我们在《正确理解 Barra 的纯因子模型》介绍了 Barra 的多因子模型。该文讨论的重点在于从业务上说明国家、行业、风格纯因子投资组合的含义,而非具体的数学计算。
不过,后来我意识到我给自己挖了一个坑。因为有个小伙伴给我们留言询问在计算因子协方差矩阵时,Barra 使用的 Newey-West 调整是怎么一回事儿。所以今天就来填坑了。本文就来简单说说 Newey-West 调整对于协方差矩阵估计的重要性。
在我为了写作本文而查阅的相关资料中,除了文末参考文献中的几篇重要论文外,知乎上的两篇讨论也给我很多启发(见参考文献),特此感谢。
通过多因子模型,我们可以把个股的收益率表达为因子收益率和个股特异性收益率的形式:
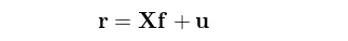
在上式中,r 为 N × 1 维个股收益率向量(省略了时间下标,假设有 N 支股票)、X 为当期因子暴露矩阵(N × K 矩阵,K 为因子个数),f 为 K × 1 维因子收益率向量,u 为 N × 1 维个股特异性收益率向量。
使用因子模型的好处是可以用它来推算个股收益率之间的协方差矩阵。直接计算股票收益率协方差矩阵的问题是该矩阵有 0.5 × (N^2 + N) 个不同的参数需要估计。这意味着我们至少需要 N 个样本数据来计算它。由于 N 是个股的个数,通常很大,因此这几乎是不可能的任务。
多因子模型的好处是,它把股票的收益率转换为因子收益率的线性组合。因此股票的风险也转换为因子风险的组合。因为因子的个数远远小于股票的个数,估计因子收益率的协方差矩阵要容易的多。对r = Xf + u 等号两边同时做协方差运算可得:
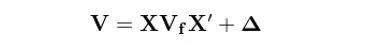
其中,V(N × N)是股票收益率的协方差矩阵,V_f(K × K)是因子收益率的协方差矩阵,而 Δ为 N × N 对角阵,其对角线上的元素对应个股的特异性收益率的方差 —— 多因子模型假设股票的特异性收益和因子解释的收益率之间是**的,因此因子收益率和特异性收益率之间不存在协方差;此外,模型同时假设不同股票的特异性收益率是相互**的,因此股票的特异性收益率的协方差也为 0。
可见,为了得到 V,对于 V_f 的求解至关重要。Newey-West 调整就是为了更准确的计算出 V_f。
在介绍协方差矩阵的 Newey-West 调整前,我们首先看看当因子收益率在时序上没有相关性时的做法(通常的做法)。为了简化数学表达,在下面的推导中,假设收益率已经去均值化(demean)了。假设共有 K 个因子,令 F_t 表示第 t 期这 K 个因子的收益率向量,它是一个 K × 1 向量:

在上面的表达中,符号 f_t^(k) 既有下标也有上标:下标 t 表示第 t 期,而上标 (k) 表示第 k 个因子,因此 k 的取值是从 1 到 K,所以 f_t^(k) 就代表第 t 期,因子 k 的收益率(按照本小节一开始的说明,所有的 f_t^(k) 都已经 demean 了)。
将 F_t 和它的转置 F_t’ 相乘,利于线性代数的定义得到 F_tF_t’:
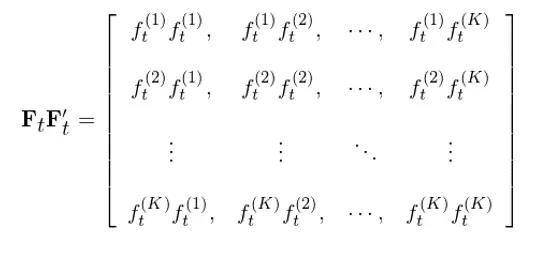
假设计算协方差矩阵的时间窗口为 T,即 t 的取值为 1 到 T。对 T 窗口内的所有 t 都进行上述运算并把不同 t 的 F_tF_t’ 相加得到 ΣF_tF_t’:
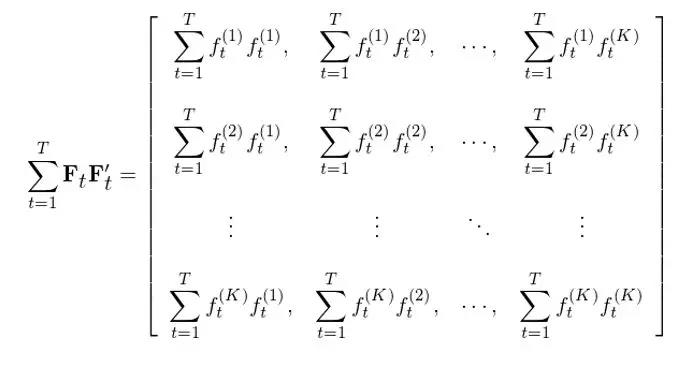
最后,将 ΣF_tF_t’ 除以时间窗口长度 T 就得到 (1/T) ΣF_tF_t’,这正是以 T 窗口为长度计算出来的 K 个因子收益率的协方差矩阵 V_f:
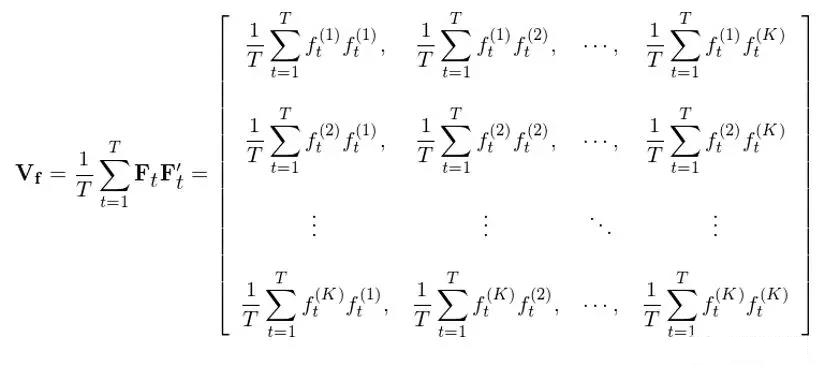
