1. 朴素贝叶斯算法
朴素贝叶斯分类器的主要思路:通过联合概率P(x,y)=P(x|y)P(y)建模,运用贝叶斯定理求解后验概率P(y|x);将后验概率最大者对应的的类别作为预测类别。
分类方法

为什么要选择后验概率最大的类别作为预测类别呢?因为后验概率最大化,可以使得期望风险最小化。
极大似然估计
在朴素贝叶斯学习中,需要估计先验概率与条件概率,一般时采用极大似然估计。先验概率的极大似然估计:

贝叶斯估计
在估计先验概率与条件概率时,有可能出现为0的情况,则计算得到的后验概率亦为0,从而影响分类的效果。因此,需要在估计时做平滑,这种方法被称为贝叶斯估计(Bayesian estimation)。先验概率的贝叶斯估计:
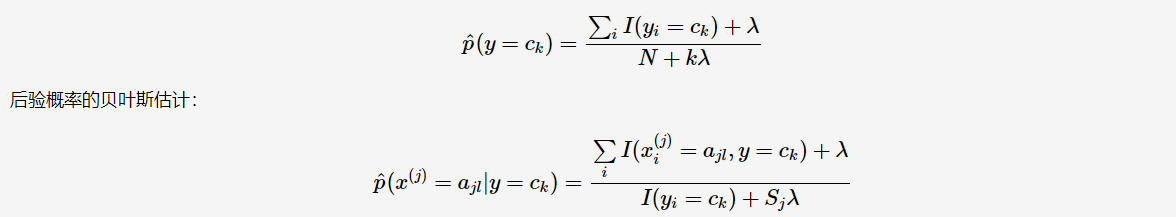
常取λ=1λ=1,这时被称为Laplace平滑(Laplace smoothing)。下面提到的拼写检查则用到了Laplace平滑——初始时将所有单词的计数置为1。
2. 拼写检查
当用户在输入拼写错误单词时,如何返回他想输入的拼写正确单词。比如,用户输入单词thew,用户有到底是想输入the,还是想输入thaw?这种拼写检查的问题等同于分类问题:在许多可能拼写正确单词中,到底哪一个时最有可能的呢?大神Peter Norvig [2]采用朴素贝叶斯解决这个拼写问题。
朴素贝叶斯分类

存在问题
Norvig所介绍的拼写检查是非常简单的一种,他在博文[2]中指出不足。此外,还有一些需要优化的地方:
上下文关联,比如输入thew,在不同的上下文中可能返回的拼写正确单词不同;
输入媒介,比如用户用键盘输入与用手机的九宫格输入,其拼写错误的方式时不一样的。




