1.原理概述
序列学习其实是深度学习中的一个应用非常广泛的概念,例如语音识别、语言建模、机器翻译、机器作曲、机器写稿、自动对话、QA系统等都属于序列学习的领域,今天讲讲解如何运用序列建模的思想来构建一个端对端的机器翻译系统。
序列建模,顾名思义,处理的问题是有时序关联性的,因此这种情况下,普通的前馈式神经网络已经不适用这个问题了,取而代之的是具有循环记忆性的RNN网络,这里说的RNN是一种广泛的RNN概念,其内部记忆单元可以是原始的RNN或者是LSTM、GRU单元均可。由于RNN对于长时间建模问题表现没有LSTM好,因此本文中使用LSTM来建模。
通常来说,序列建模的输入数据长度与输出长度不一定相同。举个例子,就英汉机器翻译系统而言,英文中的“what's your name”是三个单词组成的序列,将它翻译成中文的话变成了“你叫什么名字”,它是六个汉字组成的序列,那么对于这种输入输出序列的长度是动态变化的情况,传统的RNN(或LSTM)建模显然是不行的,这个时候我们考虑的是把问题拆分为两个部分,即编码器和解码器,原因是,无论是汉语还是英语,两句话所对应的意义是一样的,那么当我们使用编码器对输入的英语序列进行特征编码,就相当于得到了这句话的意义,然后我们用汉语的解码器对这个意义进行解码并且用汉语的形式表达出来,这就得到了英译汉的结果。
具体来说,我们可以使用两个LSTM网络来分别作为编码和解码。编码的LSTM用来读取输入序列,每一时刻读取输入序列的一个单元,最终得到输入的特征编码分布;解码的LSTM根据特征编码分布从而得到解码输出。根据条件概率公式,我们可以得到下面的公式:
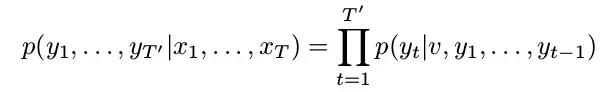
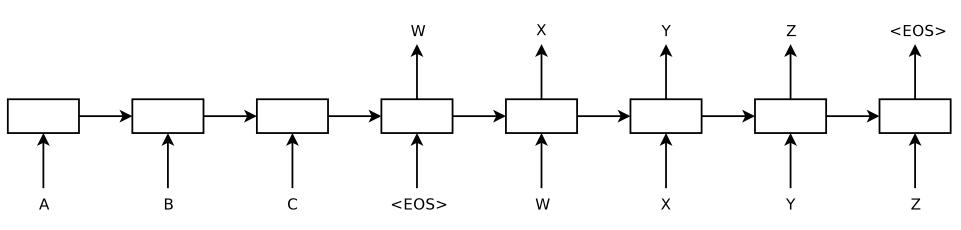
这里的x_1...x_T是输入序列,y_1...y_T'是输出序列,v是解码器的初始值x1...x_T,并且T和T'通常长度不一致。上式左边是我们需要求得的,而我们把它转换成右边的形式来计算,随后每一时刻解码器都会得到一个输出y_t,一直到输出<eos>即可停止解码。例如下图所示,这是一个由编码器输入ABC,再由解码器输出WXYZ的过程。
2.机器翻译实战
接下来我将讲解LSTM是如何具体在一个机器翻译系统中工作的,考虑如下一个英语-法语的翻译流程:
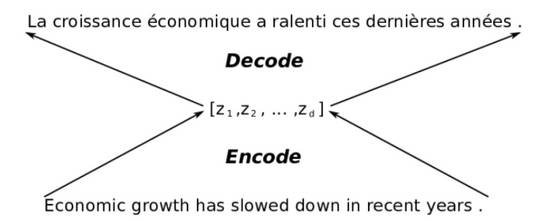
上图表示一个英-法翻译系统的结构,输入的是一句英语,经过机器翻译系统输出为一句法语。正如我们人脑翻译一句话一样,当我看到一句“what's your name”时,我的脑海中首先想的是它的具体含义,然后我才会根据这个含义,写出一句法语出来,这一思考流程正与上图中的编码和解码模块类似。
首先,我们大致浏览一下我们将要构建的基于LSTM的机器翻译系统,如下图所示,e是我们的一段待翻译英语句子,f是输出的翻译过后的法语句子。英语句子经过LSTM编码器得到特征表示,然后进入另一个LSTM解码器解码得到法语句子。这就是机器翻译系统的总体流程。
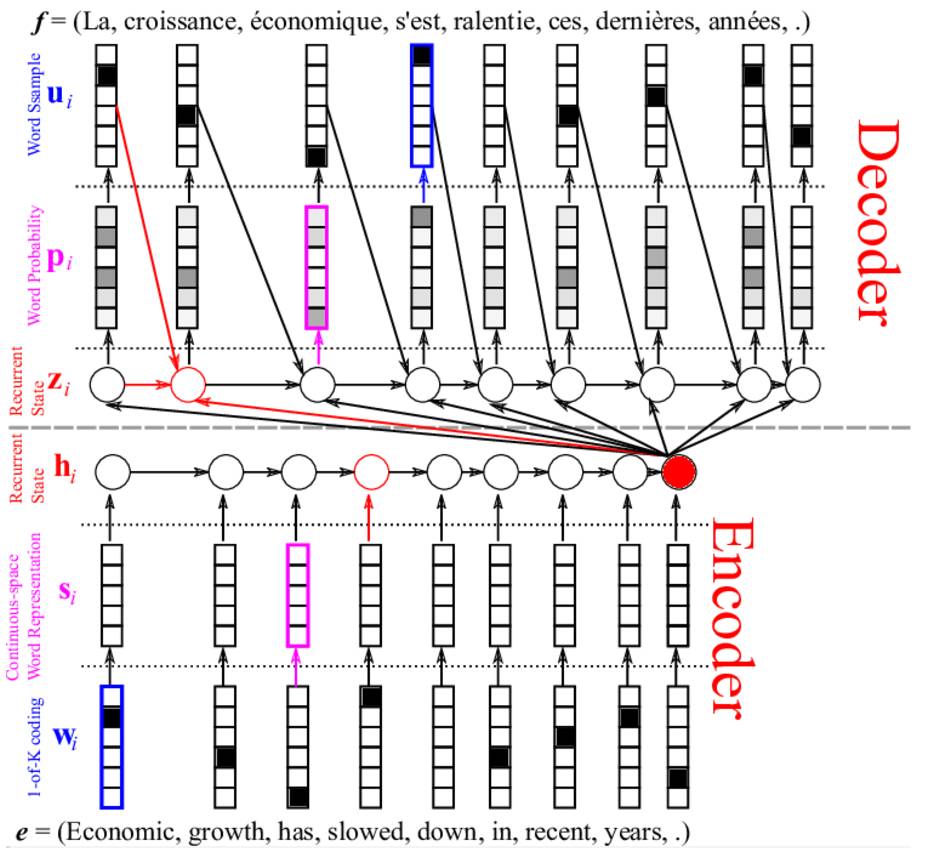
首先我们看下面的编码器部分,编码的过程如下:
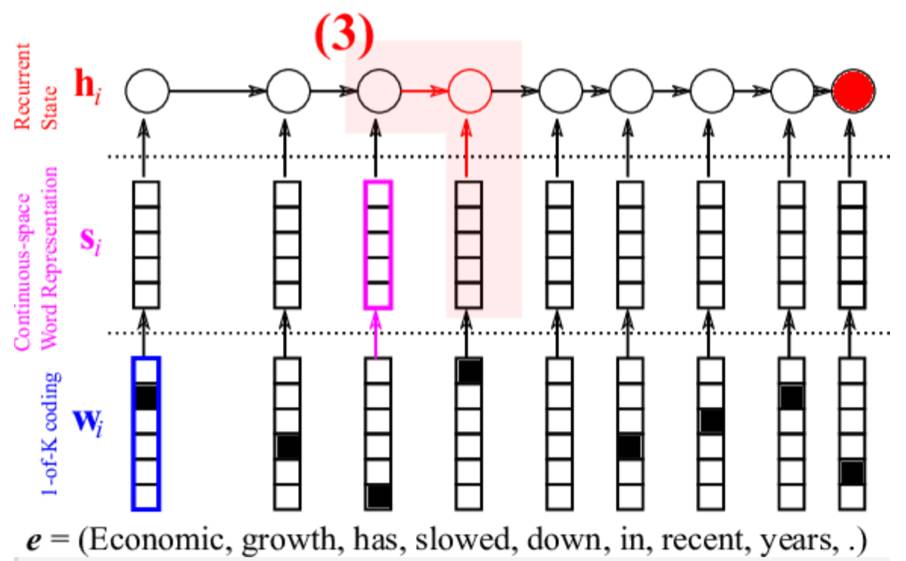
英语句子中的每个单词首先进行one-hot向量编码(蓝色部分)。这个很简单,假设有10000个单词,并且每个单词标记一个索引,如0,1,2,...9999,假如Economic所对应的索引为1,那么Economic单词的one-hot编码后的向量为(0,1,0,0,...,0)。这个编码虽然简单,但是只是编码的第一步,原因是这个编码并没有存储单词之间的关联性;
