学术界和实务界对股票收益的预测都比较感兴趣。因素模型一般用一些经济指标作为解释变量来预测股票收益。例如D/P, E/P, B/M等估值比率。这些模型大多数关注的是样本内检验,虽然回归结果显示这些比率对股票超额具有较好的样本内解释能力,但把视野拓展到样本外,这些模型能否稳健预测未来收益,仍存在较大争议。今天我们介绍这一领域的两篇经典研究。
1. A Comprehensive Look at The Empirical Performance of Equity Premium Prediction
Welch and Goyal (2008)研究美国股权风险溢价时发现,与历史平均收益相比(在做预测评价时会有一个标准,一般以过去某段时间的平均收益作为预测期内的收益基准),现有文献中基于一系列经济指标的样本外预测并没有表现出持续、稳健的良好效果。
本文综合性的审视讨论了现有的各种因子模型,吸纳了大量的变量、不同的考量角度、以及不同的时间区间。结果发现,多数因子模型预测能力是不稳定的。
被解释变量:股票超额收益(equity premium)
解释变量:
【股票特征相关变量】
(1)股息(dividends)
d/p (dividend price ratio)
d/y (dividend yield)
(2)收入(earnings):
e/p (earnings price ratio)
d/e (dividend payout ratio)
(3)股票方差(svar)
(4)截面溢价(cross-sectional premium,csp):测度了高beta股票和低beta股票的相对估值。
(5)账面价值(book-to-market ratio),b/m
(6)公司发行活动(corporate issuing activity)
【利率相关变量】
(1)tbl (treasury bills)
(2)长期收益率
(3)公司债券收益率:
(4)通胀率(infl,inflation)
【宏观变量】
投资对资本的比率(investment to capital ratio)
i/k = 总投资/整个经济体的总资本
方法上,采用单因素回归和多因素回归
单因素回归:
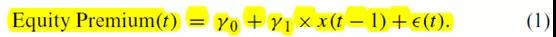
多因素回归:
第一种,all (kitchen sink regression):包括上述所以的变量。
第二种,ms (model selection):如果有k个变量,就会有 个随机的模型组合方式。在每个时期t,选出一个最好的模型——标准是OOS的预测误差最小(minimum OOS prediction errors)。
首先,将T个样本分为m个样本内数据和p个样本外数据;
其次,为了预测第m+1期的值,我们要用前m期共m-1个有效数据回归,得到系数α和β;
最后,代入第m期的解释变量求第m+1期的r;
然后,预测第m+2期的r,此时第m+ 1期的是所有真实数据都已知了,用前m+1期共m个有效数据回归,再得到系数α和β(与第一次的可能不同);代入第m+1期的解释变量求第m+2期的r;
重复以上过程,直到把q个样本外预测做完。
eN表示OOS与历史均值(无条件预测)之间的误差;eA表示OOS与OLS回归模型(条件预测)之间的误差。
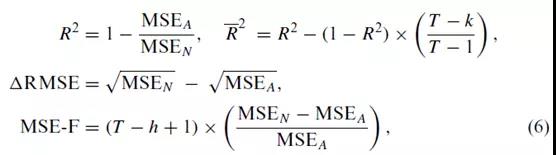
(1)大多数模型是不稳定的、甚至是虚假的。即使单个变量模型在某段时间内具有良好的样本外预测能力,这种预测能力也很难持续,比如经济结构不稳定或结构变化。
(2)到2005年末为止,大多数模型无论是在IS还是在OOS中都丧失了统计显著性。在OOS中,大多数模型不仅不能在统计意义上或经济意义上打败无条件基准水平(历史均值),而且表现的还不如它。如果我们把目光集中在1975年以后的时间里,我们会发现,没有哪一个模型在OOS中有突出的表现,而且也几乎没有可接受的IS显著水平。
(3)当我们把视角从研究者转向为投资者时,我们相信有证据表明这些模型并不能给今天的投资提供支持或建议。
2. Out of sample equity premium prediction: Combination Forecasts and Links to the Real Economy
Rapach et al(2009)改进了模型的组合方式,发现当对不同的模型预测结果进行一定的组合时,其组合收益可以稳定地超越历史平均水平,也就是说,组合后的模型显示了较好的预测能力。
将15个单变量回归模型预测值的某种平均值作为最终的预测值,即combination.
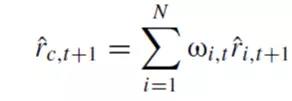
有两大类确定权重的方法:
The first class uses simple averaging schemes: mean, median, and trimmed mean
以第t+1期的预测值为例,最终的预测值为①15个模型预测值的简单平均;②15个预测值的中位数作为最终预测值;③15个预测值排序,掐头去尾,剩下13个取简单平均值(简单了理解为剔除个别不好的回归模型所产生的“异常值”)
The second class of combining methods uses the combining weights formed at time t as functions of the historical forecasting performance of the individual models over the holdout out-of-sample period。一言以蔽之:“重用”预测能力好的模型。
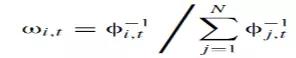
如果某个回归模型的预测误差的平方较小(倒数或精度越高),则表明模型预测性较好,应该在下一期的预测值上赋予更大的权重。
下图表示历史平均预测模型的MSPE减组合预测模型的MSPE 的差值。可以看到组合预测的表现始终好于历史平均预测,而且下图的实线显著的规避了频繁、大量的波动,说明组合预测比单个预测更有效。虚线表示给组合预测模型附加理论约束后的修正,发现变动不明显,说明组合预测模型本身就已满足这些理论约束条件。
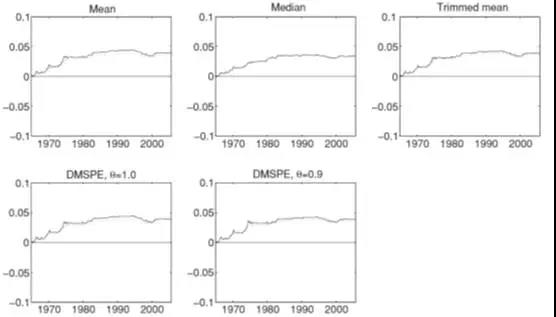
下图实线描述了单个预测回归模型在1965.1-2005.1的样本外预测值,虚线描述了历史平均预测模型的预测值,右下角的图描述的是组合预测模型的样本外预测值(采用的是mean combining method)。单个预测模型的样本外预测值波动比较大,包含大量噪音,给出错误信号,影响预测质量。而mean组合预测的样本外预测值比较稳定,但也呈现出比较合理的波动。
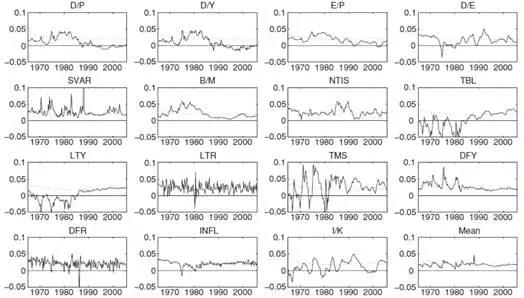
组合预测法在捕捉一系列经济变量的信息与避免过度的波动之间达到了一个平衡状态,即既不像单个指标预测时那样过度波动,也不像历史平均值法那样过渡平滑(无法与经济周期联系)。因此组合预测法在一定程度上可以获得超过历史平均的超额收益。




