决策树
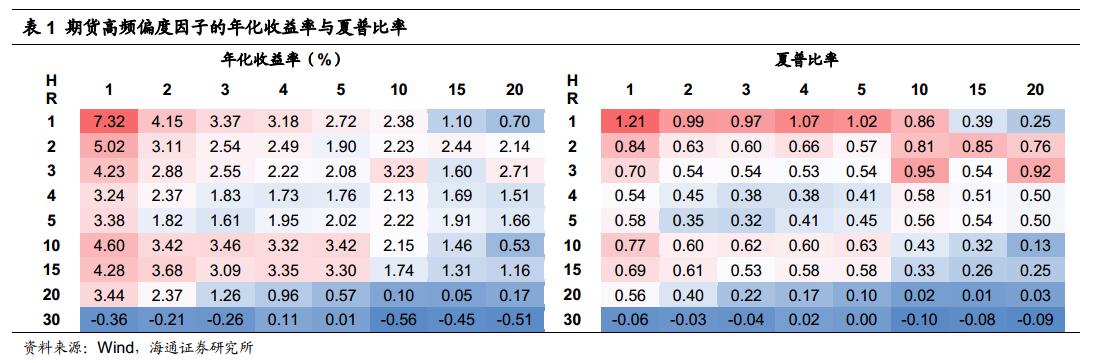
决策树方法(decision tree)是一种代表因子值和预测值之间的一种映射关系。从决策树的“根部”往“枝叶”方向走,每路过一个节点,都会将预测值通过因子的值分类。决策树的结构如下所示:
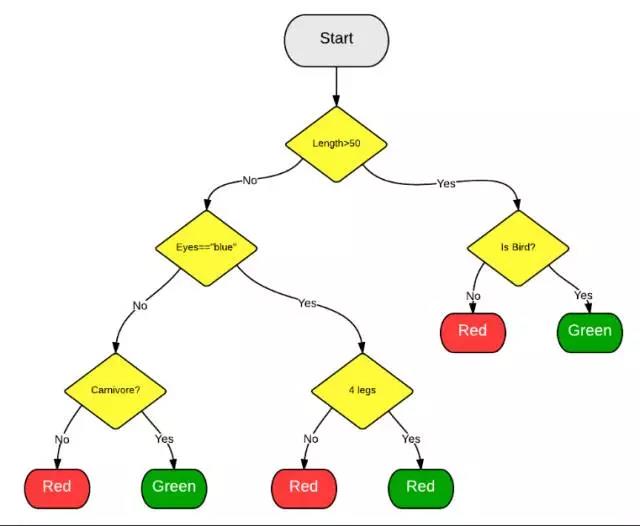
如果我们把上图中的绿色想象成股票下跌,红色为股票上涨。同时,在每个黄色节点的分类是根据因子值阈值大小选择走左边还是右边,那么走到决策树的末端能够预测出股票的上涨与下跌。
虽然决策树能够很好的处理数据的异常值,使得极端值不会影响整个模型的构建结果,但是同样的,决策树容易出现过度拟合现象,无法正确处理噪声数值。于是,我们需要随机森林算法来改善。
Tips: 在量化预测中,由于金融市场的数据存在大量噪声,我们必须限制树的高度(即层数)防止过度拟合。当预测正确率在70%~80%之间时,可以设定决策树的最大层数。
随机森林
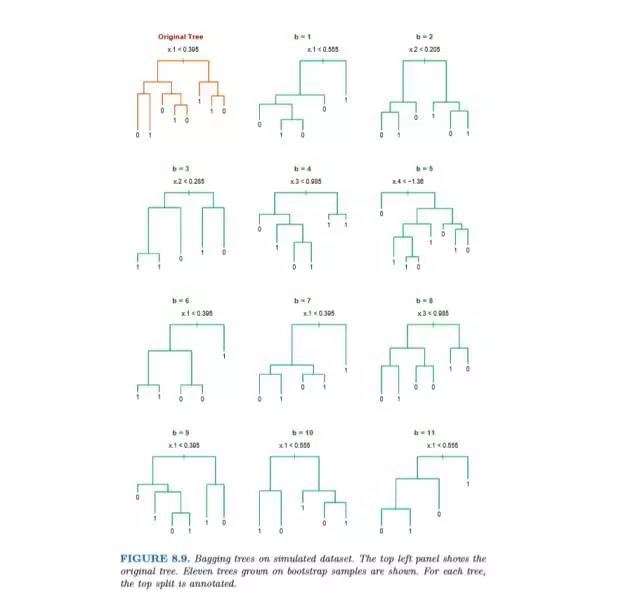
“森林”即指大量的决策“树”组成了森林。随机森林的想法来自于bootstrap aggregating (缩写为 bagging);即让该学习算法训练多轮,每轮的训练集由从初始的训练集中随机取出的n个训练样本组成,某个初始训练样本在某轮训练集中可以出现多次或根本不出现,训练之后可得到一个预测函数序列h_1,⋯ ,h_n ,最终的预测函数H对分类问题采用投票方式,对回归问题采用简单平均方法对新示例进行判别。所以,bagging的主要想法是平均许多噪声较多但是相对来说是无偏差性的模型,以此来降低噪声。
B = 建立的树的总棵树, T_1...T_b...T_B = 1~B编号的树,N = 总训练样本数,Z = 抽样数,p = 总因子数,m= 抽取因子数,树的高度 = h。
随机森林(Random Forest)的算法:
For b=1 to B;
(a) 从训练样本总数为N中随机抽取样本 Z个
(b) 以下列三个标准来建立一棵随机森林的树 T_b,直到树的高度达到h
i. 从p个因子中随机取出m个因子
ii. 找出m个因子中最佳的分类因子p*
iii. 以该因子将一个节点分成两个子节点
输出树的合集{ T_1...T_b...T_B }
将测试组的数据放入所有的棵树中得出B个预测结果,求出预测结果的平均值则为我们最后需要的预测值。
总结
在量化中实现随机森林算法时,建议在决策树的建立时,可以使用python的sklearn。然而,更加推荐根据上述算法过程为自己的策略量身定做。