鸢尾花数据集共收集了三类鸢尾花,即Setosa鸢尾花、Versicolour鸢尾花和Virginica鸢尾花,每一类鸢尾花收集了50条样本记录,共计150条。
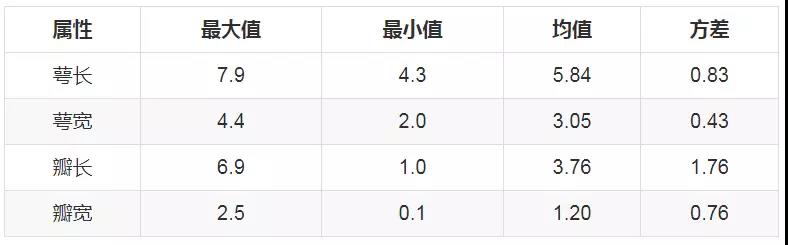
数据集包括4个属性,分别为花萼的长、花萼的宽、花瓣的长和花瓣的宽。四个属性的单位都是cm,属于数值变量,四个属性均不存在缺失值的情况,以下是各属性的一些统计值如下:
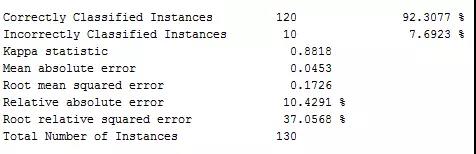
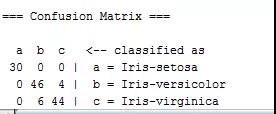
小编使用随机森林算法对切分后的训练数据集建立分类模型,采用十折交叉检验,下面给出模型分类准确度的相关指标及混淆矩阵图,随机森林算法对鸢尾花130个样本的训练集建模,分类准确度为92.31%。但是对versicolor鸢尾花及virginica鸢尾花的分类结果稍差,一定程度也说明这两类花较不易区分,至于随机森林算法的理论及实验细节就不做过多解释了,写起来太长太冗。
小编采用基于训练集得到的分类模型,对未知类别的鸢尾花数据进行预测(假设不知其类),小编截出模型对3个样本的预测结果,并将该结果转换为CSV的格式,以利于分析展示。


predictedclass就是我们要取得的预测结果。后面的「entropy」是我计算各概率分布的Entropy乱度,乱度数据越高,分类准确性越低,0是最准确的数字。其他以「pro_dis」开头的栏位是概率分布,表示这个案例被分类在某一种分类的可能性。算法会选择概率分布最高的那一个分类作为predictedclass的結果。
随机森林算法是集成学习算法,综合了多个基础分类器或叫弱分类器的分类结果,通过观察概率分布,可以让我们以更大的把握判断该预测结果是否更合理准确,随机森林算法大多是黑箱算法,通常很难解释和充分理解,不像决策树或基于规则的学习器可以明确地得到相应的模型结果,为此,通过概率分布一探随机森林中基础分类器的处理细节就极为重要,而不仅仅是要个预测结果那么简单,要知即使是同样的预测结果也是有不小差异的。
相关推荐:




