基于规则的分类器是使用一组"if...then..."规则来对记录进行分类的技术。规则学习算法使用了一种称为**而治之的探索法。这个过程包括确定训练数据中覆盖一个案例子集的规则,然后再从剩余的数据中分离出该分区。随着规则的增加,更多的数据子集会被分离,直到整个数据集都被覆盖,不再有案例残留。
**而治之和决策树的分而治之区别很小,决策树的每个决策节点会受到过去决策历史的影响,而规则学习不存在这样的沿袭。随着规则的增加,更多的数据子集会被分离,直到整个数据集都被覆盖,不再有案例被保留。模型的规则用析取范式 R =(r1 ∨ r2 ∨ ••• ∨ rk)表示,其中R称作规则集,ri 是分类规则或析取项。每一个分类规则可以表示为如下形式:
ri:(条件i)→yi
规则左边成为规则前件或前提。它是属性测试的合取:
条件i=(A1 op v1)∧(A1 op v1)∧•••∧(A1 op v1)
其中(Aj,vj)是属性-值对,op是比较运算符,取自集合{=,≠,﹤,﹥,≦,≧}。每一个属性测试(Aj op vj)称为一个合取项。规则右边称为规则后件,包含预测类yi。如果规则r的前件和记录x的属性匹配,则称r覆盖x。当r覆盖给定的记录时,称r被激发或触发。

基于规则的分类器有如下特点:规则集的表达能力几乎等价于决策树,与决策树一样可以用互斥和穷举的规则集来表示。基于规则分类器和决策树分类器都对属性空间进行直线划分,并将类指派到每个划分。基于规则的分类器通常被用来产生更易于解释的描述性模型,而模型的性能却可与决策树分类器相媲美。
如何建立基于规则的分类器(以RIPPER算法为例)
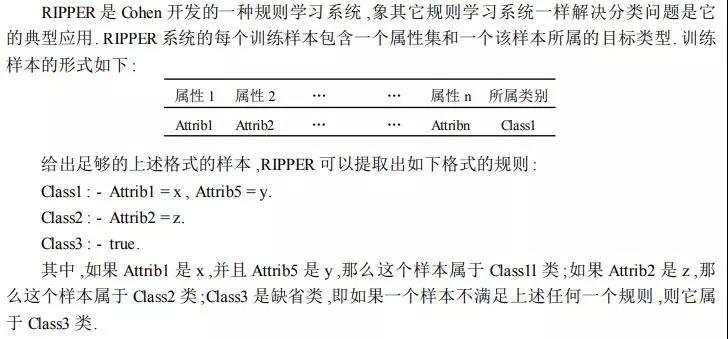
为了建立基于规则的分类器,需要提取一组规则来识别数据集的属性和类标号之间的关键联系。一般采取直接方法,直接从数据中提取分类规则,直接方法把属性空间分为较小的子空间,以便于属于一个子空间的所有记录可以使用一个分类规则进行分类。
目标是提取一个分类规则,该规则覆盖训练集中的大量正例,没有或仅覆盖少量反例。然而,由于搜索空间呈指数大小,要找到一个最佳的规则的计算开销很大。通过以一种贪心的方式来增长规则以解决指数搜索问题。它产生一个初始规则r,并不断对该规则求精,直到满足某种终止条件为止。然后修剪该规则,以改进它的泛化误差。
RIPPER算法使用从一般到特殊的策略进行规则增长,在从一般到特殊的策略中,先建立一个初始规则r:{}→y,其中左边是一个空集,右边包含目标类。该规则的质量很差,因为它覆盖训练集中的所有样例。接着加入新的合取项来提高规则的质量,直到满足终止条件为止(例如,加入的合取项已不能提高规则的质量)。
对两类问题,RIPPER算法选择以多数类作为默认类,并为预测少数类学习规则。对于多类问题,先按类的频率对类进行排序,设(y1,y2,…,yc)是排序后的类,其中y1是最不频繁的类,yc是最频繁的类。第一次迭代中,把属于y1的样例标记为正例,而把其他类的样例标记为反例,使用顺序覆盖算法产生区分正例和反例的规则。接下来,RIPPER提取区分y2和其他类的规则。重复该过程,直到剩下类yc,此时yc作为默认类。充分体现**而治之的思想。
由于规则以贪心的方式增长,以上方法可能会产生次优规则。为了避免这种问题,可以采用束状搜索(beam search)。算法维护k个最佳候选规则,各候选规则各自在其前件中添加或删除合取项而**地增长。评估候选规则的质量,选出k个最佳候选进入下一轮迭代。
在规则的增长过程中,需要一种评估度量来确定应该添加(或删除)哪个合取项。准确率就是一个很明显的选择,因为它明确地给出了被规则正确分类的训练样例的比例。FOIL信息增益度:规则的支持度计数对应于它所覆盖的正例数。假设规则r : A→+覆盖p0个正例和n0个反例。增加新的合取项B,扩展后的规则r' : A∧B→+覆盖p1个正例和n1个反例。根据以上信息,扩展后规则的FOIL信息增益定义为:
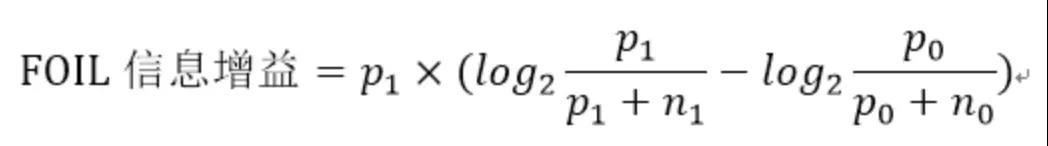
由于该度量与p1和p1/p1+n1成正比,因此它更倾向于选择那些高支持度计数和高准确率的规则。RIPPER算法使用FOIL信息增益来选择最佳合取项添加到规则前件中。当规则开始覆盖反例时,停止添加合取项。
新规则根据其在确认集上的性能进行减枝。计算下面的度量来确定规则是否需要减枝:(p-n)/(p+n),其中p和n分别是被规则覆盖的确认集中的正例和反例数目,关于规则在确认集上的准确率,该度量是单调的。如果减枝后该度量增加,那么就去掉该合取项。减枝是从最后添加的合取项开始的。例如给定规则ABCD→y,RIPPER算法先检查D是否应该减枝,然后是CD、BCD等。尽管原来的规则仅覆盖正例,但是减枝后的规则可能会覆盖训练集中的一些反例。
RIPPER算法原理简要:可以笼统的理解为一个三步过程:生长,修剪,优化,生长过程利用**而治之技术,对规则贪婪地添加条件,直到该规则能完全划分出一个数据子集或者没有属性用于分割。与决策树类似,信息增益准则可用于确定下一个分割的属性,当增加一个特指的规则而熵值不再减少时,该规则需要立即修剪。重复第一步和第二步,直到达到一个停止准则,然后,使用各种探索法对整套的规则进行优化。
相关推荐:




