decision stump,决策树桩(我称它为一刀切),也称单层决策树,单层也就意味着尽可能对每一列属性进行一次判断。如下图所示(仅对 petal length 进行了判断):
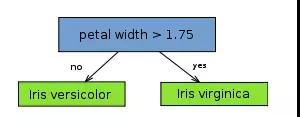
从树(数据结构)的观点来看,它由一个内部节点(internal node)也即根节点(root)与终端节点(terminal node)也即叶子节点(leaves)直接相连。用作分类器(classifier)的 decision stump 的叶子节点也就意味着最终的分类结果。
从实际意义来看,decision stump 根据一个属性的一个判断就决定了最终的分类结果,比如根据水果是否是圆形来判断水果是否为苹果,这体现的是单一简单的规则(或叫特征)在起作用。显然 decision stump 仅可作为一个 weak base learning algorithm(它会比瞎猜 1/2 稍好一点点,但好的程度十分有限),常用作集成学习中的 base algorithm,而不会单独作为分类器。
既然 decision stump 仅可对一个属性进行一次判断获取最终的分类结果,显然算法的目标是要寻找具有最低错误率的单层决策树。决策树桩,可以说是最简单的分类器了,它的分类原理很简单:1、决定一个阈值。2、大于这个阈值的是第一类,小于这个阈值的是第二类。(等于阈值的情况任意取舍即可)。决策树桩能解决的问题很有限,但是也并不是全无用途。例如我们对如下数据进行分类:
数据:5个拉拉队员的数据
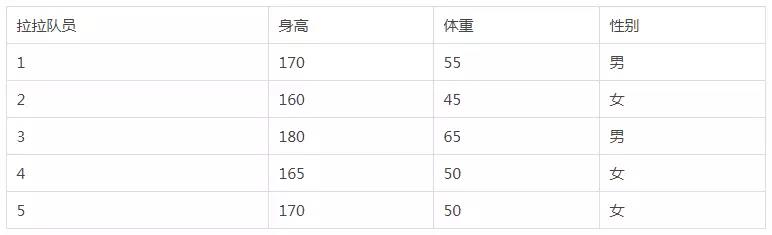
如果说我们想根据拉拉队员的身高体重对其性别进行分类,那么很明显,体重大于50的都是男队员,小于或等于50的都是女队员。因此决策树桩是完全可以解决这个问题的,那么剩下的工作就是如何让机器根据这些数据自己学习到合适的阈值。为此我们将问题更加细化一下,我们使用体重作为特征(X),性别作为标签进行分类(Y = 1 判断性别为男,Y = 0判断为女)。决策树桩的模型是一个一维的线性模型,因此其模型函数可以看做是 f(x) = (x – t), 其中t是阈值,我们规定,当f(x)>0时, 预测Y = 1,否则,预测Y = 0。
首先,C4.5是决策树算法的一种。决策树算法作为一种分类算法,目标就是将具有p维特征的n个样本分到c个类别中去。相当于做一个投影,c=f(n),将样本经过一种变换赋予一种类别标签。决策树为了达到这一目的,可以把分类的过程表示成一棵树,每次通过选择一个特征pi来进行分叉。那么怎样选择分叉的特征呢?每一次分叉选择哪个特征对样本进行划分可以最快最准确的对样本分类呢?不同的决策树算法有着不同的特征选择方案。C4.5用信息增益率。

下面进行举例介绍:
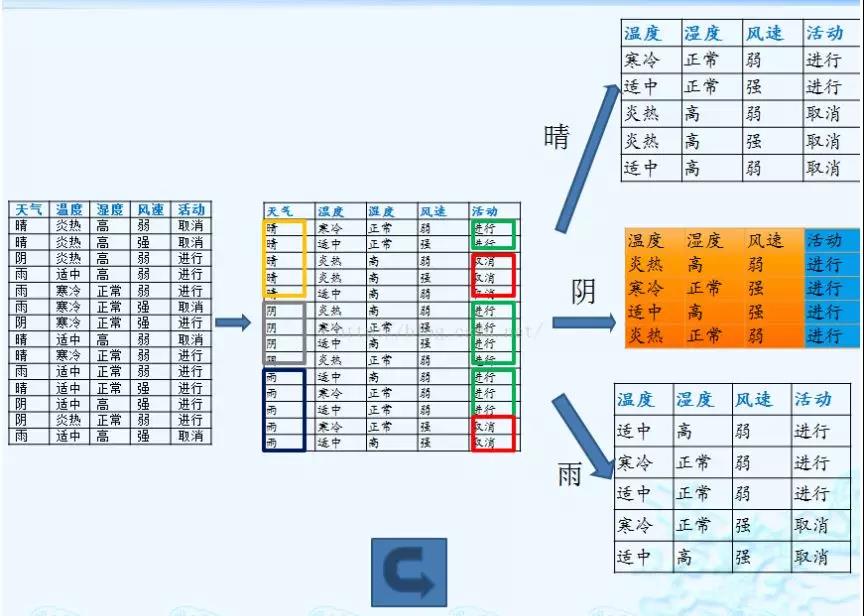
上述数据集有四个属性,属性集合A={ 天气,温度,湿度,风速}, 类别标签有两个,类别集合L={进行,取消}。
1. 计算类别信息熵
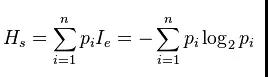
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越大,不确定性就越大,把事情搞清楚所需要的信息量就越多。

计算过程是按照信息熵的计算公式的,总样本数为14,类别标签只有两种,一种是进行,共9个样本,一种是取消,共5个样本,因此,P1=9/14,P2=5/14,之后直接套公式就可以了。
2. 计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示这个属性中拥有的样本类别越不“纯”。划分信息熵与类别信息熵的计算公式不同,详见《数据挖掘与机器学习WEKA应用技术与实践第二版》P68页。

3. 计算信息增益
信息增益的 = 熵 - 条件熵,在这里就是 类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果一个属性的信息增益越大,就表示用这个属性进行样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类目标。

4.计算属性分裂信息度量
用分裂信息度量来考虑某种属性进行分裂时分支的数量信息和尺寸信息,我们把这些信息称为属性的内在信息(instrisic information)。信息增益率用信息增益 / 内在信息,会导致属性的重要性随着内在信息的增大而减小(也就是说,如果这个属性本身不确定性就很大,那我就越不倾向于选取它),这样算是对单纯用信息增益有所补偿。

5. 计算信息增益率
(下面写错了。。应该是IGR = Gain / H )

天气的信息增益率最高,选择天气为分裂属性。发现分裂了之后,天气是“阴”的条件下,类别是”纯“的,所以把它定义为叶子节点,选择不“纯”的结点继续分裂。在子结点当中重复过程1~5。后续重复细节参考给出的文献链接,或参考《数据挖掘与机器学习WEKA应用技术与实践第二版》P68-70。分类的预测输出是离散型类别值,而回归的预测输出是连续型的数值,而C4.5只能处理分类问题,也就是只能处理预测输出是离散型的类别值或叫标称属性值。
相关推荐:




