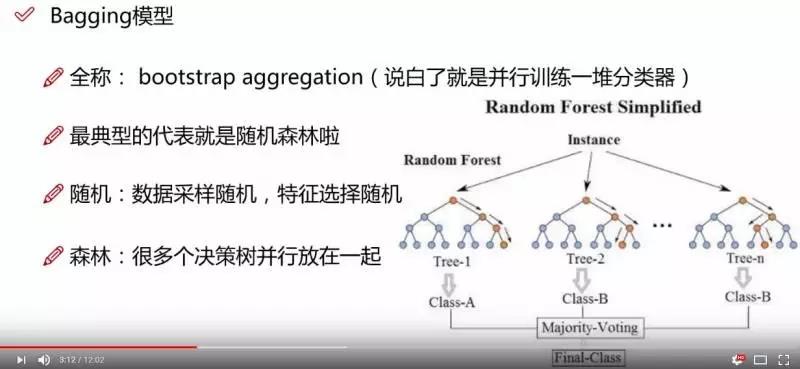
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想--集成思想的体现。“随机”的含义我们会在下边部分讲到。

其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
引用香农的话来说,信息是用来消除随机不确定性的东西。当然这句话虽然经典,但是还是很难去搞明白这种东西到底是个什么样,可能在不同的地方来说,指的东西又不一样。对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义如下:
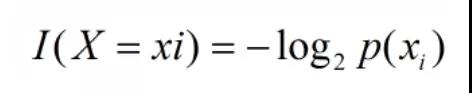
I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率。
熵是用来度量不确定性的,当熵越大,X=xi的不确定性越大,反之越小。对于机器学习中的分类问题而言,熵越大即这个类别的不确定性更大,反之越小。通过画出上述数学公式的曲线图(定义域介于0到1)还是很好理解熵的变化过程的,当p(xi)越大即某类别出现概率越大的时候,确定性越高,熵值越小,反之p(xi)越小即某类别出现概率越小的时候,确定性越低,熵值越大。


bagging即是bootstrap aggregation,Bootstraping的名称来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法."拔靴法": 从手上有限的资料, 产生不同的副本, 来模拟不一样的资料。为什么要随机抽样训练集?如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
为什么要有放回地抽样?我的理解是这样的:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的"(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
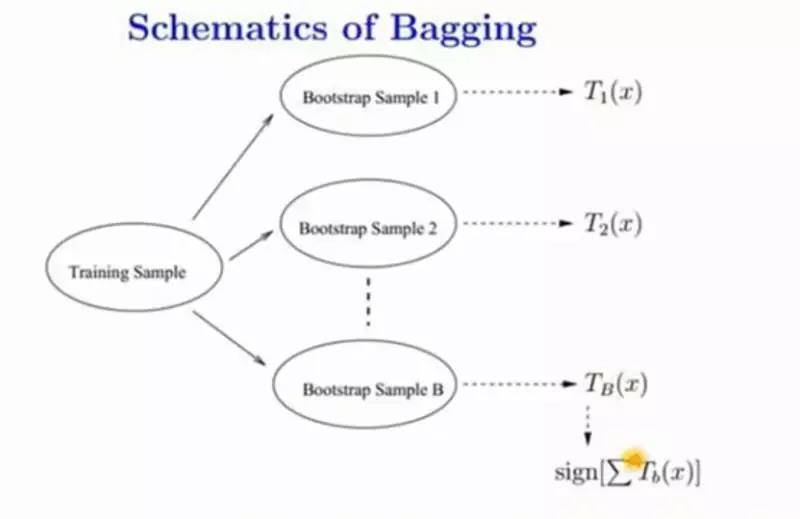
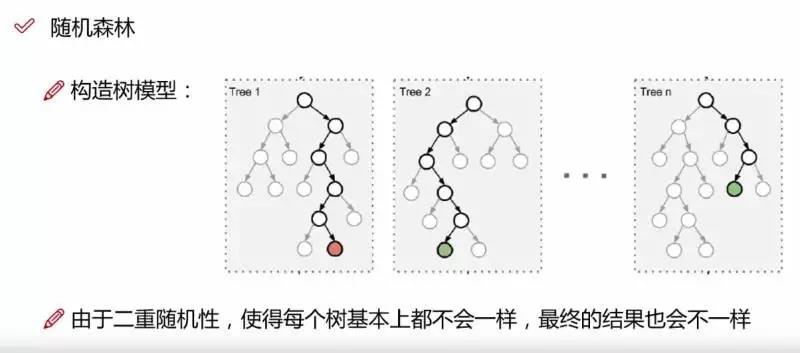
1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
2)如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
3)每棵树都尽最大程度的生长,并且没有剪枝过程。
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
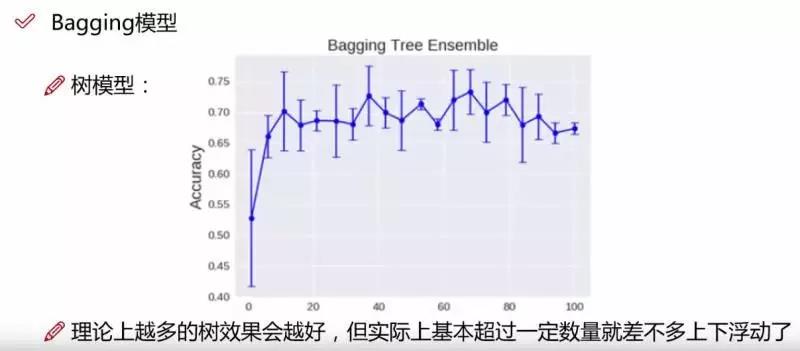
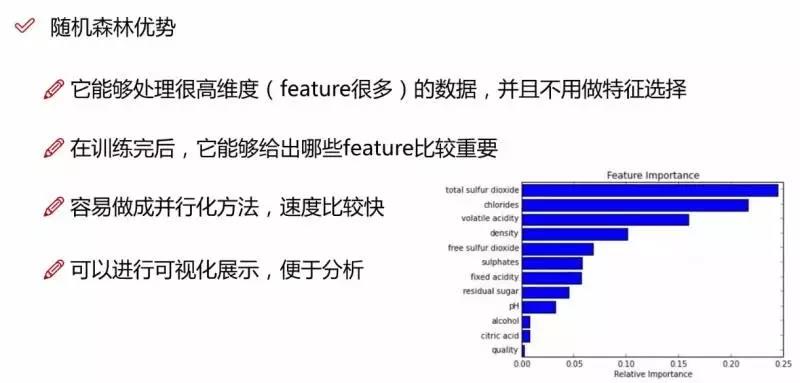
上面我们提到,构建随机森林的关键问题就是如何选择最优的m,要解决这个问题主要依据计算袋外错误率oob error(out-of-bag error)。随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个**的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。 而这样的采样特点就允许我们进行oob估计,它的计算方式如下:(note:以样本为单位)
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
相关推荐:




