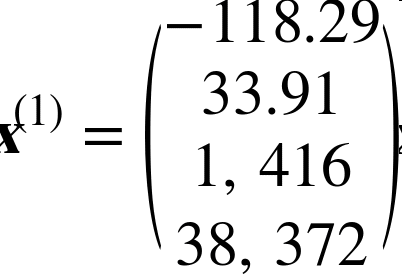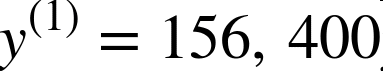第2章 一个完整的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目。下面是主要步骤:
项目概述。
获取数据。
发现并可视化数据,发现规律。
为机器学习算法准备数据。
选择模型,进行训练。
微调模型。
给出解决方案。
部署、监控、维护系统。
使用真实数据
学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的地方:
流行的开源数据仓库:
UC Irvine Machine Learning Repository
Kaggle datasets
Amazon’s AWS datasets
准入口(提供开源数据列表)
http://dataportals.org/
http://opendatamonitor.eu/
http://quandl.com/
其它列出流行开源数据仓库的网页:
Wikipedia’s list of Machine Learning datasets
Quora.com question
Datasets subreddit
本章,我们选择的是 StatLib 的加州房产价格数据集(见图 2-1)。这个数据集是基于 1990 年加州普查的数据。数据已经有点老(1990 年还能买一个湾区不错的房子),但是它有许多优点,利于学习,所以假设这个数据为最近的。为了便于教学,我们添加了一个类别属性,并除去了一些。
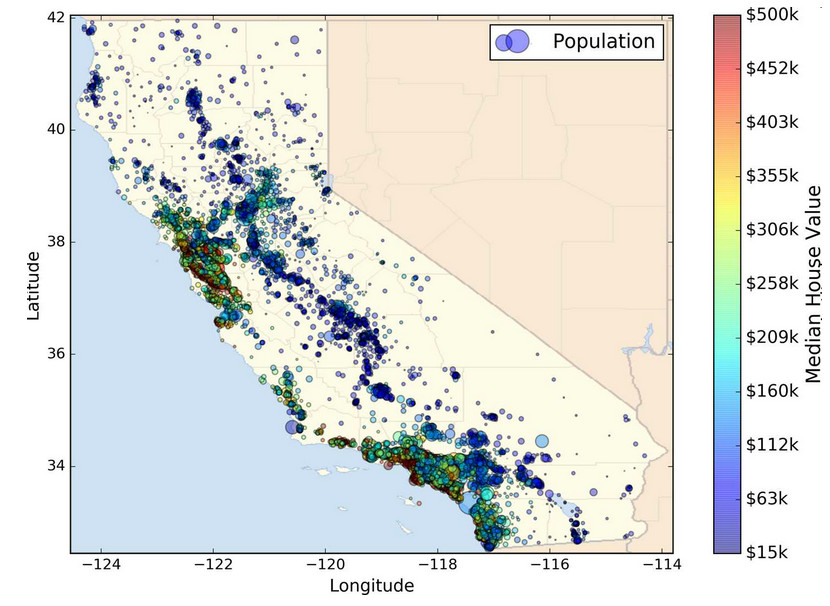
图 2-1 加州房产价格
项目概览
欢迎来到机器学习房地产公司!你的第一个任务是利用加州普查数据,建立一个加州房价模型。这个数据包含每个街区组的人口、收入中位数、房价中位数等指标。街区组是美国调查局发布样本数据的最小地理单位(一个街区通常有 600 到 3000 人)。我们将其简称为“街区”。
你的模型要利用这个数据进行学习,然后根据其它指标,预测任何街区的的房价中位数。
提示:你是一个有条理的数据科学家,你要做的第一件事是拿出你的机器学习项目清单。你可以使用附录 B 中的清单;这个清单适用于大多数的机器学习项目,但是你还是要确认它是否满足需求。在本章中,我们会检查许多清单上的项目,但是也会跳过一些简单的,有些会在后面的章节再讨论。
划定问题
问老板的第一个问题应该是商业目标是什么?建立模型可能不是最终目标。公司要如何使用、并从模型受益?这非常重要,因为它决定了如何划定问题,要选择什么算法,评估模型性能的指标是什么,要花多少精力进行微调。
老板告诉你你的模型的输出(一个区的房价中位数)会传给另一个机器学习系统(见图 2-2),也有其它信号会传入后面的系统。这一整套系统可以确定某个区进行投资值不值。确定值不值得投资非常重要,它直接影响利润。
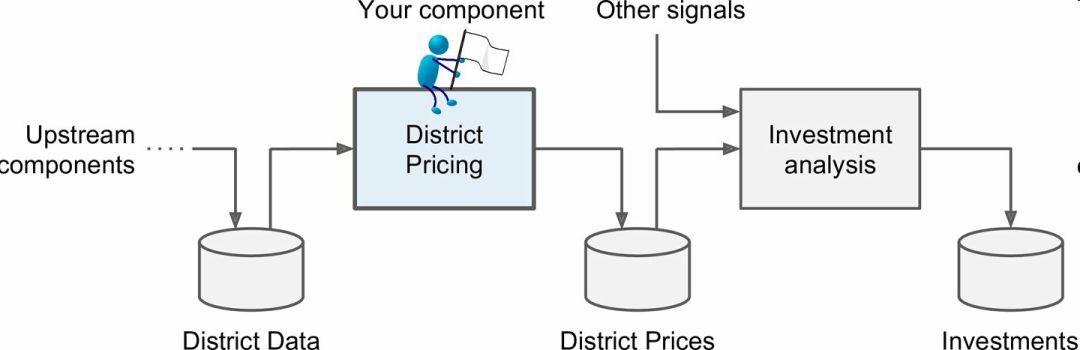
图 2-2 房地产投资的机器学习流水线
流水线
一系列的数据处理组件被称为数据流水线。流水线在机器学习系统中很常见,因为有许多数据要处理和转换。
组件通常是异步运行的。每个组件吸纳进大量数据,进行处理,然后将数据传输到另一个数据容器中,而后流水线中的另一个组件收入这个数据,然后输出,这个过程依次进行下去。每个组件都是**的:组件间的接口只是数据容器。这样可以让系统更便于理解(记住数据流的图),不同的项目组可以关注于不同的组件。进而,如果一个组件失效了,下游的组件使用失效组件最后生产的数据,通常可以正常运行(一段时间)。这样就使整个架构相当健壮。
另一方面,如果没有监控,失效的组件会在不被注意的情况下运行一段时间。数据会受到污染,整个系统的性能就会下降。
下一个要问的问题是,现在的解决方案效果如何。老板通常会给一个参考性能,以及如何解决问题。老板说,现在街区的房价是靠专家手工估计的,专家队伍收集最新的关于一个区的信息(不包括房价中位数),他们使用复杂的规则进行估计。这种方法费钱费时间,而且估计结果不理想,误差率大概有 15%。
OK,有了这些信息,你就可以开始设计系统了。首先,你需要划定问题:监督或非监督,还是强化学习?这是个分类任务、回归任务,还是其它的?要使用批量学习还是线上学习?继续阅读之前,请暂停一下,尝试自己回答下这些问题。
你能回答出来吗?一起看下答案:很明显,这是一个典型的监督学习任务,因为你要使用的是有标签的训练样本(每个实例都有预定的产出,即街区的房价中位数)。并且,这是一个典型的回归任务,因为你要预测一个值。讲的更细些,这是一个多变量回归问题,因为系统要使用多个变量进行预测(要使用街区的人口,收入中位数等等)。在第一章中,你只是根据人均 GDP 来预测生活满意度,因此这是一个单变量回归问题。最后,没有连续的数据流进入系统,没有特别需求需要对数据变动作出快速适应。数据量不大可以放到内存中,因此批量学习就够了。
提示:如果数据量很大,你可以要么在多个服务器上对批量学习做拆分(使用 MapReduce 技术,后面会看到),或是使用线上学习。
选择性能指标
下一步是选择性能指标。回归问题的典型指标是均方根误差(RMSE)。均方根误差测量的是系统预测误差的标准差。例如,RMSE 等于 50000,意味着,68% 的系统预测值位于实际值的 $50000 以内,95% 的预测值位于实际值的 $100000 以内(一个特征通常都符合高斯分布,即满足 “68-95-99.7”规则:大约68%的值落在1σ内,95% 的值落在2σ内,99.7%的值落在3σ内,这里的σ等于50000)。公式 2-1 展示了计算 RMSE 的方法。
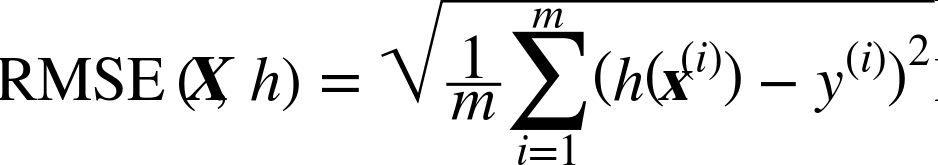
公式 2-1 均方根误差(RMSE)
符号的含义
这个方程引入了一些常见的贯穿本书的机器学习符号:
m是测量 RMSE 的数据集中的实例数量。
例如,如果用一个含有 2000 个街区的验证集求 RMSE,则m = 2000。$x^{(i)}$ 是数据集第
i个实例的所有特征值(不包含标签)的向量,$y^{(i)}$ 是它的标签(这个实例的输出值)。例如,如果数据集中的第一个街区位于经度 –118.29°,纬度 33.91°,有 1416 名居民,收入中位数是 $38372,房价中位数是 $156400(忽略掉其它的特征),则有:
和,
X是包含数据集中所有实例的所有特征值(不包含标签)的矩阵。每一行是一个实例,第i行是 $x^{(i)}$ 的转置,记为 $x^{(i)T}$。例如,仍然是前面提到的第一区,矩阵
X就是:
h是系统的预测函数,也称为假设(hypothesis)。当系统收到一个实例的特征向量 $x^{(i)}$,就会输出这个实例的一个预测值 $\hat y^{(i)} = h(x^{(i)})$($\hat y$ 读作y-hat)。例如,如果系统预测第一区的房价中位数是 $158400,则 $\hat y^{(1)} = h(x^{(1)}) = 158400$。预测误差是 $\hat y^{(1)} – y^{(1)} = 2000$。
RMSE(X,h)是使用假设h在样本集上测量的损失函数。
我们使用小写斜体表示标量值(例如 $\it m$ 或 $\it{y^{(i)}}$)和函数名(例如 $\it h$),小写粗体表示向量(例如 $\bb{x^{(i)}}$),大写粗体表示矩阵(例如 $\bb{X}$)。
虽然大多数时候 RMSE 是回归任务可靠的性能指标,在有些情况下,你可能需要另外的函数。例如,假设存在许多异常的街区。此时,你可能需要使用平均绝对误差(Mean Absolute Error,也称作平均绝对偏差),见公式 2-2:
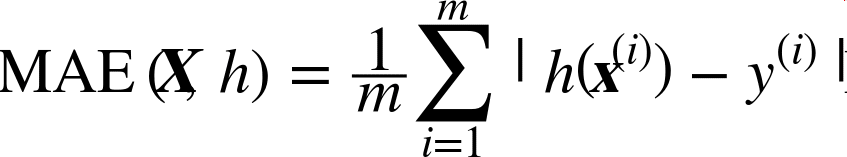
公式2-2 平均绝对误差
RMSE 和 MAE 都是测量预测值和目标值两个向量距离的方法。有多种测量距离的方法,或范数:
计算对应欧几里得范数的平方和的根(RMSE):这个距离介绍过。它也称作ℓ2范数,标记为 $| \cdot |_2$(或只是 $| \cdot |$)。
计算对应于ℓ1(标记为 $| \cdot |_1$)范数的绝对值和(MAE)。有时,也称其为曼哈顿范数,因为它测量了城市中的两点,沿着矩形的边行走的距离。
更一般的,包含n个元素的向量v的ℓk范数(K 阶闵氏范数),定义成
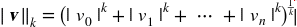
ℓ0(汉明范数)只显示了这个向量的基数(即,非零元素的个数),ℓ∞(切比雪夫范数)是向量中最大的绝对值。
范数的指数越高,就越关注大的值而忽略小的值。这就是为什么 RMSE 比 MAE 对异常值更敏感。但是当异常值是指数分布的(类似正态曲线),RMSE 就会表现很好。
核实假设
最后,最好列出并核对迄今(你或其他人)作出的假设,这样可以尽早发现严重的问题。例如,你的系统输出的街区房价,会传入到下游的机器学习系统,我们假设这些价格确实会被当做街区房价使用。但是如果下游系统实际上将价格转化成了分类(例如,便宜、中等、昂贵),然后使用这些分类,而不是使用价格。这样的话,获得准确的价格就不那么重要了,你只需要得到合适的分类。问题相应地就变成了一个分类问题,而不是回归任务。你可不想在一个回归系统上工作了数月,最后才发现真相。
幸运的是,在与下游系统主管探讨之后,你很确信他们需要的就是实际的价格,而不是分类。很好!整装待发,可以开始写代码了。
获取数据
开始动手。最后用 Jupyter notebook 完整地敲一遍示例代码。完整的代码位于 https://github.com/ageron/handson-ml。
创建工作空间
首先,你需要安装 Python。可能已经安装过了,没有的话,可以从官网下载 https://www.python.org/。
接下来,需要为你的机器学习代码和数据集创建工作空间目录。打开一个终端,输入以下命令(在提示符$之后):
$ export ML_PATH="$HOME/ml" # 可以更改路径
$ mkdir -p $ML_PATH
还需要一些 Python 模块:Jupyter、NumPy、Pandas、Matplotlib 和 Scikit-Learn。如果所有这些模块都已经在 Jupyter 中运行了,你可以直接跳到下一节“下载数据”。如果还没安装,有多种方法可以进行安装(包括它们的依赖)。你可以使用系统的包管理系统(比如 Ubuntu 上的apt-get,或 macOS 上的 MacPorts 或 HomeBrew),安装一个 Python 科学计算环境比如 Anaconda,使用 Anaconda 的包管理系统,或者使用 Python 自己的包管理器pip,它是 Python 安装包(自从 2.7.9 版本)自带的。可以用下面的命令检测是否安装pip:
$ pip3 --version
pip 9.0.1 from [...]/lib/python3.5/site-packages (python 3.5)
你需要保证pip是近期的版本,至少高于 1.4,以保障二进制模块文件的安装(也称为 wheel)。要升级pip,可以使用下面的命令:
$ pip3 install --upgrade pip
Collecting pip
[...]
Successfully installed pip-9.0.1
创建**环境
如果你希望在一个**环境中工作(强烈推荐这么做,不同项目的库的版本不会冲突),用下面的
pip命令安装virtualenv:$ pip3 install --user --upgrade virtualenv Collecting virtualenv [...] Successfully installed virtualenv
现在可以通过下面命令创建一个**的 Python 环境:
$ cd $ML_PATH $ virtualenv env Using base prefix '[...]' New python executable in [...]/ml/env/bin/python3.5 Also creating executable in [...]/ml/env/bin/python Installing setuptools, pip, wheel...done.
以后每次想要激活这个环境,只需打开一个终端然后输入:
$ cd $ML_PATH $ source env/bin/activate
启动该环境时,使用
pip安装的任何包都只安装于这个**环境中,Python 指挥访问这些包(如果你希望 Python 能访问系统的包,创建环境时要使用包选项--system-site)。更多信息,请查看virtualenv文档。
现在,你可以使用pip命令安装所有必需的模块和它们的依赖:
$ pip3 install --upgrade jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl
Collecting matplotlib
[...]
要检查安装,可以用下面的命令引入每个模块:
$ python3 -c "import jupyter, matplotlib, numpy, pandas, scipy, sklearn"
这个命令不应该有任何输出和错误。现在你可以用下面的命令打开 Jupyter:
$ jupyter notebook
[I 15:24 NotebookApp] Serving notebooks from local directory: [...]/ml
[I 15:24 NotebookApp] 0 active kernels
[I 15:24 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 15:24 NotebookApp] Use Control-C to stop this server and shut down all
kernels (twice to skip confirmation).
Jupyter 服务器现在运行在终端上,监听 888 8端口。你可以用浏览器打开http://localhost:8888/,以访问这个服务器(服务器启动时,通常就自动打开了)。你可以看到一个空的工作空间目录(如果按照先前的virtualenv步骤,只包含env目录)。
现在点击按钮 New 创建一个新的 Python 注本,选择合适的 Python 版本(见图 2-3)。
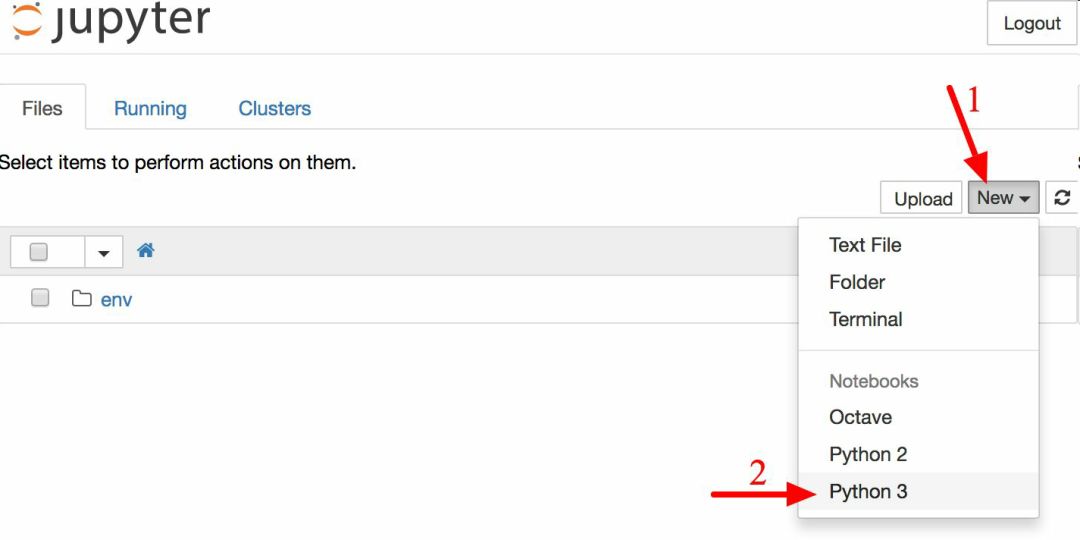
图 2-3 Jupyter 的工作空间
这一步做了三件事:首先,在工作空间中创建了一个新的 notebook 文件Untitled.ipynb;第二,它启动了一个 Jupyter 的 Python 内核来运行这个 notebook;第三,在一个新栏中打开这个 notebook。接下来,点击 Untitled,将这个 notebook 重命名为Housing(这会将ipynb文件自动命名为Housing.ipynb)。
notebook 包含一组代码框。每个代码框可以放入可执行代码或格式化文本。现在,notebook 只有一个空的代码框,标签是In [1]:。在框中输入print("Hello world!"),点击运行按钮(见图 2-4)或按Shift+Enter。这会将当前的代码框发送到 Python 内核,运行之后会返回输出。结果显示在代码框下方。由于抵达了 notebook 的底部,一个新的代码框会被自动创建出来。从 Jupyter 的 Help 菜单中的 User Interface Tour,可以学习 Jupyter 的基本操作。
图 2-4 在 notebook 中打印Hello world!
下载数据
一般情况下,数据是存储于关系型数据库(或其它常见数据库)中的多个表、文档、文件。要访问数据,你首先要有密码和登录权限,并要了解数据模式。但是在这个项目中,这一切要简单些:只要下载一个压缩文件,housing.tgz,它包含一个 CSV 文件housing.csv,含有所有数据。
你可以使用浏览器下载,运行tar xzf housing.tgz解压出csv文件,但是更好的办法是写一个小函数来做这件事。如果数据变动频繁,这么做是非常好的,因为可以让你写一个小脚本随时获取最新的数据(或者创建一个定时任务来做)。如果你想在多台机器上安装数据集,获取数据自动化也是非常好的。
下面是获取数据的函数:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
现在,当你调用fetch_housing_data(),就会在工作空间创建一个datasets/housing目录,下载housing.tgz文件,解压出housing.csv。
然后使用Pandas加载数据。还是用一个小函数来加载数据:
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
这个函数会返回一个包含所有数据的 Pandas DataFrame 对象。
快速查看数据结构
使用DataFrame的head()方法查看该数据集的前5行(见图 2-5)。
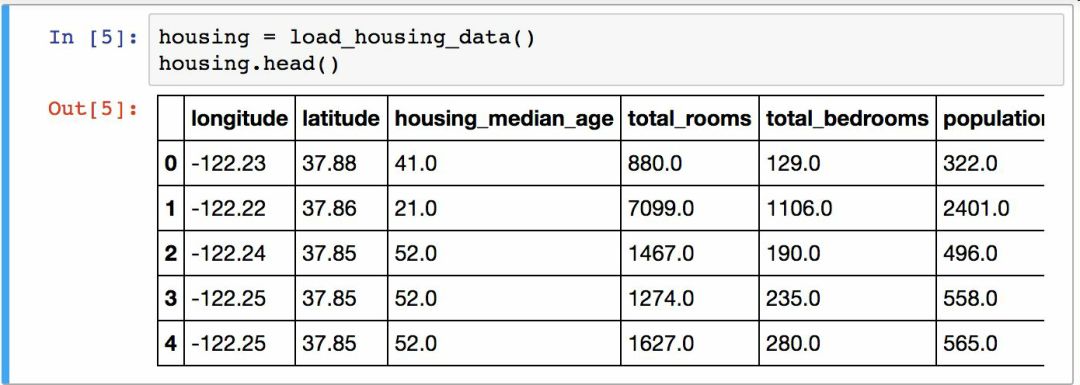
图 2-5 数据集的前五行
每一行都表示一个街区。共有 10 个属性(截图中可以看到 6 个):经度、维度、房屋年龄中位数、总房间数、总卧室数、人口数、家庭数、收入中位数、房屋价值中位数、离大海距离。
info()方法可以快速查看数据的描述,特别是总行数、每个属性的类型和非空值的数量(见图 2-6)。
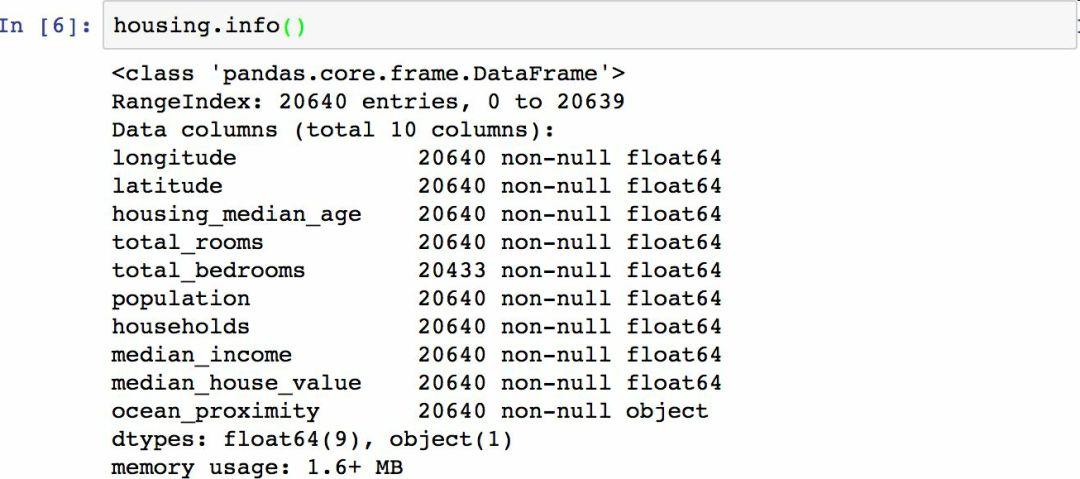
图 2-6 房屋信息
数据集**有 20640 个实例,按照机器学习的标准这个数据量很小,但是非常适合入门。我们注意到总房间数只有 20433 个非空值,这意味着有 207 个街区缺少这个值。我们将在后面对它进行处理。
所有的属性都是数值的,除了离大海距离这项。它的类型是对象,因此可以包含任意 Python 对象,但是因为该项是从 CSV 文件加载的,所以必然是文本类型。在刚才查看数据前五项时,你可能注意到那一列的值是重复的,意味着它可能是一项表示类别的属性。可以使用value_counts()方法查看该项中都有哪些类别,每个类别中都包含有多少个街区:
>>> housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
再来看其它字段。describe()方法展示了数值属性的概括(见图 2-7)。
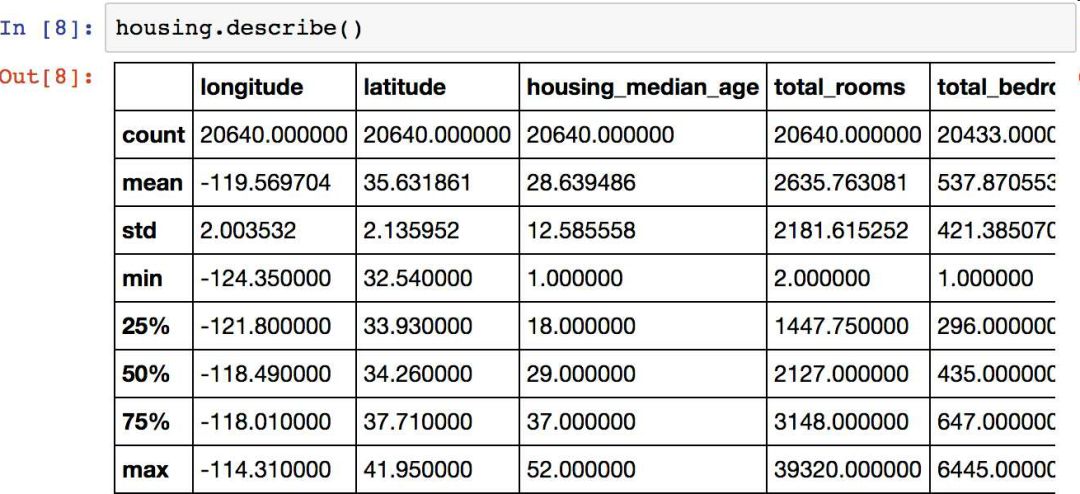
图 2-7 每个数值属性的概括
count、mean、min和max几行的意思很明显了。注意,空值被忽略了(所以,卧室总数是 20433 而不是 20640)。std是标准差(揭示数值的分散度)。25%、50%、75% 展示了对应的分位数:每个分位数指明小于这个值,且指定分组的百分比。例如,25% 的街区的房屋年龄中位数小于 18,而 50% 的小于 29,75% 的小于 37。这些值通常称为第 25 个百分位数(或第一个四分位数),中位数,第 75 个百分位数(第三个四分位数)。
另一种快速了解数据类型的方法是画出每个数值属性的柱状图。柱状图(的纵轴)展示了特定范围的实例的个数。你还可以一次给一个属性画图,或对完整数据集调用hist()方法,后者会画出每个数值属性的柱状图(见图 2-8)。例如,你可以看到略微超过 800 个街区的median_house_value值差不多等于 $500000。
%matplotlib inline # only in a Jupyter notebook
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
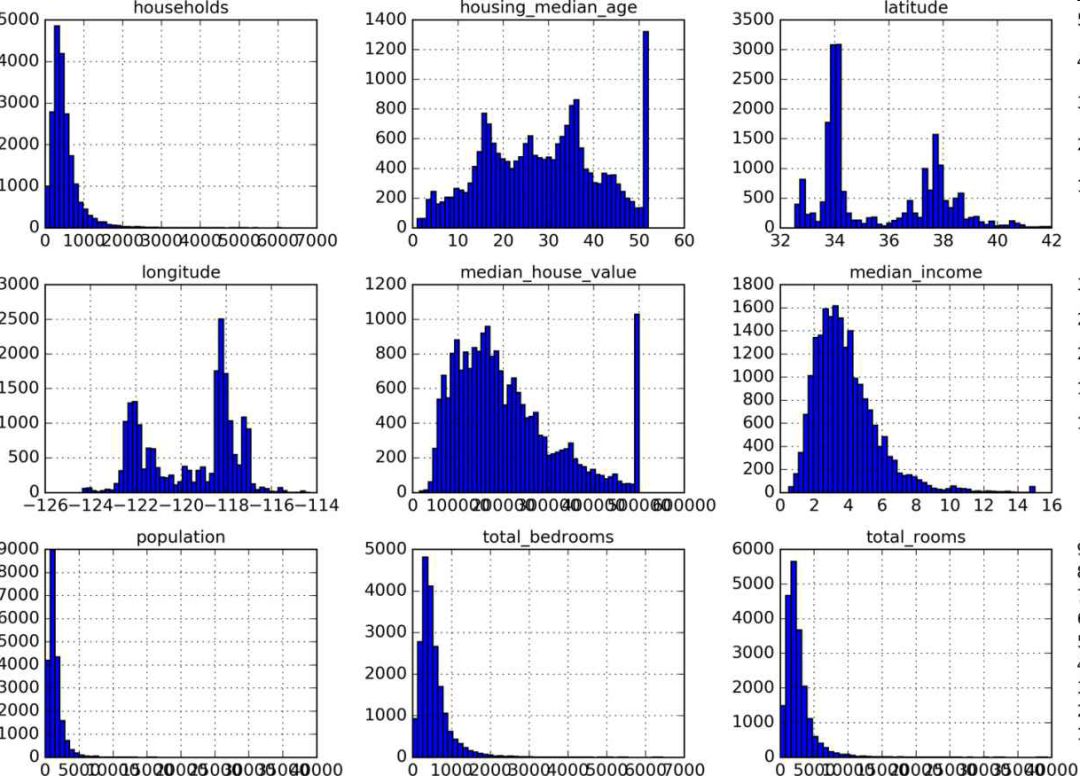
图 2-8 每个数值属性的柱状图
注:
hist()方法依赖于 Matplotlib,后者依赖于用户指定的图形后端以打印到屏幕上。因此在画图之前,你要指定 Matplotlib 要使用的后端。最简单的方法是使用 Jupyter 的魔术命令%matplotlib inline。它会告诉 Jupyter 设定好 Matplotlib,以使用 Jupyter 自己的后端。绘图就会在 notebook 中渲染了。注意在 Jupyter 中调用show()不是必要的,因为代码框执行后 Jupyter 会自动展示图像。
注意柱状图中的一些点:
首先,收入中位数貌似不是美元(USD)。与数据采集团队交流之后,你被告知数据是经过缩放调整的,过高收入中位数的会变为 15(实际为 15.0001),过低的会变为 5(实际为 0.4999)。在机器学习中对数据进行预处理很正常,这不一定是个问题,但你要明白数据是如何计算出来的。
房屋年龄中位数和房屋价值中位数也被设了上限。后者可能是个严重的问题,因为它是你的目标属性(你的标签)。你的机器学习算法可能学习到价格不会超出这个界限。你需要与下游团队核实,这是否会成为问题。如果他们告诉你他们需要明确的预测值,即使超过 $500000,你则有两个选项:
对于设了上限的标签,重新收集合适的标签;
将这些街区从训练集移除(也从测试集移除,因为若房价超出 $500000,你的系统就会被差评)。
这些属性值有不同的量度。我们会在本章后面讨论特征缩放。
最后,许多柱状图的尾巴很长:相较于左边,它们在中位数的右边延伸过远。对于某些机器学习算法,这会使检测规律变得更难些。我们会在后面尝试变换处理这些属性,使其变为正态分布希望你现在对要处理的数据有一定了解了。
警告:稍等!在你进一步查看数据之前,你需要创建一个测试集,将它放在一旁,千万不要再看它。