问题一:以分类问题为例,如何评估不同分类器的优劣,如C4.5、SVM、逻辑回归、随机森林等,解决办法是找到一个参照物,或叫基线准确度Baseline accuracy,基线准确度通过ZeroR算法得到。有了参照物,我们就可以对比不同分类器,相比基线准确度是更好还是更差,显著性如何等。
ZeroR分类器是一种最简单的分类器,这种方法仅仅根据历史数据统计规律,而选择一种概率最大的类别作为未知样本的分类结果,也就是说对于任意一个未知样本,分类结果都是一样的。ZeroR分类器简单的以多数类的类别(连续型数据使用简单均值)作为预测值。尽管这种分类器没有任何的预测能力,但是它可以作为一种与其他分类器的对比分类器。也就是说baseline performance。
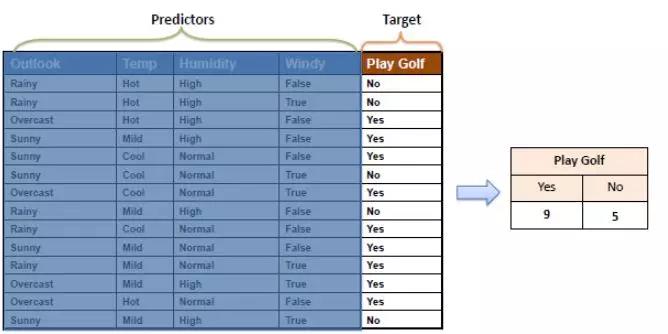
属性值也就是上面的预测指标(predictors)对于模型来说毫无贡献度。这是因为ZeroR根本就没有使用它们。ZeroR会选择一个频率最大的分类值作为模型的预测输出,对于数据集来说“Play Golf =Yes” 是ZeroR模型,精度为:0.64,这就是基线准确度。在使用ZeroR算法得到基线准确度时,应让训练集与测试集一致,以得到纯粹的基线准确度。
问题二:如何对模型进行性能评估,可以尽可能地避免过拟合及欠拟合问题?特别不建议训练集和测试集是同一数据集合,因为对于我们得到的预测分类准确度的相关信息,其可信度很低。一般采取方式是进行样本外检验,通过将数据集切分为训练集(66%)及测试集(34%)两部分。当然还有更好的方法,下面将着重介绍该方法——K-fold Cross Validation(K折交叉验证),其是评估机器学习算法性能的标准方法。
其将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
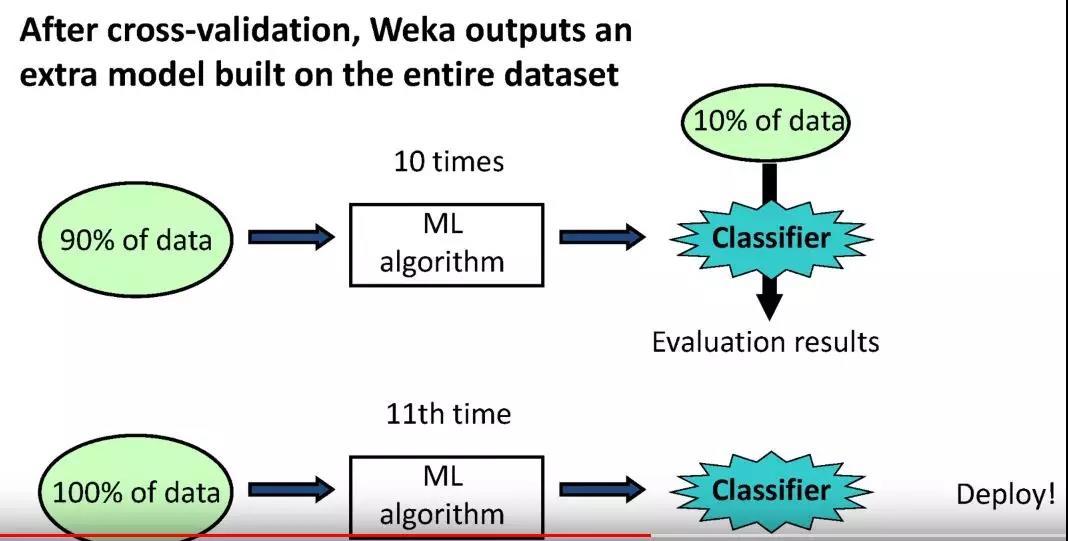
当然我们也可以通过多次改变随机种子,来得到多次不同的K折交叉验证下的分类准确度,之后取均值及标准差,得到分类准确度的置信区间。


Holdout为重复预留法,10-fold cross-validation为10折交叉验证,从中我们看到,在均值基本一致的情况下,10折交叉验证的标准差远远小于重复预留法,优劣高低立现,10-fold cross-validation较好。
相关推荐:




