思考了很久从哪里讲量化交易,决定还是从人生中的第一本量化书籍开始,记录自己的读书过程,把书越读越薄!第一次读这本书的时候,已经是5年前了,作为量化实验室的新丁,被要求阅读的就是这本书,并且实现书中的交易策略,了解到了很多很多基础的概念,书中的代码多数已经不能用,所用的语言也是matlab,这次写系列读书笔记,我将使用PYTHON语言(现在用的比较多),这里并不是说matlab过时了,我到现在依旧认为在矩阵处理及可视化上matlab仍然具有绝对优势。周围很多策略开发者仍然在使用matlab!
量化交易是什么?
量化交易也被称作算法交易,各类资产的买入卖出严格按照计算机算法,交易员自己设计的算法和程序。很多书籍提到的技术分析,如果技术分析的指标可以被量化,那么也算是量化交易的一种。总的来说如果你可以把各种信息转化为计算机能够识别的信息来进行交易,就可以被看作是量化交易。
谁可以成为量化交易员?
实际上大多数机构的交易员都是毕业于物理、数学、工程或者计算机科学专业,当然科学技能的训练是这些人在分析和交易复杂的衍生品时所必须的技能,但是本书并不会涉及复杂的交易标的,有一种交易策略是统计套利,交易标的是简单的股票、期货以及外汇,入门相对简单,只要你上过一些高等数学、统计学和会变成,你就可以掌握统计套利策略(简单的!!!)
网络上有成千上网的交易策略,主要有以下一些渠道:
但是自己需要对公开的策略有一些辨识能力,比如说许多论文中的策略都是针对小市值股票的,流动性并不好,真实的交易中利润肯定不如回测表现好(这里涉及到交易的流动性成本问题,在后面的专栏中会详细讲讲),还有网上PO出来的策略表现可能并没有经过严格的回测检验条件,比如并没有考虑到交易成本之类的。EPCHAN还是经常从博客和论坛中发现简单且能盈利的策略
下面这个问题比较重要,人要选择适合自己的策略:
1、工作时间:如果你是业余交易者,每天交易的时间有限,那么可能你会更倾向于隔夜交易(持有超过1天,一般对今天买入并卖出的交易称为:日内交易)
2、编程技能:如果你的编程水平有限,那么就不要选择对编程水平要求较高的高频交易(比如说每TICK交易几十上百次)
3、交易本金:如果本金较少,那么就需要考虑一些把杠杆用到极限,就是交易标的期货、期权、外汇,这些交易标的都是可以加杠杆的。
4、盈利目标:这里有一个大众误区,就是如果你追求长期的回报,那么你只需要买入并持有。优秀的策略应该是找到一个夏普率最高的策略(实践中其实夏普率并不是唯一的参考指标,不过也是非常好的一个参考指标,需要大家在大量的策略检验中去寻找平衡点)。
如果你在网上找到了自己认为适合的策略,并且别人PO出来的策略表现非常优越,但是不要急于的将你的时间花在测试这些策略上面,你可以从以下几点去快速的检验策略(很多量化交易机构都会使用人海战术,就是不放过一个指标及策略,全部进行回测,反正现在计算能力已经不是问题):
(1)盈利水平和基准进行对比情况,还有盈利的持续性
比如一个股票的策略盈利水平就需要和股指的表现进行对比。这个时候就引入前面已经谈到的夏普比指标。
SHARPE RATIO = average of excess Returns / standard deviation of excess Returns
夏普比 = 超额收益的平均值/超额收益的标准差
其中 excess Returns = Portfolio Returns - Benchmark Returns
超额收益 = 策略收益 - 基准收益
注:如果你的策略一年之中只交易很少的几次,夏普率就不会太高,如果你的策略有很深的回撤(drawdown,见下图),并且持续时间长,夏普比也不会太高。
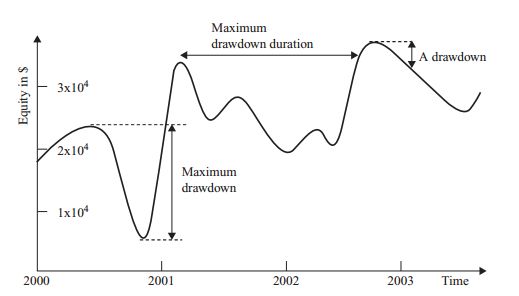
任何策略如果夏普率低于1,这就是一个不太合适的策略,如果一个策略基本上每个月都盈利的话, 夏普率应该是大于2,如果一个策略基本上每日都盈利话,那么夏普率会通常大于3。
(2)交易成本对策略表现的影响
每一次买卖证券,都会产生交易成本。交易成本对策略的影响是非常大的(感觉99.99%的策略都是败给手续费的,开赌场的最赚钱)。交易成本不只是交易佣金(比如印花税),还有流动性成本(非常重要!),如果你想买入或者卖出证券,你都需要付出最优卖家和最优买价的价差。如果你使用限价单(到一定心理价位才成交),那么你将可能会失去交易机会。还有如果你的买入卖出量够大的话,你的行为就会影响市场的价格,就是需求和供给严重不平衡,这个时候可能就会出现流动性缺乏,付出巨大的交易成本,举个栗子,如果现在买卖苹果,第一个卖苹果的人卖1元,第二个卖苹果的人卖100元,你需要买入两个苹果,你下了两个市价单(按照现在市场能成交的价格成交的订单类型),那么你就会花费101元买两个苹果!。
另外“滑点”对策略的表现影响也很大,滑点就是你看到苹果卖1元,你发了个订单去买,但是1元的苹果已经被别人买走了,别人的交易速度比你快,于是你的订单一到交易所就成交了100元的苹果,你比预期的成交价高了99块,这99块就是滑点成本,一般来讲回测策略至少需要设置2跳(比如说苹果只能按照1元、2元...每一块报价,那么1元=1跳)。
(3)数据是否存在生存者偏差
我们股票市场中有不少很差的企业都退市了,比如说A企业在2015年退市了,你在回测过去5年的数据时,很可能只选择了还存活在现在的企业,这些很差的如A企业数据并不包含,那么你使用的数据就存在了生存者偏差,自动的排除了已经被市场淘汰的企业。
(4)策略每年的表现
regime shifts就是市场结构变化,会使你的策略失效,市场结构变化多是由交易所监管导致,比如说在15年我国对股指期货提高交易手续费、限制交易手数,一下子把市场的流动性都打下来了,这个品种接近死掉。
(5)策略过拟合
如果交易策略有100个交易参数,回测的结果也非常的完美,那么你的策略很可能已经过度拟合,就是你已经知道了过去市场的表现,你按照特定的数据选择了一条最优路线,但是正如你不可能踏入同一条河流,你的策略的普适性是非常差的,基本上会100%亏掉(我一般交易策略不会高于5个参数)。避免过拟合也非常简单,用一些新的数据来验证策略参数即可。
和传统的投资管理程序不同,量化交易流程是先需要把交易策略运用于历史数据、检验交易策略历史表现如何。尽管你找到了一个策略,并且有完成详细的历史表现,但是你仍然需要亲自的去检验回测策略。这样做有几个好处,一是你可以完全的理解别人的策略思想,而是你可以接触到不同类型的策略,这些策略都可以被重新定义或者升级为更**的策略。
在这个章节中,作者介绍了一些用来回测的工具平台和数据(我也写一下自己的真实感受):
回测平台:
1、excel:这个环节就略过了,作为大量交易策略来讲,EXCEL实在是容易卡主,我们跳过!
2、matlab:刚接触量化交易时,用的就是matlab,矩阵计算能力相当好,不妨作为入门级工具,也可以深入的掌握matlab,作为一个偏交易策略的trader来讲,这个工具也就OK了。
其余书中提到的平台TRADERSTATION等都不适合国内交易员用,另外我再补充两个:
1、C++:这个是作为量化交易团队中作底层系统支持的程序员们必须要掌握的语言,C++计算速度非常快,建议也可以学习一下,当你的策略在matlab中有了初步模型时,可以使用C++来做策略参数迭代优化等。
2、PYTHON:这个是最近新崛起的工具,其优势在于有很多开源库,基本属于人人都可入门的语言。
历史数据:
作者列举的都是国外的数据源,也并不实用,下面我谈一下一般量化交易的数据源:
1、期货数据方面:直接CTP从交易所收取行情,并储存在本地,这个后期我会写文章
2、股票数据方面:我一般都会直接从公司版的wind里获取数据,如果没有的话,同花顺,以及雅虎的股票数据都是考虑的。
做交易时往往涉及到不同的交易品种,一般会按品种区分文件夹,如下图(这里是下载了所有的主力合约,就是每天交易量最大的合约):
每一个文件夹按照品种命名,我们在做回测时需要保证读取数据时,路径及数据格式统一,方便不同策略回测,我们打开a文件夹,如下图:
这个文件夹里装着这个品种从11年以来的所有交易数据,数据命名格式为交易的合约标的(如:a1201)+ 数据日期(如:20110329),储存格式为TXT文本文件,下面我们再打开一个数据交易合约看看,如下图:
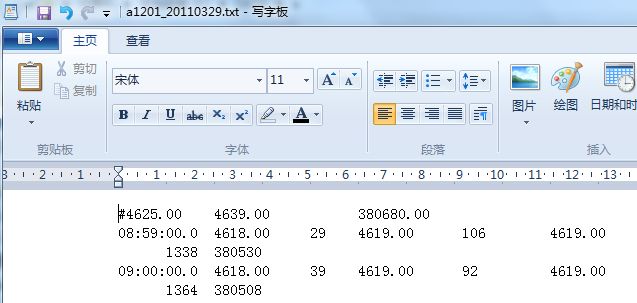
我们可以看到第一行#开头的为昨日的数据:开盘价、收盘价、成交量;第二行为今日交易数据,分别为:交易时间(time)、买价(bidprice)、买量(bidvolume)、卖价(askprice)、卖量(askvolume)、成交价(settleprice)、成交量(settlevolume)、累计成交量(totalvolume)。所有的交易数据都以以上的格式进行储存。
现在我们用PYTHON来读取一下交易文件:

输出结果:
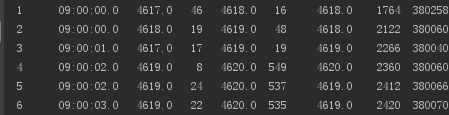
在回测中我们会写一个批量读取文件的函数,然后打开每日交易数据后,按照行数依次读取,在这里多讲一点点,我们可以观察一下上图的输出结果,其实交易数据并不是连续的,因为交易所只有在有交易产生的时候才推送一次数据,而且是数据快照,我们在做统计套利的策略时,就需要做一些处理,两个方法,一是提前对基础数据进行填充,将缺失的数据以上一个数据源填充,二是在回测程序中去识别交易时间,推送匹配的数据。但是在做其他交易策略时,数据点的缺失影响并不大。
量化交易员会使用很多不同的指标来衡量策略的表现,这个跟个人偏好有很大关系(也就是前面说到的个人对策略风险与收益之间的偏好),对EP.CHAN来说他最看重的两个指标是夏普率和回撤,在第二章中已经提到了夏普率,最大回撤和最大回撤期间(maximum drawdown duration),在这里,我们将介绍这些指标的具体计算方法。
夏普率:
通常,如果你计算你的平均收益和标准差收益需要基于一个交易区间T,T可以是按月、按天甚至按小时算,你必须确认你的交易时间跨度里有多个个T,我们记为Nt,那么年化夏普率为:
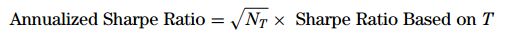
下面将用程序思维来表达计算方法,设:
value列= 每日日终的持有市值
daily return列 =value(2:end) - value(1 : end -1) / value (1 : end -1 )
每天的回报率都等于(T日终市值-T-1日终市值)/T-1日终市值
excessRet列 = dailyreturn - Rf(无风险收益率)/ 252 (每年252个交易日)
sharperatio = sqrt(252) * mean(excessRet)/std(excessRet)
大家可以测试一下每日赚0.01%的夏普率和今天赚0.03%,明天亏0.01%的两种情况下夏普率的差距,就比较能理解夏普率的概念了。
最大回撤:
最大回撤就比较简单了,设置一个变量 maxdraw = 0 ,当策略亏损时,就更新maxdraw , 交易结束时,就得到了期间最大亏损值。
最大回撤区间:
同样的设置变量 drawdownduration = 0,maxdownduration = 0
如果 t时刻策略亏损
drawdownduration + = 1
如果 t时刻策略盈利
drawdownduration = 0 (一旦盈利就初始化为0)
更新 maxdownduration
最后一部分是使用回撤数据需要注意的地方,作者东西写的比较散,但是都比较实用。
Look-ahead bias 使用未来数据
就是你在T日交易,你使用了T+1日的数据,我曾经有个策略就是这样,最终的结果就是策略盈利很恐怖,类似于如果T+1日涨,策略就在T日买入。基本上就是上帝视觉,你知道了明天市场将发生的情况。
Data-Snooping Bias 过度拟合
前面已经讲到了这个概念,解决方法:1、用新数据测试 2、对策略进行鲁棒性检验
Sample Size 数据集大小
以前有一个同学告诉我他发现了简单移动平均线赚大钱,我就问了他你按什么数据区间测试,他回答按照每日,共才800个数据。我说基本你选择了最优路线就回到了过度拟合中。
我这里随便挑了两个合约,工商银行和建设银行,因为都是国有银行,两个交易序列之间具有较高的相关性,我们统计套利的基础原理是基于价差的回归。我们使用tushare库来直接获取这两个银行2015至今的日收盘价数据,这样可以让整个程序直接在任何一台电脑上奔跑,不用依赖基础数据,建议还是把代码都自己敲一遍。
如果没有太多编程基础的童鞋,可以先看一些PYTHON入门的东西,然后就可以轻松的跟完整本书,我始终认为编程只是技能,够用就行了,重要的交易策略思维,因此整个专栏都不会去死磕技术,如果只是想学习“编程技术”的童靴,可以关注相关技术类专栏,深信都会比我**得多。
我使用的编程工具为:anaconda + spyder ,这里力推anaconda,因为已经集成了科学计算所要用到的几乎所有库。官网地址为:https://www.anaconda.com/download/ 下载安装即可。
首先我们引入tushare库,data1储存工商银行的日数据,data2储存建设银行的日数据,接着我们把两个数据的长度打印出来,顺便保存数据看看数据结构,发现如下图:
两个数据长度相同,但是我试了其他股票有不相同的情况,所以在使用数据时我们还是按照日期来取数,然后发现比较累人的是,dataframe并没有date键值,我们存储数据再重新读取一次。
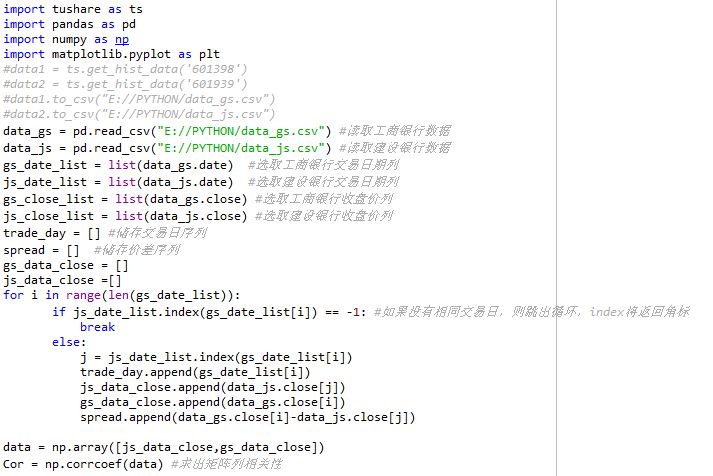
这里我们采用一种较为快速的方法,先求出修正后的价差列,这种方法可以在初期做策略回测时使用,因为数据处理较快,也较为方便,后期还是需要按照实盘的程序进行依次识别处理。我们在开始策略前先直观感受一下两者的走势及价差序列:
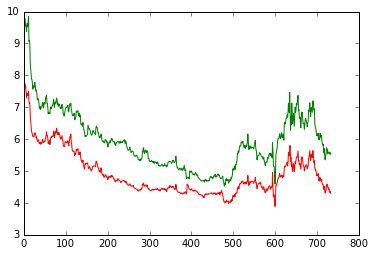
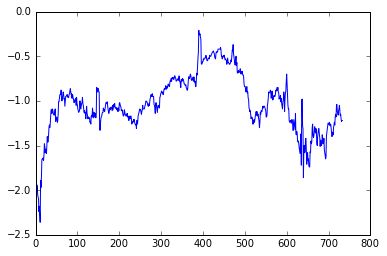
现在我们求出一个spead序列和交易时间trade_day序列:
这里主要实现了一个交易日期匹配,并选择相应的交易数据,求出交易天trade_day和价差序列spread。最后我们求出了两个交易标的之间的相关性Cor = 0.9647,两者之间经验证具有强相关性。下面是一个回测最简单结构,首先是参数定义,然后是按照交易日循环,接着是在每个交易日去运算并记录结果:
这边我们看看output的输出:
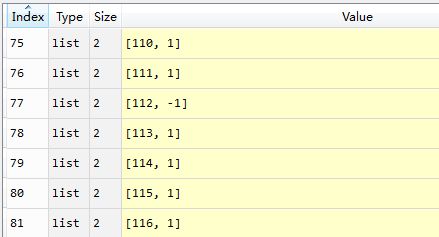
我们发现有很多情况第一天刚记为-1,后一天又记为1,这样的表现是因为股票价格剧烈变化,我们一般回测完后都需要去看看策略什么时候进场、出场、是否符合我们开始的设想,以及策略中有没有什么较为极端的情形发生,总之,策略复盘非常重要。
本书这个也是最简单的演示了,我们设计了两个参数 n 和 m ,并且赋予了初值,参数优化指的就是修改n,m来找到最优参数让策略盈利更好,output这边只记录了两个数据,一个是当价差过高或者过低时记录,并且记录此时的交易日。后面就可以用这两个数据计算持仓盈亏及交易,用程序化的思维直接的理解什么是回测,大概的思路是什么。
第五章我们直接跳过,因为讲的是如何实盘系统,参考价值较为低。第六章就是展开讲了凯利公式,当然作为入门来讲,用凯利公式做资金管理是没有任何问题的,但是在实际交易中还是要按照实际的数据表现去调整自己的资金配比,找到自己最舒服的公式。
所有的交易策略都会面临偶然损失,回撤有时候会持续几分钟或者几年。做量化交易,重要的是管理风险,限制回撤幅度到可忍耐范围内,找到最优的杠杆率,最大可能的实现财富增长。资金及风险管理的核心工具就是凯利公式(KELLY FORMULA)。假设你现在使用多个策略交易,每个策略都有自己的预期收益和标准差。那你面临一个问题,怎么把资金合理的分配到各个策略中呢?
每一个优化问题都有一个初始目标,我们的初始目标就是最大化我们的长期财富。首先假设:每个交易策略的回报 i 的概率分布为Gaussian,均值为Mi,标准差是Si(i是超额收益的概念)。这个是金融学上一个通常的假设,但是对于实践中来讲并不是非常准去。损失发生的频率比高斯分布的概率大,但是,每一个科学和工程计算都是始于最简单的模型。凯利公式:
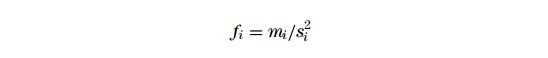
因为回报i的分布并不是真正的高斯分布,所以交易员喜欢用公式计算出来结果的一般作为杠杆比例,这样更安全,也被称为“half-Kelly”
EXAMPLE:基于凯利公式计算最优杠杆率
假设我们的投资策略持有SPY(S&P500指数基金),我们再假设SPY的平均收益为11.23%,标准差为16.91%,无风险收益率比为4%,因此这个投资策略的超额收益为7.231%
夏普率 = 7.231%/16.91% = 0.4276
凯利公式计算:

f = 2.528表示,对于这个策略,如果你有10万现金投资,并接受投资收益和标准差的假设,你可以借入资金,买入价值25.28万的SPY,凯利公式不仅可以用来计算最优的杠杆率,还可以用来做风险管理,因为凯利公式是基于平均收益率和标准来计算,当市场剧烈波动时,标准差分母就会变大,那么凯利公式计算出来的杠杆率就会变小。
PS:该公式肯定并不是绝对最优的,在交易多品种时有时候平均分配本金也不错(震惊脸)
交易策略能够赚钱是基于交易标的的价格形成了回归或者趋势,否则,就是随机游走,交易就不会有盈利。如果你相信股票价格是均值回复的,而现在的价格相对于大多数情况较低,那么你应该现在买入,然后当价格走高时卖出。然而,如果你相信价格是趋势的,如果他现在比较低,那么你就需要卖空,然后等价格走低时平仓。
学术研究表面股票价格的走势接近于随机游走,但是这并不意味着在一些特定条件下,不会存在均值回归或者趋势的表现。甚至,在不同的时间跨度下,股票价格可以同时表现为均值回归和趋势。开发策略很重要的一点就是判断股票在一个固定时间跨度下价格表现为趋势或者均值回复。
人们喜欢描述价格既有均值回复又有趋势的状态叫做“fractal”,技术分析者或图表分析者喜欢用Elliott Wave理论来分析这个现象,有一些其他人喜欢用机器学习(比如说隐马尔科夫链、卡尔曼滤波,神经网络等)来发现价格是处在均值回复状态还是趋势状态。我本人是未发现普适的理论来判断趋势或均值回复。但是,我发现一个很有用的假设,如果公司的期望收益不发生变化,股票价格都会处在均值回复状态。事实上,金融研究者(Khandani and Lo,2007)已经发现一个简单的短期均值回复模型是可以盈利的,当然,这个策略能否在加上交易成本后仍旧盈利是个问题。
尽管均值回复是一个流行的策略方向,但是针对此类策略进行回测时要非常的小心。
1、许多历史交易数据是不精准的
2、数据生存偏差依旧对均值回复策略的表现有很大影响。
信息的传播是有过程的,信息传播是逐渐的,这个过程中就会产生趋势,当越来越多的人知道确切的消息,更多的人就会决定买入或者卖出股票,因此让股票向同一方向运动。有一个趋势策略就是:post earnings announcement drift。这个策略就是当公司盈利大于预期时,就买入股票,反之亦然
趋势也可以在群体行为发生时产生:交易者都按照别人的决定来判断自己的交易方向。没有人可以有玩呗的信息来决定交易,每个人都必须对别人的决定做出反映,但是确很难判断别人做出的决定的质量高低。但是悲剧的以上两种情况都很难量化。最后一个均值回复和趋势策略不同点时值得深思的。
使用同一种交易策略的交易者们之间是怎么相互影响的?对于均值回复策略,最典型的影响就是套利机会的交易机会,交易机会会逐渐将至0,比如说当价格过高,于是所有人都会卖出,价格将逐渐降低,回到正常水平,但是对于趋势策略来讲,越多的人使用趋势策略,趋势将会持续,当信息传递越快,交易者优势越大,均衡价格将会更快达到。当达到均衡价格后,交易者就没有盈利机会了。
如果我们的母的是预测市场从牛市到熊市的转折点,那么我们需要重点讨论这种市场转换类型。我已经发现了两种市场转换:(1)2003年股票价格以10进制表示 (2)2007年去除报升原则
这种市场转变是监管者的规则发生变化所造成的,但是这种情况是预测不了的,比如说期货市场过热时,我们的交易所提高交易手续费、最大手数,对股指期货的市场结构产生了重大影响。
通常情况下,主要的市场转换类型是:通涨VS通缩、高波动VS低波动、均值回复VS趋势,波动率模式的转换是学术研究工具最容易解释的,比如说GARCH模型。如果谁能够更准确的预测波动率,谁就能成为一个优秀的期权交易员。
学术上试图用模型去解释市场转换,但是会做很多的假设,比如说假设这两种情况发生时股票价格有不同的概率分布。最简单的模型就是假设log(Price)服从正态分布,这两种情况的价格有不同的均值和标准差。
Turning points models是一个数据挖掘过程,所有可能的变量都会影响预测转折点,变量包括现在的波动率、最近一段时间的市场转向,宏观数据、石油价格变化、债券价格变化等。
平稳和协整
如果股票价格是平稳的,那么均值回归策略将会特别匹配,但是,多数股票价格都不是平稳的,但是如果你交易一组股票(持有空头A,多头B),那么价差可能就是平稳的,A、B股票就是协整的。通常,如果两个股票价格表现出协整,那么他们大概率都是同一领域的公司,如图所示,如果我们要买入套利组合,就是持有多头1手GLD,和空头1.6766手GDX,这个套利组合的价格就构成了一个平稳时间序列,GLD和GDX的组合比例可以通过回归方程计算。
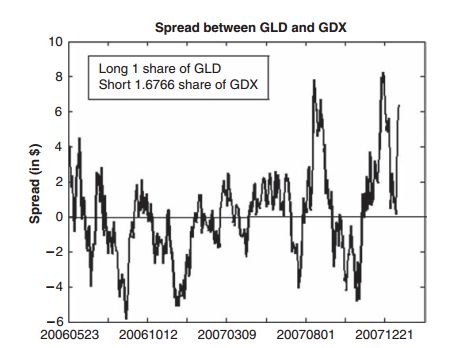
许多套利交易者对于平稳和协整并不是很熟悉,但是他们都对相关性很熟悉,但是他们是不同的,想过性是指在同一的时间纬度下,他们的股票投资回报是相关的,如果两个股票是正相关,那么他们在大多数情况下是向同一方向运动的,然而,两者之间的正相关关系并没有说明这两只股票的长期表现。特别是,它不能保证股票从长期来看,价格不会越走越远。但是,如果两个股票是协整的,那么(适当加权)未来价格不太可能发散。但他们短期(或每周或任何其他时间段)收益可能是不相关的。
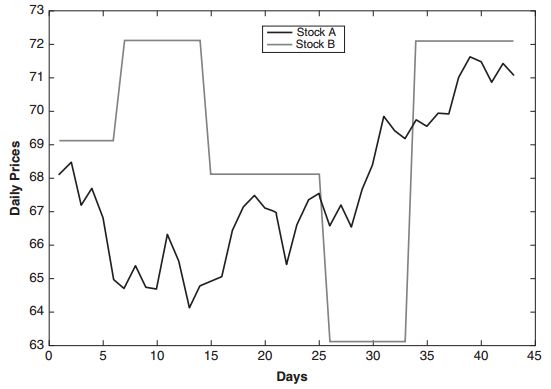
作为例子,A股票和B股票,他们是协整的但不相关,见图。股票B显然没有以A股移动任何相关的方式:有几天他们移动在同一方向上,其他日子正好相反。大多数日子,股票B一点也不动。但请注意,A股和B股之间的价差通常会在一段时间后回到1美元左右。
平稳性并不局限于股票之间的价差:它可以也可以在一定的货币兑换率中找到。例如,加拿大元/澳元(加元/澳元)交叉汇率等。
金融评论员常说这样的话:“当前市场看好价值股票,“市场关注收益、增长“,”或者“投资者正在关注通胀数字。”我们如何量化这些和其他常见的回报驱动因素?
有一个众所周知的定量金融框架叫做因子模型(又称套利定价理论),试图捕捉不同收益的驱动因素,如收益公司的增长率、利率或市值。这些驱动因素称为因素。数学上,我们可以写股票的超额收益(收益减去无风险利率)R:
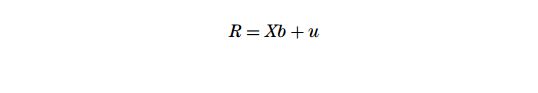
最简单的因子模型就是Fama和French 1993年提出可以建立一个三因子模型来解释股票回报率。模型认为,一个投资组合(包括单个股票)的超额回报率可由它对三个因子的暴露来解释,这三个因子是:市场资产组合(Rm− Rf)、市值因子(SMB)、账面市值比因子(HML)。
最后书中提了一个一月效应策略(因为美国税收问题,产生一个集体行为)。这个给了我们一个很好的策略开发方向,与其无脑测试各种“技术指标”,不如想想策略思路,归纳与演绎的区别。