写了这么“啰嗦”的推导,实在不是因为我有编辑数学公式的癖好,而是希望我们能够对如何从因子收益率向量求解协方差矩阵加深印象。这是因为 Newey and West (1987) 这篇提出 Newey-West 调整的论文行文风格非常干练、没有任何废话,上来就是矩阵和向量的运算,直接给出了计算向量 h_t(θ) 的协方差矩阵 S_T 的表达式(见下红框图划重点的部分)。我第一次读这篇论文的时候感到云里雾里,难以把该文的推导和 Barra 文献中关于 Newey-West 调整的说明联系起来(换句话说,看了 Barra 的文档说用了 Newey-West 调整,然后找到 1987 年的这篇论文一看,第一感觉却是“这俩有关系吗……”)。所以在我自己写作时,我花费了上面笔墨解释了协方差矩阵到底是怎么从单期收益率向量推导出来的,这能帮助我们更好的阅读 Newey and West (1987)。

在前文推导中,F_t 可以被认为对应 Newey and West (1987) 中的 h_t(θ),而 V_f 对应 Newey and West (1987) 中 S_T 的估计量。这样通过上面的推导就不难理解在 Newey and West (1987) 中 S_T 的估计量为什么会有和本文中的 V_f 一样的表达式,这对于理解 Newey and West (1987) 很重要。
Newey and West (1987) 是严谨的数学论文,因此行文在总体和样本统计量之间切换。但在阅读本文时请暂时遗忘总体 vs 样本统计量。本文的所有 notation,比如 F_t、V_f 这些都是针对样本数据而言,正如 Barra 的模型一样 —— 我们关注的是如何使用样本数据、通过 Newey-West 调整来对未知的协方差数据进行估计。
在接下来的行文中,我们只要记住:F_t 是一个 K × 1 的列向量,代表第 t 期 K 个因子的收益率向量(demean 之后的收益率);而通过总共 T 期(sample size)的 F_t, t = 1, 2, …, T 计算出来的因子收益率协方差矩阵 V_f 为(请记住这个式子,下面讲 Newey-West 调整时还会用到):
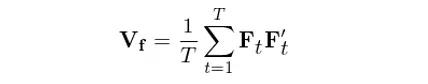
上式就是当因子收益率在时序上没有自相关性时计算协方差矩阵的一般方法。
值得一提的是,在 Barra 的模型中,它们还对上式进行了一点点修改。上式中对时间窗口 T 内的各期收益率采用了简单平均,而 Barra 的模型采用了指数平均,目的是为了让更近期的数据有更高的权重,从而快速捕捉波动率的变化。使用指数平均对上式进行改进不是本文关注的重点,因此不再赘述。感兴趣的朋友请参考 Briner et al. (2009) 中的第 5.1 节(这个文献是 Barra 的 EUE3 模型 —— 欧洲股权模型,它和 Barra 的 USE4 以及 CHE5 模型使用的方法相同)。
4Newey-West 调整
上一节给出了当因子收益率在时序上不相关时求解协方差矩阵的方法。然而,当因子收益率在时序上有自相关性时,上节的计算方法就有问题了,它不是真实协方差矩阵的一个相合估计(consistent estimation)。
相合估计大致可以理解为随着样本个数的增加,一个统计量的估计越来越逼近其真实值,实现在概率上收敛的效果。相合估计有助于我们计算统计量的估计误差,这对于后续使用该估计量至关重要(比如计算置信区间等)。
为了得到相合估计,必须考虑因子收益率之间的自相关性,从而在计算协方差矩阵时考虑自协方差的影响,这就是 Newey-West 调整的作用。
此外,Barra 的模型中必须要进行自协方差调整的另一个原因是,Barra 的多因子模型是日频的,因此每天都会有一期因子收益率,而然它们的风险预测模型是月频的。这意味着 Barra 需要把日频的协方差矩阵通过尺度变换(scaling)变成月频的协方差矩阵。在这个过程中就必须考虑日频收益率之间的序列相关性。
“
All EUE3 risk forecasts are monthly volatility estimates. The use of daily factor returns in (5.1) necessitates scaling the covariance matrices to monthly horizon. This scaling step needs to account for possible serial correlation in subsequent factor returns.
