在描述贝叶斯定理怎样应用于分类之前,我们先从统计学的角度对分类问题加以形式化。设X表示特征属性集,Y表示类变量。如果类变量和属性之间的关系不确定,那么我们可以把X和Y看作随机变量,用P(Y|X)以概率的方式捕捉二者之间的关系。这个条件概率又称为Y的后验概率,与之相对地,P(Y)称为Y的先验概率)。
在训练阶段,我们要根据从训练数据中收集的信息,对X和Y的每一种组合学习后验概率P(Y|X),即在样本特征属性已知的情况下,通过算得不同分类下的后验概率,来找出使后验概率P(Y′|X′)最大的类Y′来对测试记录X′进行分类。
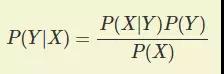
在比较不同Y值下的后验概率时,分母P(X)总是常数,因此可以忽略。先验概率P(Y)可以通过计算训练集中属于每个类的训练记录所占的比例进行估计。对类条件概率P(X|Y)的估计,则有两种实现方法:[朴素贝叶斯分类器]和[贝叶斯信念网络],本篇讲解朴素贝叶斯分类器。
朴素贝叶斯的思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。了对p(x|y)建模,算法做一个假设,称为朴素贝叶斯假设,由朴素贝叶斯假设推导出的分类器叫做朴素贝叶斯分类器。朴素贝叶斯假设是:假设给定分类y后,特征向量中的各个分量xi是条件**的。尽管该假设在现实中不是很成立,但在不大幅降低分类精度的情况下,有助于简化运算。


又被称为加1平滑,是比较常用的平滑方法。平滑方法的存在是为了解决零概率问题。零概率问题,就是在计算实例被分到某类的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致实例的分类概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,在某分类下该词语出现的条件概率为0,在朴素贝叶斯算法中为了计算后验概率p(x|y),其基于各属性相互**的假设,会使用连乘来计算出实例分类概率为0。这是不合理的。假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
本文以经典的天气分类问题举例,生动展示了新的一天天气属性数据到来的时候,基于贝叶斯算法,play是yes还是no。
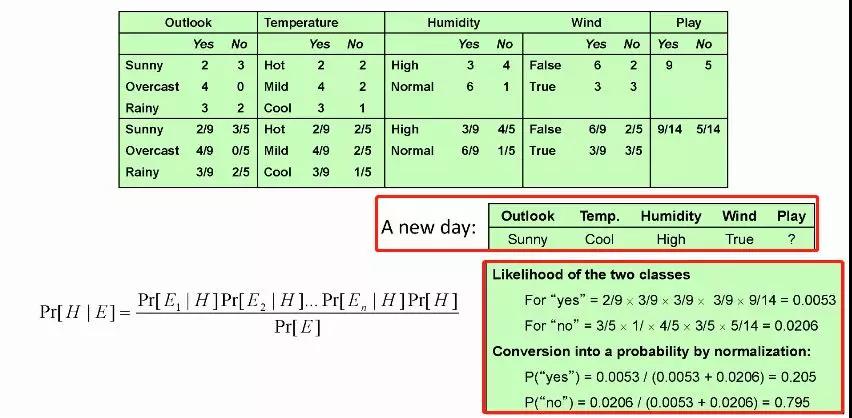
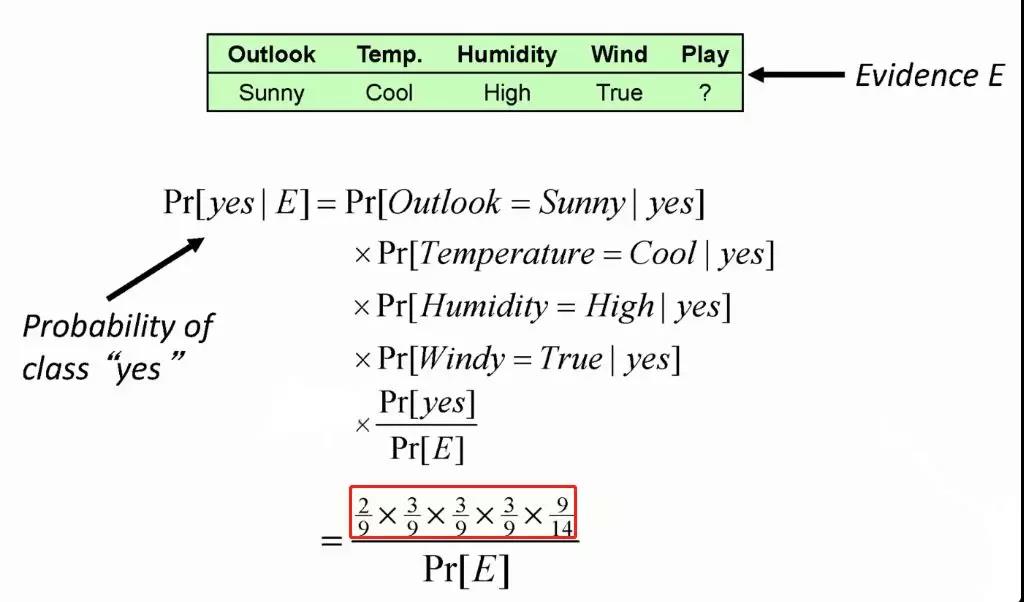
相关推荐:




