本文讨论的kNN算法是监督学习中分类方法的一种。所谓监督学习与非监督学习,是指训练数据是否有标注类别,若有则为监督学习,若否则为非监督学习。监督学习是根据输入数据(训练数据)学习一个模型,能对后来的输入做预测。在监督学习中,输入变量与输出变量可以是连续的,也可以是离散的。若输入变量与输出变量均为连续变量,则称为回归;输出变量为有限个离散变量,则称为分类;输入变量与输出变量均为变量序列,则称为标注[2]。
kNN算法
kNN算法的核心思想非常简单:在训练集中选取离输入的数据点最近的k个邻居,根据这个k个邻居中出现次数最多的类别(最大表决规则),作为该数据点的类别。
算法描述
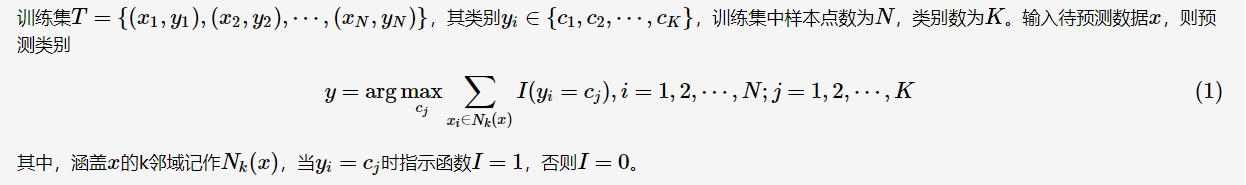

存在问题
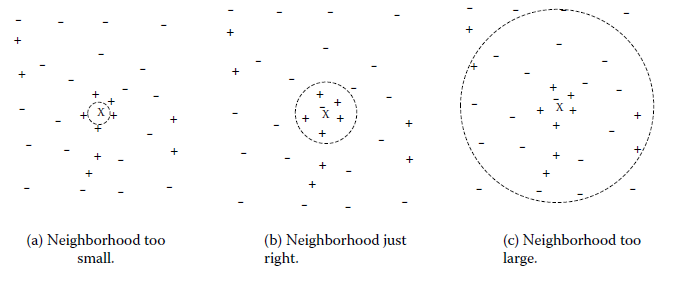
k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音样本点的减少;但是距离较远的训练样本点对预测结果会有贡献,以至于造成预测结果错误。下图给出k值的选取对于预测结果的影响: