RNN是一个循环递归网络,因此在t时刻,网络的输出误差不仅与t时刻的隐含状态有关,也与t时刻之前的所有时刻的隐含状态有关。这一特点,正表明RNN相比传统的隐马尔科夫模型的优势是它充分考虑了历史所有时刻的状态。
当我们构建好了一个RNN模型之后,最大的难点就在于训练这个模型,这里说的训练实际上就是数学上的优化过程。在训练神经网络的时候,后向传播算法是最流行的训练算法,而BPTT则是基于它的一个变形。那么什么是后向传播算法呢?
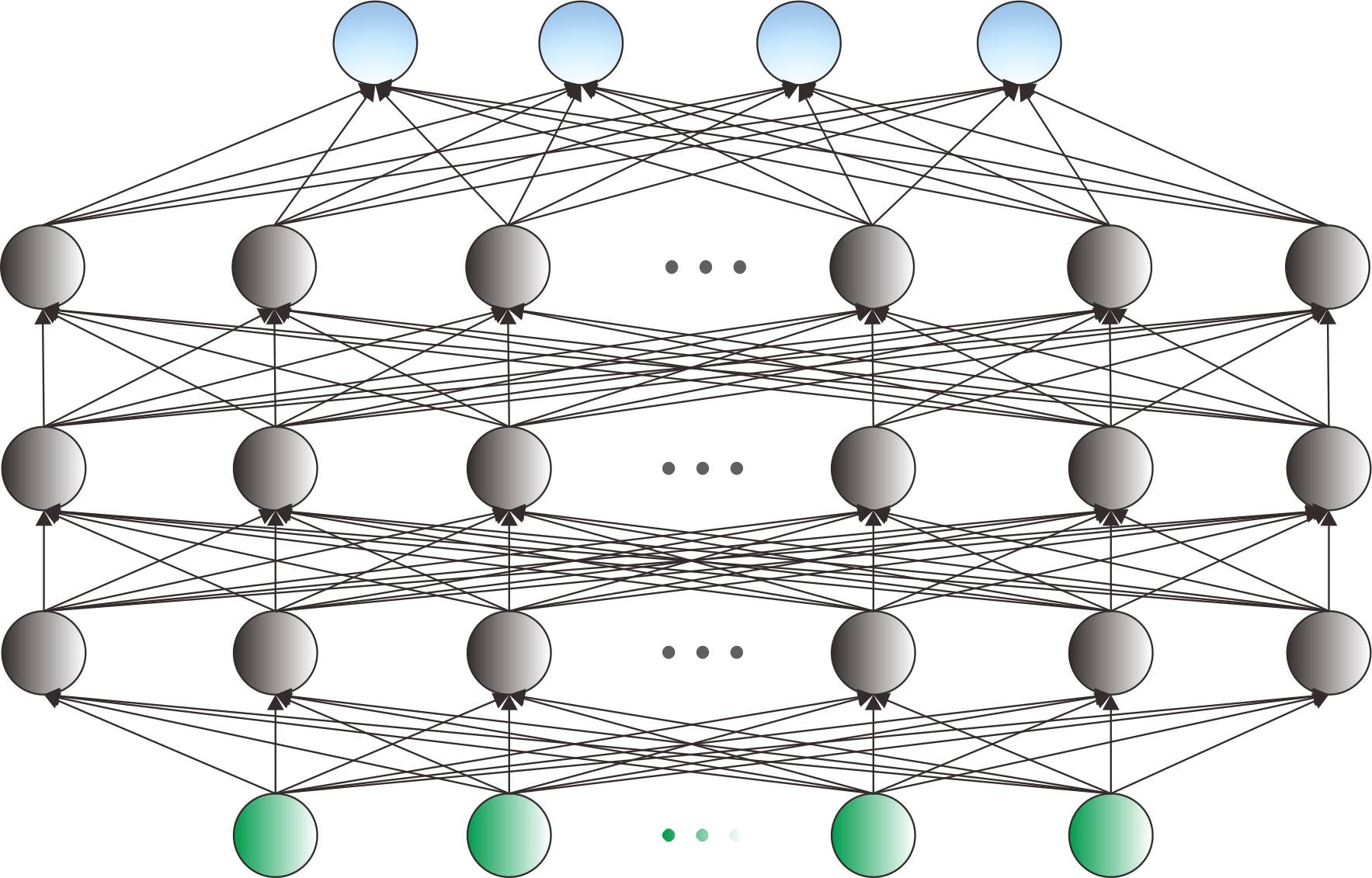
考虑一个多层感知器(MLP),假设它有K个隐含层,考虑输入层和输出层的话一共有K+2个隐含层,输入层的神经元个数为M,输出层的神经元个数为N,并且每一个隐含层的神经元个数为H_k。后向传播算法的步骤通常如下:
初始化神经元的所有参数,包括输入层与隐含层之间的权重、隐含层与隐含层之间的权重以及隐含层和输出层之间的权重(这里的权重包括连接权重和神经元偏置),权重初始化的方法通常有产生高斯随机数、线性均匀随机分布、赋予常数0等等。设定参数更新的步长,即学习率的大小。
利用MLP的前向计算公式,将输入值代入MLP网络得输入层神经元中,计算出每一个隐含层的神经元激活值以及输出层每个神经元的值。
计算出输出层每个神经元的误差,这里的误差表达式可以有很多种类型,例如常见的有平方差形式、交叉熵形式等等。训练网络的目标就是要使得输出层神经元的总误差E达到最小。
根据第K+1层与第K+2层之间的数量关系,计算出E对第K+1层上每个神经元的偏导数,由此偏导数即可计算出E对第K+1层与第K+2层之间权重的偏导数,于是第K+1层与第K+2层之间权重即可更新。
以此类推,一直计算到第1层神经网络上的所有神经元的偏导数,这样即可更新输入层与第一层之间的权重。这就是误差的后向传播。
完成以上即为一个Epoch,而训练的目标就是不断重复这样的Epoch,直到总误差E收敛到某个规定的阈值为止。
以上说的是用于训练MLP的后向传播算法,由于权重的更新是通过不断减去它的一阶偏导慢慢实现的,因此我们称这种算法为梯度下降法。虽然梯度下降算法在误差平面上只能找到局部最优值,但是这个缺点可以被一些错误得以很好避免,例如在训练的时候可以增加一些噪声、可以按照Epoch的增大而动态改变学习率的大小、采取不同的初始化方法、采取预训练的权重等等。
对于RNN来说,传统的后向算法已经无法适用了,这个时候我们需要把RNN网络在时间维度上展开,这个时候我们采用的是基于时间的后向传播算法(BPTT)。
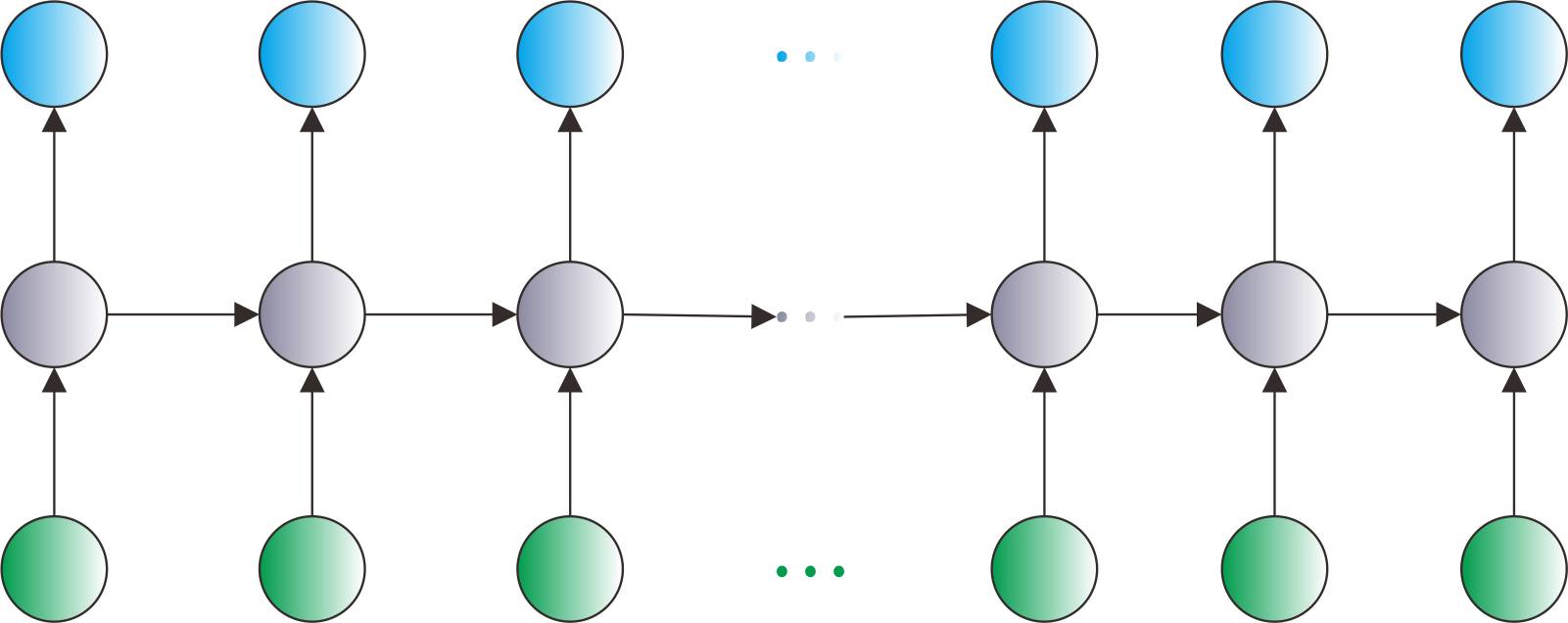
BPTT算法的计算步骤如下:
初始化、前馈计算,跟后向传播算法的流程一样
计算每一时刻输出层K的误差,总误差就是我们要优化的变量。
计算T时刻隐含层K-1层的误差、第k-1层历史时刻的误差、第K-2层T时刻的误差。
更新K-1层T时刻的权重。
依次类推,直到第一层t=1时刻的权重被更新,即完成一个训练Epoch。
持续迭代,直到总误差收敛为某个阈值为止,停止训练
BPTT算法的计算复杂度相比于传统的BP算法要复杂N倍,N是整个网络的连接个数。而BPTT另外一个计算上的缺点则是它考虑了所有的历史信息,于是有人提出了使用truncated-BPP,即只考虑固定长度的历史,超过此时间的历史信息不用纳入BPTT中计算。这在一定程度上会影响RNN的记忆性,不过就算运用完整的BPTT算法,RNN的记忆性也无法长期保留,一个研究观点表明RNN最多只能记忆10~20个时间点。
通常训练一个RNN需要很多个Epoch,花费几个小时甚至几天都有可能,并且,训练RNN也没有训练MLP那么稳定,通常可以采取的措施有使用Dropout、使用批归一化等技巧,而对于网络超参的设置需要因数据规模而定,甚至有时候需要在实践中得出经验甚至是要靠直觉来判断。