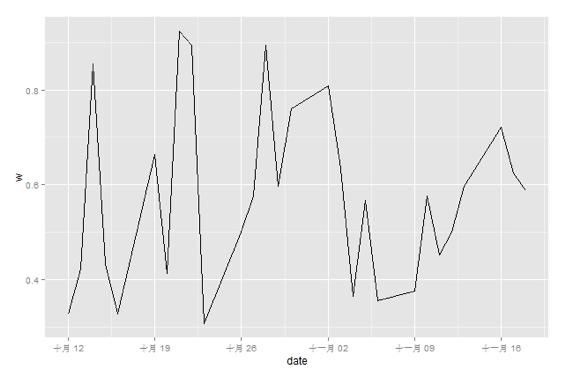
图7 样本外预测准确率
2. 策略净值曲线
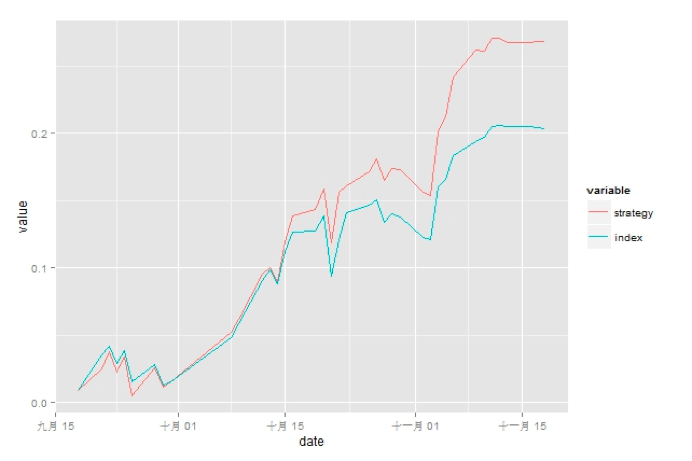
图8 策略净值曲线
在回测区间按照策略进行回测,并利用平均行业指数收益率作为对比,其净值曲线如图8。可以看出,策略可以获得稳定的超额收益,其战胜指数的概率为69.2%。
四.结论和讨论
在互联网大数据时代,文本挖掘策略得到投资者的日益关注。本文基于行业高频词热度,利用支持向量机对行业指数收益率进行预测,并根据预测结果构建文本挖掘策略。在回测期间,该预测模型具有57.7%的准确率,样本内和样本外的预测准确率分别为58.5%和57.3%;基于预测结果的文本挖掘策略可以获得明显的超额收益。但是由于文本历史数据较少,回测数据远远不够,因此目前的回测结果还不是很有说服力。