”
假设单期的因子收益率 F_t 满足一个 q 阶的序列相关性,即 F_t 可以用 MA(q) 来刻画。则协方差矩阵的一个最简单的相合估计为(对应 Newey and West 1987 中的式 (4)):
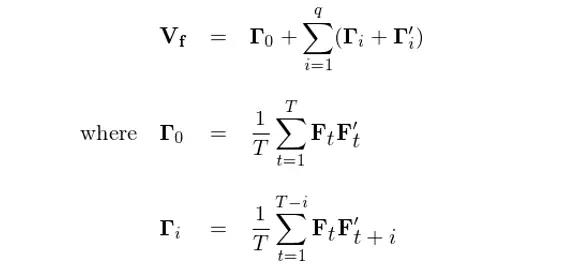
在上式中,Γ_0 就是第三节中不考虑自相关性的协方差矩阵,而任何 i ≠ 0 对应的 Γ_i 代表着由 F_t 和从时刻 t 滞后 i 期得到的 F_{t+i} 计算出来的自协方差矩阵。举个例子,令 i = 3 则 Γ_3 为:
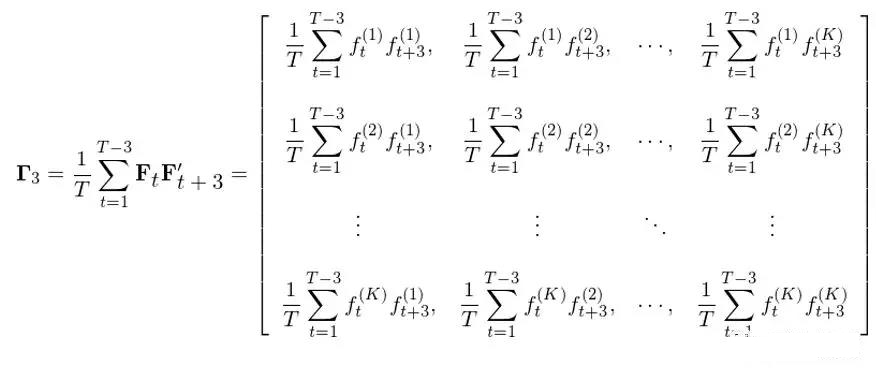
从这个例子中不难看出 Γ_3 本身不一定是对称的,因此在上述调整中,对于任何的滞后期 i,Γ_i 和Γ_i’ 总是成对出现(Γ_i + Γ_i’ 是对称的)。需要特别提醒的是,当计算滞后期为 i 的自协方差时,由于 F_t 和 F_{t+i} 之间有间隔 i,因此在总共 T 长度时间窗口内,这二者的配对儿个数为 T - i、少于 T,但是在计算 Γ_i 的表达式中,永远是除以 T,而不是 T - i。
上述调整(请注意,我没有称该调整为 Newey-West 调整!下面马上就会解释)的本质是使用最大到 q 阶的自协方差 Γ_i 对 Γ_0 进行修正,从而得到调整后的因子收益率协方差矩阵 V_f。
上面这个调整有一个小问题,就是如此得到的协方差矩阵 V_f 不一定是半正定(positive semi-definite)的,而协方差矩阵必须是半正定的。为了解决这个问题,大名鼎鼎的 Newey-West 调整出场。它在上述调整的思想上,对 Γ_i 的修正加入了 Bartlett 权重系数 1 - i/(1+q)。可以看到,该系数和滞后期 i 成反比,说明两个收益率向量 F_t 和 F_{t+i} 的间隔越大,Γ_i 的权重越小。最终,协方差矩阵的 Newey-West 调整为(对应 Newey and West 1987 中的式 (5)):
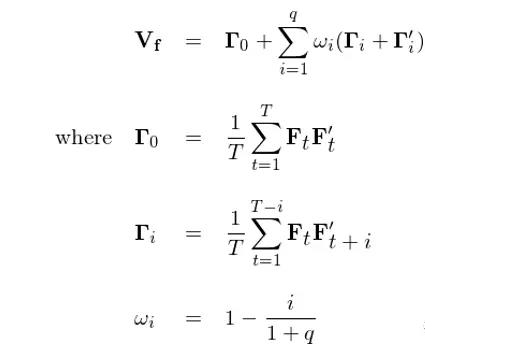
Newey and West (1987) 证明了上面这个协方差矩阵是一个相合估计,而且它是半正定的。
这就是 Barra 采用的 Newey-West 调整。在 Barra 的 EUE3 研究报告(Briner et al. 2009)中的第五节对此有简单的说明。此外,前文提到,Barra 需要用日频的协方差矩阵通过 scaling 转换成月频的。为此,Barra 的做法是对 Newey-West 调整后的日频协方差矩阵乘以一个月内的交易天数,即 22,这就得到了最终的因子收益率协方差矩阵(下图截自 Briner et al. 2009,在 EUE3 中 Barra 采用的最大滞后期为 15)。