每个单词进行二次编码(粉红色部分)。我们需要用一个向量来表示整句话,但是在得到这个向量之前,我们还需要对每个单词进行二次编码,这次编码的目的是要让其更有意义,不是简单的one-hot编码了,那么如何得到这种更有意义的编码呢?在上图的蓝色部分与红色部分连接一个权重W,这个W的维度应该是单词数量×特征大小,当然特征大小你可以自己定义,如100或200都可以。并且,这个W的值需要由网络不断更新从而自我学习,其更新的目的就是要使得该机器翻译系统性能越来越好;
经LSTM得到整句话的编码向量(红色循环层)。由第2步我们已经得到了每个单词的特征向量s,接下来就是把这些特征向量s按照时间先后顺序依次输入到LSTM隐含层,这里假设有个h_0是一个所有元素随机初始化为0的向量,于是,由s_1和h_0即可得到h_1,由h_1和s_2即可得到h_2,以此类推,直到由h_T-1和s_T得到了h_T,编码结束。那么这个h_T我们认为就是整个英语句子的特征向量表示。
得到了每句话的特征表示,我们不禁会想这个特征表示到底是什么样的?虽然是高维的特征,但是不同句子的特征表示是否有关联呢?有研究者在训练好了一个机器翻译系统之后,就将一些句子的特征向量保存了下来并做了主成分分析(PCA),将其降维到了2-D空间,如下图所示:
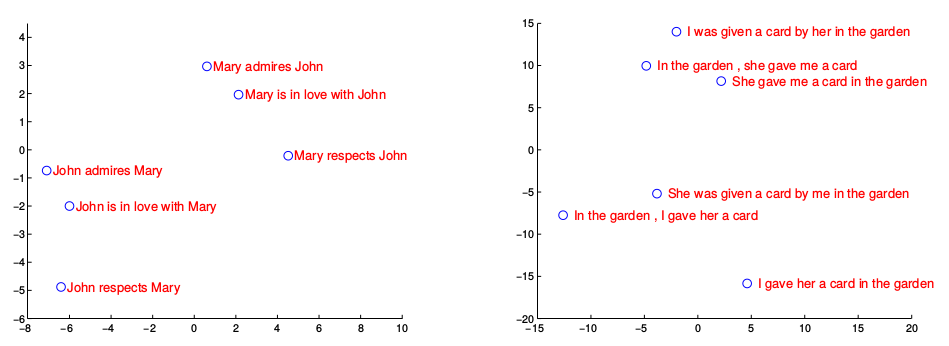
从上图可以看出,句子的特征向量确实可以反映句子之间的关联,例如,相似的句子在上图中靠的很近。
接下来看解码部分,根据输入句子的向量即可得到进行解码操作,具体流程如下:
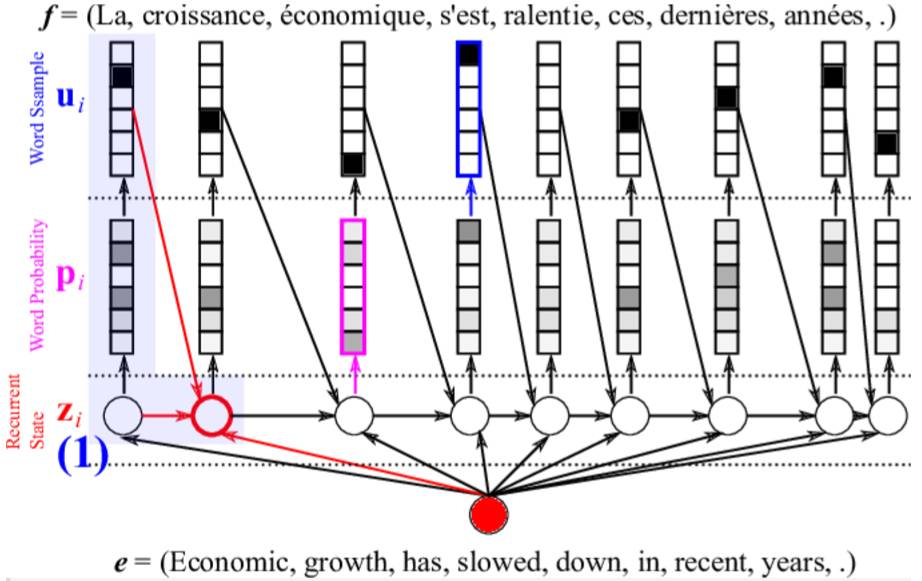
将句子编码h_T作为输入传到解码LSTM中,对于解码LSTM而言,其隐含层状态z_i是由句子编码h_T、前一个输出单词u_i-1、前一隐含状态z_i-1共同决定的,即z_i=f(h_T,u_i-1,z_i-1),这里需要初始化一些量,例如t=0时刻的隐含层状态以及单词;
计算每个时刻的输出单词的概率分布。首先需要对z_i加一个前馈层,从而可以得到一个和字典单词数量一致的向量,然后使用softmax函数即可确定每个单词的概率。然后,依据单词概率进行抽样即可确定此刻的最终单词输出。
将上一时刻的单词输出以及上一时刻的隐含层状态,重复第2步计算,得到下一个输出的单词,直到<eos>出现为止,停止解码操作。
构建好了编码LSTM和解码LSTM以后,接下来就是如何训练这个网络了。假设我们的训练数据集是由很多(X,Y)构成的,X_i是英语句子,Y_i是对应的法语句子。我们可以由机器翻译网络得到P(Y_i|X_i)的值,那么借助EM算法的思想,我们要构建它的负对数似然的形式,即
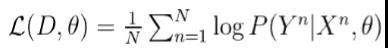
这里的N是训练对的大小,然后按照常规的梯度下降算法即可训练这个机器翻译网络。
总结:
机器翻译时,将输入句子中的单词顺序颠倒一下可以提高机器翻译的性能,这可能是因为减小了源句与翻译后的句子的对应词语之间的距离;
本文是序列建模的一个最简单的例子,如果要提升机器翻译系统的性能,可以考虑假如注意力机制,注意力机制简而言之是可以让解码器更多地关注某个单词。
序列学习是一个非常广泛的概念,我们可以将此应用到机器写稿、句子语法分析、机器看图说话等领域。




