特征提取步骤
1.1 统计样本集中文档总数(N)。
1.2 统计每个词的正文档出现频率(A)、负文档出现频率(B)、正文档不出现频率)、负文档不出现频率。
1.3 计算每个词的卡方值,公式如下:
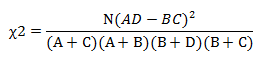
1.4 将每个词按卡方值从大到小排序,选取前k个词作为特征,k即特征维数。
1.5 进一步化简,注意如果给定了一个文档集合(例如我们的训练集)和一个类别,则N,M,N-M(即A+C和B+D)对同一类别文档中的所有词来说都是一样的,而我们只关心一堆词对某个类别的开方值的大小顺序,而并不关心具体的值,因此把它们去掉是完全可以的,故实际计算的时候我们都使用
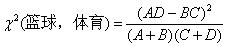
2.1 统计正负分类的文档数:N1、N2。
2.2 统计每个词的正文档出现频率(A)、负文档出现频率(B)、正文档不出现频率)、负文档不出现频率。
2.3 计算信息熵
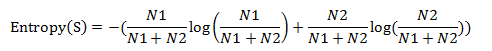
2.4 计算每个词的信息增益
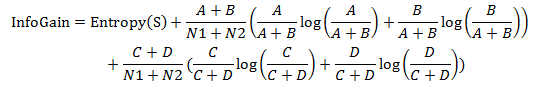
2.5 将每个词按信息增益值从大到小排序,选取前k个词作为特征,k即特征维数。
部分代码展示

文件预览
 1人赞赏收藏
1人赞赏收藏