最后想要指出的是,在计算股票特异性收益率的协方差矩阵上,Barra 同样采用了 Newey-West 调整,只不过对于个股特异型收益率,Barra EUE3 模型选择的最大滞后期为 10。
好了,终于把之前的坑填上了。学习大概就是不断的挖坑然后再填坑的过程。
从 Barra 自己的论述来看,它们在因子收益率协方差矩阵以及股票特异性收益率的方差矩阵上面都进行了 Newey-West 调整,且这一调整被沿用到了最新版的模型中,足见这一步的重要程度。
值得一提的是,在 Barra 的 USE4 模型中,Barra 把协方差矩阵拆成了分别计算每个因子收益率的波动率以及不同因子之间的相关系数矩阵(而非直接求协方差矩阵,见 Menchero et al. 2011)。因此,它们对因子的波动率和相关系数矩阵分别进行 Newey-West 调整。Barra 的 USE4 模型并没有披露具体细节,但万变不离其宗。我猜想应该和 EUE3 模型中的处理方法(即本文介绍的方法)一致,区别就是我们使用不同因子的收益率序列 {f_t^(k} 计算出类似于本文中的 Γ_i ,即利用 K 个因子的 {f_t^(k)} 序列求出不同滞后期 i 下相关系数的矩阵以及方差的对角阵,然后用这个矩阵替换 Γ_i套入 Newey-West 调整的表达式即可;核心是用 {f_t^(k)} 找到正确的矩阵。
比如因子 (1) 和 (2) 之间的滞后期为 i 的相关系数可以通过下式计算,对所有因子和所有最大滞后期 q 以内的 i 计算就可以求出类似于本文中 Γ_i 的相关系数矩阵,然后就可以运用 Newey-West 调整得到相关系数矩阵的相合估计。
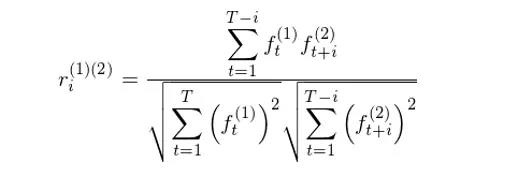
我自己尚未对 Newey-West 调整在 A 股上的有效性进行验证,但是国内一些券商的金工团队在这方面已经有了不少的探索。在这方面,天风证券应该算是走在了前列(天风直接对协方差矩阵调整,类似 EUE3 模型)。它应该是我最早看到将 Barra 这一套系统应用于国内 A 股市场上的(至少是 1 年以前),并且还非常有创造性的利用了最优化的手段配合 Barra 的体系来进行选股。进行最优化的前提条件当然是各种输入要尽可能准确,这就能体现出 Newey-West 调整的重要性了。在今后我们进行实证之后,如果有新的发现,也会及时和各位分享。