这篇分析一下以太坊数据存储相关的流程。
首先介绍一下MPT的存储流程,然后依次分析StateDB、Transactions、Receipts的存储,这3棵树的Merkle Root最终会存储到区块Header中的Root、TxHash、ReceiptHash字段。
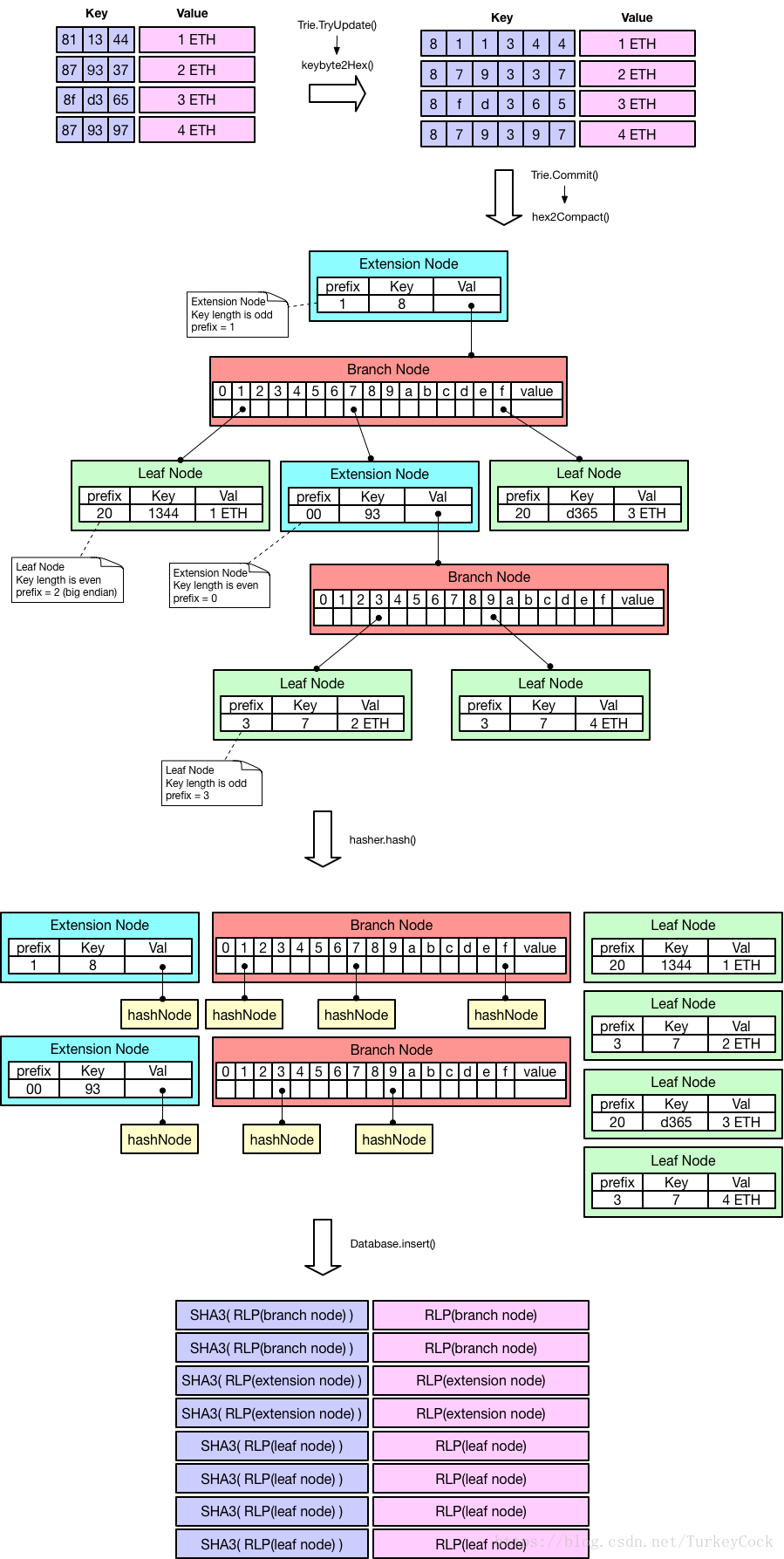
从图中可以看出,MPT的存储涉及3种编码方式:
在完成Compact编码后,会通过折叠操作把子结点替换成子结点的hash值,然后以键值对的形式将所有结点存储到数据库中。下面详细介绍上面3中编码方式。
即原始关键字,比如图中的0x811344、0x879337等。每个字节中包含2个nibble(半字节,4 bits),每个nibble的数值范围时0x0~0xF。
由于我们需要以nibble为单位进行编码并插入MPT,因此需要把一个字节拆分成两个,转换为Hex编码。
编码转换是在Trie.TryUpdate()中触发的,具体转换代码参见trie/encoding.go:
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}
当我们需要把内存中MPT存储到数据库中时,还需要再把两个字节合并为一个字节进行存储,这时候会碰到2个问题:
编码转换是在Trie.Commit()时触发的,具体调用在hasher.hashChildren()函数中,转换代码参见trie/encoding.go:
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1]
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 {
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}
StateDB中存储了很多stateObject,而每一个stateObject则代表了一个以太坊账户,包含了账户的地址、余额、nonce、合约代码hash等状态信息。所有账户的当前状态在以太坊中被称为“世界状态”,在每次挖出或者接收到新区块时需要更新世界状态。
为了能够快速检索和更新账户状态,StateDB采用了两级缓存机制,参见下图:
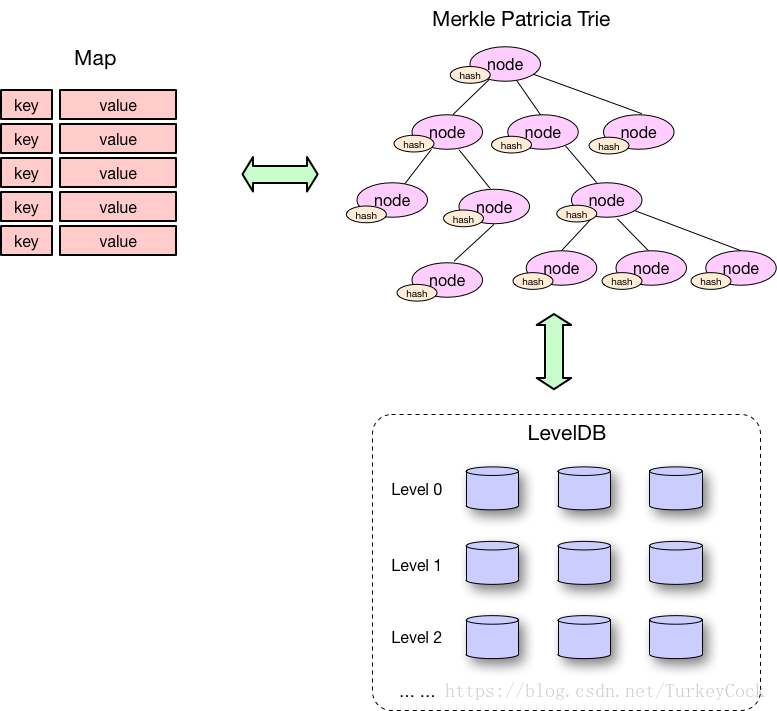
当上一级缓存中没有所需的数据时,会从下一级缓存或者数据库中进行加载。
我们可以看一下StateDB具体实现的UML图:
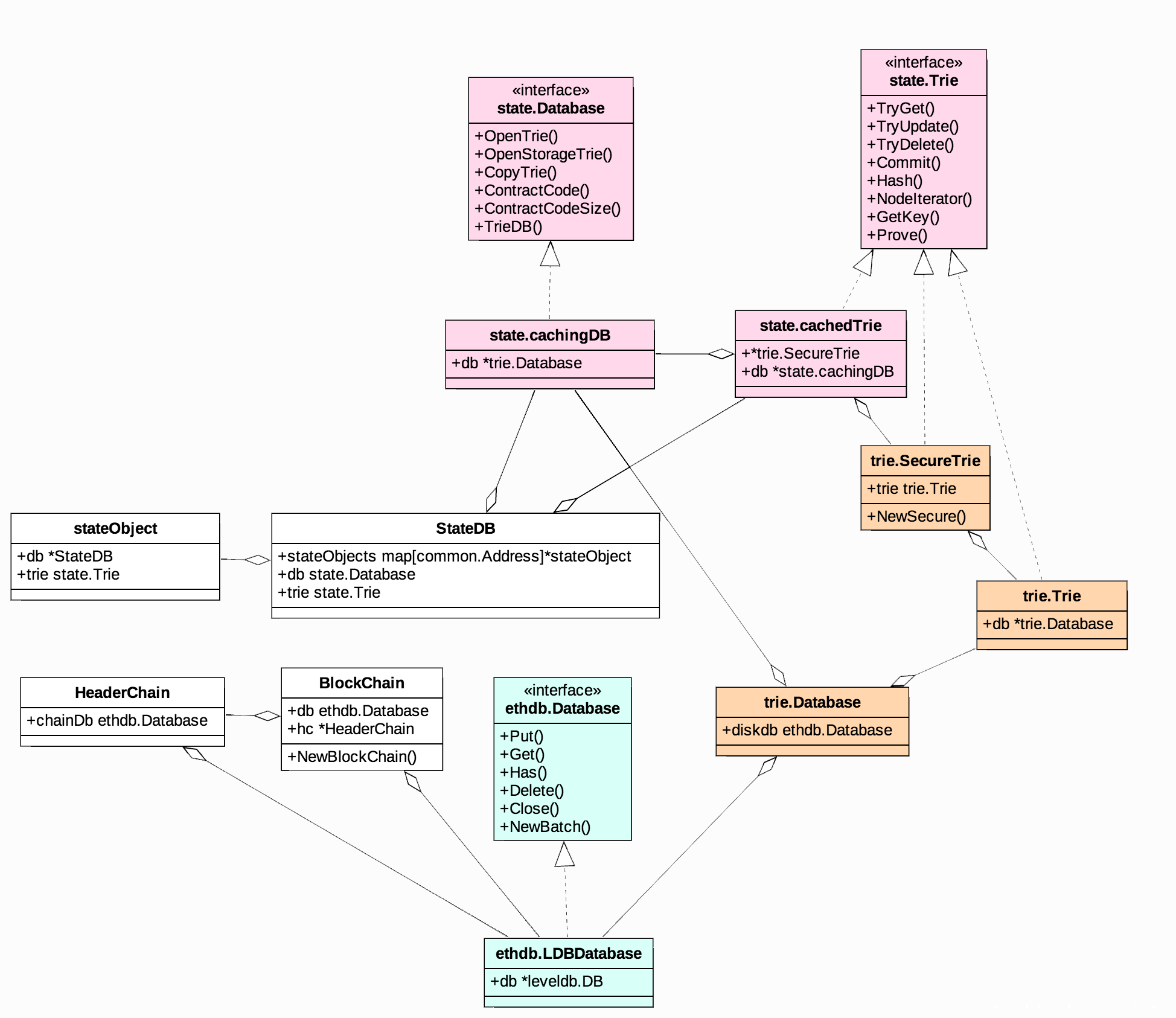
可以看到,一共封装了3个包:state,trie,ethdb。如果按接口类型来分,主要分为Trie和Database两种接口。Trie接口主要用于操作内存中的MPT,而Database接口主要用于操作LevelDB,做持久化存储。StateDB中同时包含了这两种接口。
查看StateDB和stateObject的定义可以发现,这两种类型内部各有一个Trie,那么这两个Trie里存储的什么内容呢?请看下图:
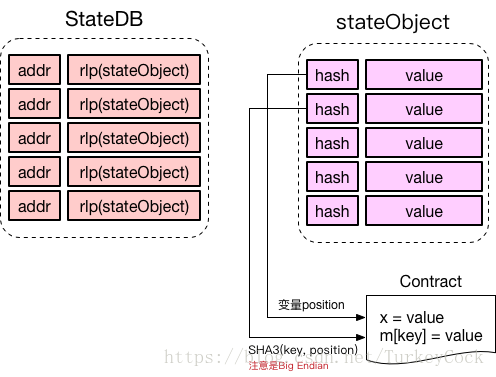
StateDB里的Trie以账户地址为key,存储经过RLP编码后的stateObject。
stateObject里的Trie也被称为storage trie,存储的是智能合约执行后修改的变量值,细节可以参见之前的一篇文章:以太坊stateObject中Storage存储内容的探究
这两个Trie是怎么关联起来的呢?实际上stateObject内部有一个Account类型的字段,我们看一下它的类型定义:
type Account struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}
看到了吧,Account类型内部有一个Root字段,记录的正是对应的storage trie的merkle root。
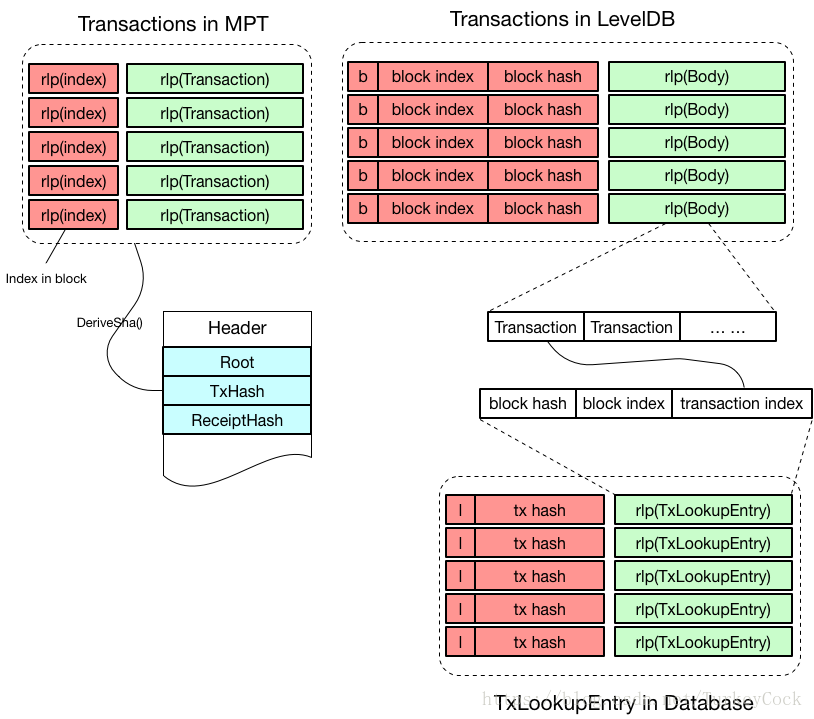
从图中可以看出,MPT中是以交易在区块中的索引的RLP编码作为key,存储交易数据的RLP编码。
事实上交易在LeveDB中并不是单独存储的,而是存储在区块的Body中。在往LeveDB中存储不同类型的键值对时,会在关键字中添加不同的前缀予以区分,这些前缀的定义在core/rawdb/schema.go中:
// Data item prefixes (use single byte to avoid mixing data types, avoid `i`, used for indexes).
headerPrefix = []byte("h") // headerPrefix + num (uint64 big endian) + hash -> header
headerTDSuffix = []byte("t") // headerPrefix + num (uint64 big endian) + hash + headerTDSuffix -> td
headerHashSuffix = []byte("n") // headerPrefix + num (uint64 big endian) + headerHashSuffix -> hash
headerNumberPrefix = []byte("H") // headerNumberPrefix + hash -> num (uint64 big endian)
blockBodyPrefix = []byte("b") // blockBodyPrefix + num (uint64 big endian) + hash -> block body
blockReceiptsPrefix = []byte("r") // blockReceiptsPrefix + num (uint64 big endian) + hash -> block receipts
txLookupPrefix = []byte("l") // txLookupPrefix + hash -> transaction/receipt lookup metadata
bloomBitsPrefix = []byte("B") // bloomBitsPrefix + bit (uint16 big endian) + section (uint64 big endian) + hash -> bloom bits
preimagePrefix = []byte("secure-key-") // preimagePrefix + hash -> preimage
configPrefix = []byte("ethereum-config-") // config prefix for the db
因此,以b + block index + block hash作为关键字就可以唯一确定某个区块的Body所在的位置。
另外,为了能够快速查询某笔交易的数据,在数据库中还存储了每笔交易的索引信息,称为TxLookupEntry。TxLookupEntry中包含了block index和block hash用于定位区块Body,同时还包含了该笔交易在区块Body中的索引位置。
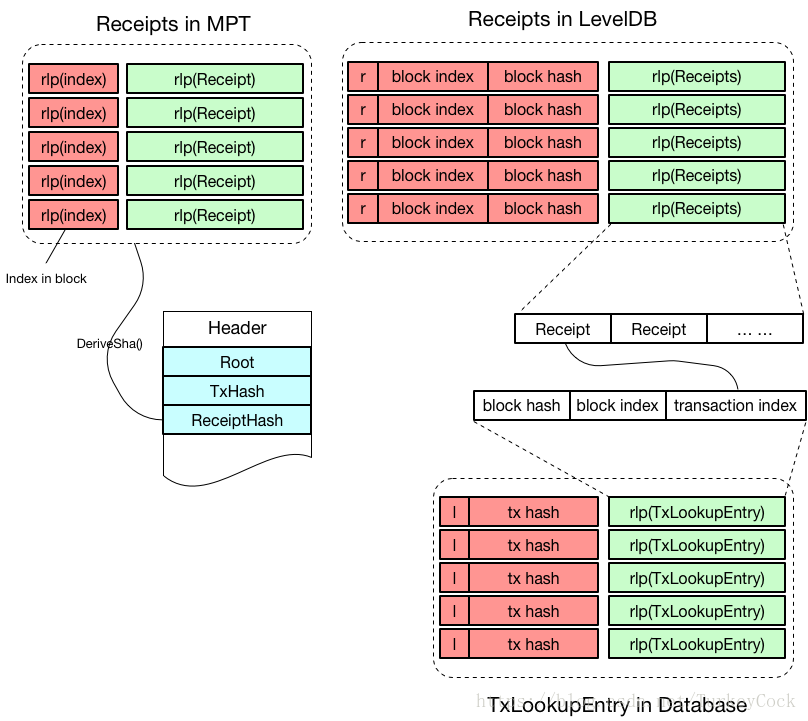
交易回执的存储和交易类似,区别是交易回执是单独存储到LevelDB中的,以r为前缀。
另外,由于交易回执和交易是一一对应的,因此也可以通过TxLookupEntry快速定位交易回执所在的位置,加速交易回执的查找。
延伸阅读:以太坊挖矿源码分析